Concepts des ensembles de compétences dans Recherche Azure AI
Cet article s’adresse aux développeurs qui ont besoin de comprendre plus en profondeur les concepts et la composition des ensembles de compétences. Il suppose une bonne connaissance des concepts généraux de l’IA appliquée dans Recherche Azure AI.
Un ensemble de compétences est un objet réutilisable dans Recherche Azure AI, qui est attachée à un indexeur. Il contient une ou plusieurs compétences, qui appellent l’IA intégrée ou un traitement personnalisé externe sur les documents récupérés à partir d’une source de données externe.
Le diagramme suivant illustre le flux de données de base de l’exécution d’un ensemble de compétences.
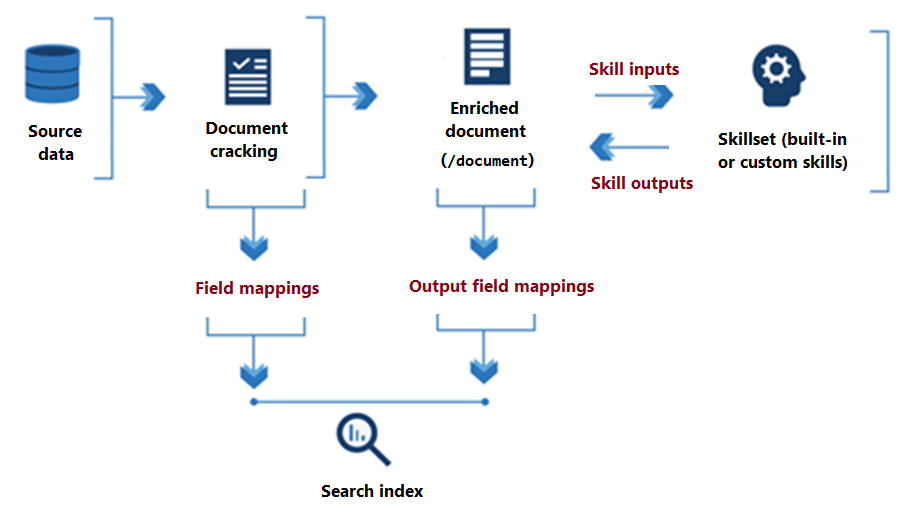
Du début à la fin du traitement de l’ensemble de compétences, les compétences effectuent des opérations de lecture et d’écriture dans un document enrichi qui existe dans la mémoire. Initialement, un document enrichi correspond simplement au contenu brut extrait d’une source de données (articulé en tant que nœud racine "/document"). À chaque exécution d’une compétence, le document enrichi gagne en structure et en substance, car chaque compétence écrit sa sortie sous forme de nœuds dans le graphe.
Une fois l’exécution de l’ensemble de compétences effectuée, la sortie d’un document enrichi se retrouve dans un index par le biais de mappages de champs de sortie définis par l’utilisateur. Tout contenu brut que vous voulez transférer intact, de la source à un index, est défini par le biais de mappages de champs.
Pour configurer l’IA appliquée, spécifiez les paramètres d’un ensemble de compétences et d’un indexeur.
Définition du jeu de compétences
Un ensemble de compétences est un tableau d’une ou plusieurs compétences qui effectuent un enrichissement, comme la traduction de texte ou la reconnaissance optique de caractères (OCR) sur un fichier image. Les compétences peuvent être des compétences intégrées provenant de Microsoft, ou des compétences personnalisées pour la logique de traitement que vous hébergez en externe. Un ensemble de compétences produit des documents enrichis qui sont soit consommés pendant l’indexation, soit projetés vers une base de connaissances.
