Tutoriel : Superviser un cluster Service Fabric dans Azure
Le monitoring et les diagnostics sont essentiels au développement, au test et au déploiement de charges de travail dans tout environnement cloud. Ce tutoriel est le deuxième d’une série. Il vous montre comment superviser et diagnostiquer un cluster Service Fabric à l’aide d’événements, de compteurs de performances et de rapports d’intégrité. Pour plus d’informations, consultez la vue d’ensemble sur la supervision des clusters et la supervision de l’infrastructure.
Dans ce tutoriel, vous allez apprendre à :
- Afficher les événements Service Fabric
- Interroger les API EventStore pour rechercher des événements de cluster
- Superviser l’infrastructure/recueillir des compteurs de performances
- Afficher des rapports d’intégrité de cluster
Cette série de tutoriels vous montre comment effectuer les opérations suivantes :
- Créer un cluster Windows sécurisé sur Azure à l’aide d’un modèle
- Superviser un cluster
- Mettre à l’échelle un cluster
- Mettre à niveau le runtime d’un cluster
- Supprimer un cluster
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour bien démarrer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Prérequis
Avant de commencer ce tutoriel :
- Si vous n’avez pas d’abonnement Azure, créez un compte gratuit
- Installez Azure PowerShell ou Azure CLI.
- Créer un cluster Windows sécurisé
- Configurer la collecte des diagnostics pour le cluster
- Activer le service EventStore dans le cluster
- Configurer les journaux Azure Monitor et l’agent Log Analytics pour le cluster
Afficher les événements Service Fabric à l’aide des journaux Azure Monitor
Les journaux Azure Monitor collectent et analysent les données de télémétrie des applications et services hébergés dans le cloud, et fournissent des outils d’analyse pour vous aider à maximiser leur disponibilité et leurs performances. Vous pouvez exécuter des requêtes dans les journaux Azure Monitor pour obtenir des informations détaillées et résoudre les problèmes qui se produisent dans votre cluster.
Pour accéder à la solution Service Fabric Analytics, accédez au portail Azure et sélectionnez le groupe de ressources dans lequel vous avez créé la solution Service Fabric Analytics.
Sélectionnez la ressource ServiceFabric(mysfomsworkspace) .
Dans Vue d’ensemble, des vignettes de type graphe s’affichent pour chacune des solutions activées, y compris pour Service Fabric. Sélectionnez le graphique Service Fabric pour accéder à la solution Service Fabric Analytics.
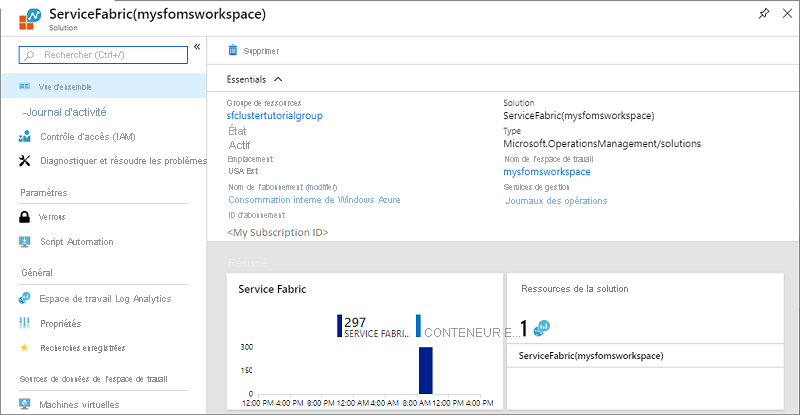
L’image ci-dessus montre la page d’accueil de la solution Service Fabric Analytics. Cette page d’accueil fournit une capture instantanée de ce qui se passe dans votre cluster.
