Tutoriel : indexer des objets blob JSON imbriqués à partir du Stockage Azure à l’aide de REST
La recherche Azure AI peut indexer des tableaux et documents JSON dans le Stockage Blob Azure à l’aide d’un indexeur qui sait comment lire des données semi-structurées. Les données semi-structurées contiennent des balises ou des marquages qui séparent le contenu au sein des données. Il fait la distinction entre les données non structurées, qui doivent être entièrement indexées, et les données formellement structurées qui adhèrent à un modèle de données, tel qu’un schéma de base de données relationnelle, et qui peuvent être indexées par champ.
Ce tutoriel vous montre comment indexer des tableaux JSON imbriqués. Il utilise un client REST et les API REST de Recherche pour effectuer les tâches suivantes :
- Configurer des exemples de données et configurer une source de données
azureblob - Créer un index de recherche Azure AI où stocker le contenu de recherche
- Créer et exécuter un indexeur pour lire le conteneur et extraire le contenu de recherche
- Effectuer une recherche dans l’index que vous venez de créer
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Visual Studio Code avec un client REST.
Recherche Azure AI. Créez ou recherchez une ressource Recherche Azure AI existante sous votre abonnement actuel.
Remarque
Vous pouvez utiliser le service gratuit pour ce tutoriel. Avec un service de recherche gratuit, vous êtes limité à trois index, trois indexeurs et trois sources de données. Ce didacticiel crée une occurrence de chaque élément. Avant de commencer, veillez à disposer de l’espace suffisant sur votre service pour accepter les nouvelles ressources.
Télécharger les fichiers
Téléchargez un fichier zip du référentiel des exemples de données et extrayez le contenu. Découvrez comment.
L’exemple de données est un fichier JSON unique contenant un tableau JSON et 1 521 éléments JSON imbriqués. Les exemples de données proviennent de l’historique des performances de l’Orchestre philharmonique de New York sur Kaggle. Nous avons choisi un fichier JSON afin de rester sous les limites de stockage du niveau gratuit.
Voici le premier JSON imbriqué dans le fichier. Le reste du fichier comprend 1 520 autres instances de concerts.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Charger des exemples de données dans Stockage Azure
Dans Stockage Azure, créez un conteneur et nommez-le ny-philharmonic-free.
Obtenez une chaîne de connexion de stockage pour pouvoir formuler une connexion dans Recherche Azure AI.
À gauche, sélectionnez Clés d’accès.
Copiez la chaîne de connexion pour la clé un ou la clé deux. La chaîne de connexion est similaire à l’exemple suivant :
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Copier l’URL et la clé API d’un service de recherche
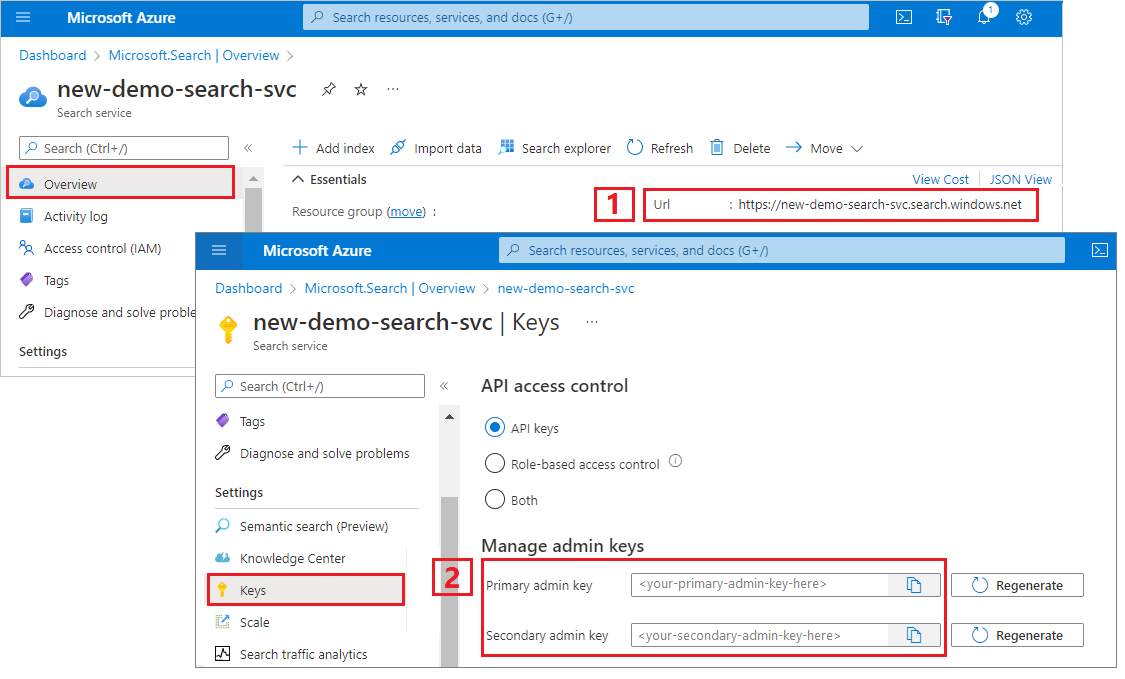
Pour ce tutoriel, les connexions à Recherche Azure AI nécessitent un point de terminaison et une clé API. Vous pouvez obtenir ces valeurs à partir du Portail Azure.