Les compétences ont un contexte, des entrées et des sorties :
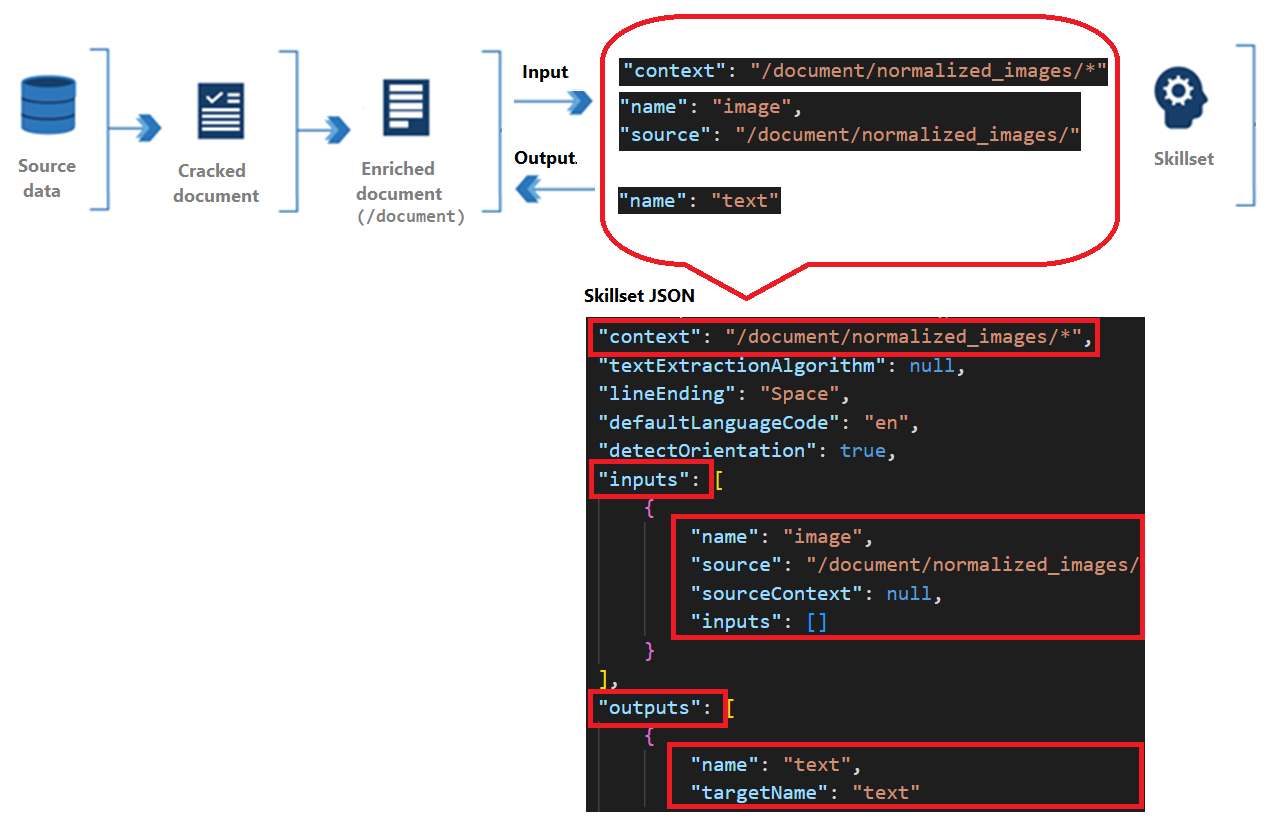
Le contexte fait référence à l’étendue de l’opération, qui peut être une fois par document ou une fois pour chaque élément d’une collection.
Les entrées proviennent de nœuds dans un document enrichi, où une « source » et un « nom » identifient un nœud donné.
La sortie est renvoyée au document enrichi sous forme de nouveau nœud. Les valeurs sont le « nom » du nœud et son contenu. En cas de nom de nœud en double, vous pouvez définir un nom cible à des fins de clarification.
Contexte d’une compétence
Chaque compétence a un contexte, lequel peut correspondre à l’ensemble du document (/document) ou à un nœud situé plus bas dans l’arborescence (/document/countries/*).
Un contexte détermine :
Le nombre de fois que la compétence s'exécute, pour une seule valeur (une fois par champ, par document), ou pour une collection, où l'ajout d'un
/*entraîne l'invocation de la compétence pour chaque instance de la collection.Déclaration de sortie, ou emplacement d’ajout des sorties de compétence dans l’arborescence d’enrichissement. Les sorties sont toujours ajoutées à l’arborescence en tant qu’enfants du nœud de contexte.
La forme des entrées. Pour les collections multiniveaux, la définition du contexte sur la collection parente affecte la modélisation de l’entrée de la compétence. Par exemple, si vous avez une arborescence d’enrichissement avec une liste de pays/régions, chacun/chacune enrichi(e) d’une liste d’états contenant une liste de codes postaux, la façon dont vous définissez le contexte détermine la façon dont l’entrée est interprétée.
Context Entrée Forme de l’entrée Appel de compétence /document/countries/*/document/countries/*/states/*/zipcodes/*Liste de tous les codes postaux du pays/de la région Une fois par pays/région /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Liste de tous les codes postaux de l’état Une fois par combinaison pays/région et État
Dépendances d’une compétence
Les compétences peuvent s’exécuter indépendamment et en parallèle, ou successivement si vous alimentez la sortie d’une compétence dans une autre compétence. L’exemple suivant illustre deux compétences intégrées qui s’exécutent dans l’ordre :
La compétence n° 1 est la compétence Fractionnement de texte. Elle accepte le contenu du champ source « reviews_text » en tant qu’entrée, et divise ce contenu en « pages » de 5 000 caractères en tant que sortie. Le fractionnement d’un texte volumineux en blocs plus petits permet de produire de meilleurs résultats pour les compétences comme la détection des sentiments.
La compétence 2 est une compétence de détection des sentiments qui accepte « pages » comme entrée et génère un nouveau champ appelé « Sentiment » qui contient les résultats de l’analyse des sentiments.
Notez que la sortie de la première compétence (« pages ») est utilisée dans l’analyse des sentiments, où « document/reviews_text/pages/* » est à la fois le contexte et l’entrée. Pour plus d’informations sur la formulation de chemin d’accès, consultez Comment référencer les enrichissements.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Arborescence d’enrichissements
Un document enrichi est une structure de données temporaire sous forme d’arborescence, créée au moment de l’exécution de l’ensemble de compétences. Cette structure collecte tous les changements introduits par les compétences. Collectivement, les enrichissements sont représentés dans une hiérarchie de nœuds adressables. Les nœuds incluent également les champs non enrichis passés en l’état à partir de la source de données externe.
Un document enrichi existe pendant la durée de l’exécution de l’ensemble de compétences, mais il peut être mis en cache ou envoyé à une base de connaissances.
Au départ, un document enrichi correspond simplement au contenu extrait d’une source de données durant le craquage de document, où le texte et les images sont extraits de la source à des fins d’analyse du langage ou des images.
Le contenu initial correspond aux métadonnées et au nœud racine (document/content). Le nœud racine correspond généralement à un document entier ou à une image normalisée extraite d’une source de données lors du craquage de document. La façon dont il est articulé dans une arborescence d’enrichissement varie pour chaque type de source de données. Le tableau suivant montre l’état d’un document entrant dans le pipeline d’enrichissement pour plusieurs sources de données prises en charge :
| Data Source\Parsing Mode | Par défaut | JSON, JSON Lines & CSV |
|---|---|---|
| Stockage Blob | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
N/A |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
N/A |
Au fur et à mesure de l’exécution des compétences, la sortie est ajoutée à l’arborescence d’enrichissement sous forme de nouveaux nœuds. Si l’exécution d’une compétence se produit sur le document entier, des nœuds sont ajoutés au premier niveau sous la racine.
Les nœuds peuvent être utilisés comme entrées pour les compétences en aval. Par exemple, les compétences qui créent du contenu, comme des chaînes traduites, peuvent devenir des entrées pour des compétences qui reconnaissent des entités ou extraient des expressions clés.
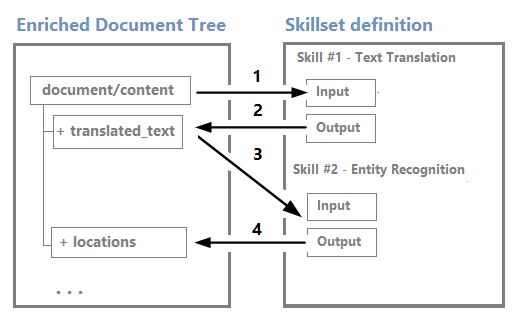
Bien que vous puissiez visualiser et utiliser une arborescence d’enrichissement par le biais d’un éditeur visuel Sessions de débogage, il s’agit principalement d’une structure interne.