Connectez-vous au Portail Azure, accédez à la page Vue d’ensemble du service de recherche et copiez l’URL. Voici un exemple de point de terminaison :
https://mydemo.search.windows.net.Sous Paramètres>Clés, copiez une clé d’administration. Les clés d’administration sont utilisées pour ajouter, modifier et supprimer des objets. Il existe deux clés d’administration interchangeables. Copiez l’une ou l’autre.
Configurer votre fichier REST
Démarrer Visual Studio Code et créer un fichier
Fournissez des valeurs pour les variables utilisées dans la requête :
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREEnregistrez le fichier en utilisant une extension de fichier
.restou.http.
Consultez Démarrage rapide : Recherche de texte à l’aide de REST si vous avez besoin d’aide avec le client REST.
Création d'une source de données
Créer une source de données (REST) permet de créer une connexion à la source de données qui spécifie les données à indexer.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Envoyez la demande. La réponse doit ressembler à ce qui suit :
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
Création d'un index
Créer un index (REST) permet de créer un index de recherche sur votre service de recherche. Un index spécifie tous les paramètres et leurs attributs.
Pour un JSON imbriqué, les champs d’index doivent être identiques aux champs sources. Actuellement, la Recherche Azure AI ne prend pas en charge les mappages de champs vers des JSON imbriqués. Pour cette raison, les noms de champs et les types de données doivent correspondre complètement. L’index suivant s’aligne sur les éléments JSON dans le contenu brut.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
Points essentiels :
Vous ne pouvez pas utiliser de mappages de champs pour rapprocher les différences entre les noms de champs ou les types de données. Ce schéma d’index est conçu pour mettre en miroir le contenu brut.
Le JSON imbriqué est modélisé en tant que
Collection(Edm.ComplextType). Dans le contenu brut, il y a plusieurs concerts pour chaque saison, et plusieurs œuvres pour chaque concert. Pour prendre en charge cette structure, utilisez des collections pour les types complexes.Dans le contenu brut,
DateetTimesont des chaînes, les types de données correspondants dans l’index sont donc également des chaînes.
Créer et exécuter un indexeur
Créer un indexeur permet de créer un indexeur sur votre service de recherche. Un indexeur se connecte à la source de données, charge et indexe des données et peut fournir une planification pour automatiser l’actualisation des données.
La configuration de l’indexeur inclut le mode d’analyse jsonArray ainsi que documentRoot.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
Points essentiels :
Le fichier de contenu brut contient un tableau JSON (
"programs") avec 1 526 structures JSON imbriquées. DéfinissezparsingModesurjsonArraypour indiquer à l’indexeur que chaque objet blob contient un tableau JSON. Étant donné que le JSON imbriqué commence un niveau plus bas, définissezdocumentRootsur/programs.L’indexeur est exécuté pendant plusieurs minutes. Attendez que l’exécution de l’indexeur se termine avant d’exécuter des requêtes.
Exécuter des requêtes
Vous pouvez démarrer la recherche dès que le premier document est chargé.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Envoyez la demande. Il s’agit d’une requête de recherche en texte intégral non spécifiée qui retourne tous les champs marqués comme récupérables dans l’index, ainsi qu’un nombre de documents. La réponse doit ressembler à ce qui suit :
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
Ajoutez un paramètre search pour effectuer une recherche sur une chaîne. Ajoutez un paramètre select pour limiter les résultats à moins de champs. Ajoutez un filter pour affiner davantage la recherche.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
Deux documents sont retournés dans la réponse.
Pour les filtres, vous pouvez également utiliser des opérateurs logiques (and, or, not) et des opérateurs de comparaison (eq, ne, gt, lt, ge, le). Les comparaisons de chaînes sont sensibles à la casse. Pour plus d’informations et d’exemples, consultez Créer une requête.
Remarque
Le paramètre $filter fonctionne uniquement sur les champs qui ont été marquées comme « filtrables » lors de la création de l’index.
Réinitialiser et réexécuter
Les indexeurs peuvent être réinitialisés, ce qui efface l’historique de l’exécution et permet une réexécution complète. Les requêtes GET suivantes concernent la réinitialisation, suivie de la réexécution.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources individuellement, ou supprimer le groupe de ressources pour supprimer l’ensemble des ressources.
Vous pouvez utiliser le portail Azure pour supprimer les index, les indexeurs et les sources de données.
Étapes suivantes
Maintenant que vous êtes familiarisé avec les principes fondamentaux de l’indexation de Stockage Blob Azure, examinons de plus près la configuration de l’indexeur pour les objets blob JSON dans Stockage Azure.