Les enrichissements ne sont pas immuables : une fois créés, les nœuds ne peuvent pas être modifiés. Plus votre ensemble de compétences est complexe, plus votre arborescence d’enrichissements l’est aussi. Toutefois, vous n’avez pas besoin d’inclure systématiquement tous les nœuds de l’arborescence d’enrichissements dans l’index ou la base de connaissances.
Vous pouvez conserver de manière sélective uniquement un sous-ensemble des sorties d’enrichissement pour ne garder que ce que vous comptez utiliser. Les mappages de champs de sortie dans votre définition d’indexeur déterminent le contenu réellement ingéré dans l’index de recherche. De même, si vous créez une base de connaissances, vous pouvez mapper les sorties à des modélisations affectées à des projections.
Remarque
Le format de l’arborescence d’enrichissement permet au pipeline d’enrichissement d’attacher les métadonnées même aux types de données primitifs. Les métadonnées ne représentent pas un objet JSON valide. Toutefois, elles peuvent être projetées vers un format JSON valide dans les définitions de projection d’une base de connaissances. Pour plus d’informations, consultez Compétence Modélisateur.
Définition de l’indexeur
Un indexeur a des propriétés et des paramètres utilisés pour configurer son exécution. Parmi ces propriétés figurent des mappages qui définissent le chemin des données vers les champs d’un index de recherche.

Il existe deux ensembles de mappages :
« fieldMappings » mappe un champ source à un champ de recherche.
« outputFieldMappings » mappe un nœud dans un document enrichi à un champ de recherche.
La propriété « sourceFieldName » spécifie un champ dans votre source de données ou un nœud dans une arborescence d’enrichissement. La propriété « targetFieldName » spécifie le champ de recherche dans un index qui reçoit le contenu.
Exemple d’enrichissement
En prenant l’ensemble de compétences relatif aux avis sur les hôtels comme point de référence, cet exemple explique comment une arborescence d’enrichissement évolue via l’exécution des compétences à l’aide de diagrammes conceptuels.
Cet exemple montre également que :
- Le contexte et les entrées d’une compétence déterminent le nombre d’exécutions de celle-ci
- Le contexte affecte la forme de l’entrée.
Dans cet exemple, les champs sources d’un fichier CSV incluent les avis des clients sur les hôtels (« reviews_text ») et les évaluations (« reviews_rating »). L’indexeur ajoute les champs de métadonnées à partir de Stockage Blob, alors que les compétences ajoutent le texte traduit, les scores de sentiments et la détection de phrases clés.
Dans l’exemple des avis sur les hôtels, un « document » situé dans le processus d’enrichissement représente un seul avis sur un hôtel.
Conseil
Vous pouvez créer un index de recherche et une base de connaissances pour ces données dans le Portail Azure ou via les API REST. Vous pouvez également utiliser les sessions de débogage pour obtenir des insights sur la composition des ensembles de compétences, les dépendances et les effets sur une arborescence d’enrichissement. Les images de cet article sont extraites de sessions de débogage.
D’un point de vue conceptuel, l’arborescence d’enrichissement initiale se présente comme suit :

Le nœud racine de tous les enrichissements est "/document". Quand vous utilisez des indexeurs d’objets blob, le nœud "/document" contient les nœuds enfants "/document/content" et "/document/normalized_images". Quand les données sont au format CSV, comme dans cet exemple, les noms de colonne sont mappés aux nœuds figurant sous "/document".
Compétence #1 : compétence de fractionnement
Lorsque le contenu source est constitué de gros blocs de texte, il est utile de le diviser en plus petits composants pour plus de précision dans la détection de la langue, du sentiment et des expressions clés. Deux grains sont disponibles : les pages et les phrases. Une page se compose d’environ 5 000 caractères.
La compétence de fractionnement de texte se trouve généralement d’abord dans un ensemble de compétences.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Avec le contexte de compétence "/document/reviews_text", la compétence de division s’exécute une seule fois pour reviews_text. La sortie de la compétence est une liste où reviews_text est segmenté en 5 000 séquences de caractères. La sortie de la compétence de division est nommée pages et ajoutée à l’arborescence d’enrichissements. Avec targetName, vous pouvez renommer une sortie de compétence avant de l’ajouter à l’arborescence d’enrichissements.
L’arborescence d’enrichissements comporte maintenant un nouveau nœud, situé sous le contexte de la compétence. Ce nœud peut être utilisé pour d’autres compétences, projections ou mappages de champs de sortie.

Pour accéder à un enrichissement qui a été ajouté à un nœud par une compétence, vous devez indiquer le chemin complet de l’enrichissement. Par exemple, si vous souhaitez utiliser le texte du nœud pages comme entrée dans une autre compétence, spécifiez le chemin de cette façon : "/document/reviews_text/pages/*". Pour plus d’informations sur les chemins d’accès, consultez Enrichissements de référence.
Compétence n° 2 : Détection de la langue
Les documents d’avis sur les hôtels comprennent des commentaires clients exprimés en plusieurs langues. La compétence de détection de langue détermine la langue utilisée. Le résultat est ensuite passé à l’extraction de phrases clés et à la détection de sentiments (hors illustration), en tenant compte de la langue au moment de la détection des sentiments et des phrases.
La compétence de détection de la langue est la troisième compétence (compétence n° 3) définie dans l’ensemble de compétences, mais c’est la compétence suivante à exécuter. Elle ne nécessite aucune entrée, donc elle peut s’exécuter en parallèle avec la compétence précédente. À l’instar de la compétence de division qui l’a précédée, la compétence de détection de la langue est également appelée une fois pour chaque document. L’arborescence d’enrichissements comporte désormais un nouveau nœud pour la langue.

Compétences n°3 et n°4 : Analyse des sentiments et détection de phrases clés
Les commentaires des clients reflètent un éventail d’expériences positives et négatives. La compétence d’analyse des sentiments analyse les commentaires et affecte un score parmi un continuum de nombres négatifs à positifs, ou une valeur neutre si le sentiment est indéterminé. Parallèlement à l’analyse des sentiments, la détection de phrases clés identifie et extrait les mots ainsi que les phrases courtes qui semblent importants.
Compte tenu du contexte de /document/reviews_text/pages/*, les compétences d’analyse des sentiments et des phrases clés sont appelées une seule fois pour chacun des éléments de la collection pages. La sortie de la compétence est un nœud placé sous l’élément page associé.
Vous pouvez maintenant examiner le reste des compétences dans l’ensemble de compétences et regarder comment l’arborescence des enrichissements continue de croître à l’exécution de chaque compétence. Certaines compétences, telles que la compétence de fusion et la compétence de modélisation, créent également des nœuds, mais utilisent uniquement les données de nœuds existants et ne créent pas d’enrichissements supplémentaires.

Les couleurs des connecteurs dans l’arborescence ci-dessus indiquent que les enrichissements ont été créés par différentes compétences, c’est-à-dire que les nœuds doivent être traités individuellement et qu’ils ne feront pas partie de l’objet retourné lors de la sélection du nœud parent.
Compétence n°5 : Compétence Modélisateur
Si la sortie comprend une base de connaissances, ajoutez une compétence Modélisateur en tant que dernière étape. La compétence Modélisateur crée des modélisations de données à partir de nœuds dans une arborescence d’enrichissement. Par exemple, vous pouvez être amené à regrouper plusieurs nœuds en une seule modélisation. Vous pouvez ensuite projeter cette modélisation sous forme de table (les nœuds deviennent les colonnes d’une table), en passant la modélisation par son nom à une projection de table.
Il est facile d’utiliser la compétence Modélisateur, car elle se concentre sur la modélisation à travers une seule compétence. Vous pouvez également opter pour une modélisation inline au sein de projections individuelles. La compétence Modélisateur n’ajoute ou n’enlève rien à une arborescence d’enrichissements, elle n’est donc pas visualisée. À la place, vous pouvez considérer la compétence Modélisateur comme un moyen de réorganiser l’arborescence d’enrichissements dont vous disposez déjà. Sur le plan conceptuel, cela s’apparente à la création de vues à partir de tables d’une base de données.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Étapes suivantes
En vous appuyant sur cette introduction et un exemple, essayez de créer votre premier ensemble de compétences à l’aide des compétences intégrées.