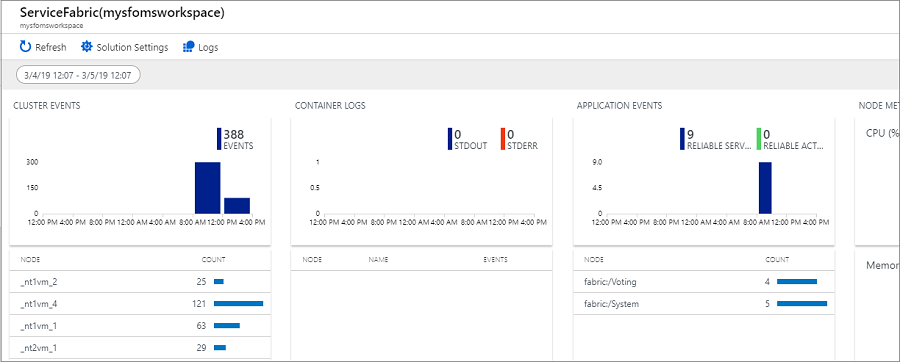
Si vous avez activé des diagnostics lors de la création du cluster, vous pouvez voir les événements pour le
- Événements de cluster Service Fabric
- Événements du modèle de programmation Reliable Actors
- Événements du modèle de programmation Reliable Services
Notes
En dehors des événements Service Fabric prêts à l’emploi, il est possible de collecter des événements système plus détaillés en mettant à jour la configuration de l’extension de diagnostics.
Afficher les événements Service Fabric, notamment les actions sur les nœuds
Dans la page Service Fabric Analytics, cliquez sur le graphe des Événements de cluster. Les journaux pour tous les événements système qui ont été collectés s’affichent. Pour référence, il s’agit de la table WADServiceFabricSystemEventsTable dans le compte Stockage Azure. De même, les services fiables et les événements acteurs que vous voyez ensuite proviennent de ces tables respectives.
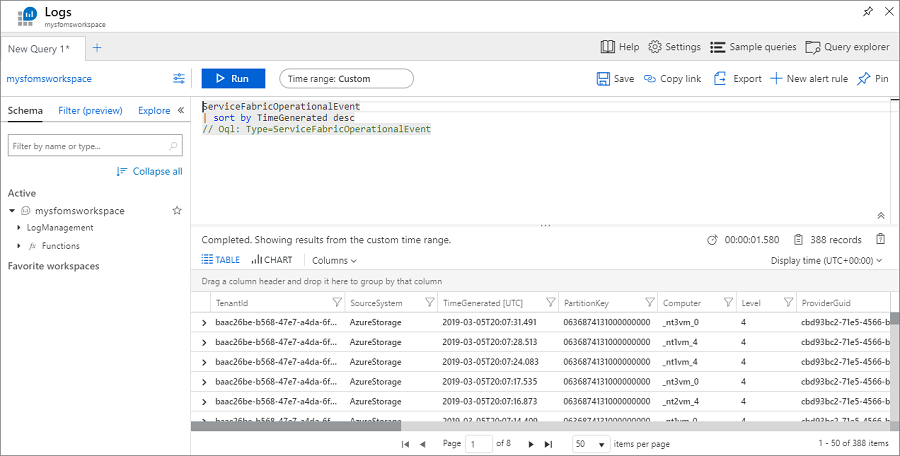
La requête utilise le langage de requête Kusto, que vous pouvez modifier pour affiner ce que vous cherchez. Par exemple, pour rechercher toutes les actions effectuées sur des nœuds du cluster, vous pouvez utiliser la requête suivante. Les ID d’événement ci-dessous se trouvent dans la référence des événements du canal opérationnel.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
Le langage de requête Kusto est puissant. Voici quelques autres requêtes utiles.
Créer une table de recherche ServiceFabricEvent en tant que fonction définie par l’utilisateur en enregistrant la requête en tant que fonction avec l’alias ServiceFabricEvent :
let ServiceFabricEvent = datatable(EventId: int, EventName: string)
[
...
18603, 'NodeUpOperational',
18604, 'NodeDownOperational',
...
];
ServiceFabricEvent
Réexécuter les événements opérationnels enregistrés au cours de la dernière heure :
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Réexécuter les événements opérationnels avec EventId == 18604 et EventName == 'NodeDownOperational' :
ServiceFabricOperationalEvent
| where EventId == 18604
| project EventId, EventName = 'NodeDownOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Réexécuter les événements opérationnels avec EventId == 18604 et EventName == 'NodeUpOperational' :
ServiceFabricOperationalEvent
| where EventId == 18603
| project EventId, EventName = 'NodeUpOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Retourner les rapports d’intégrité avec HealthState == 3 (Erreur) et extraire les propriétés supplémentaires à partir du champ EventMessage :
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Retourner un graphique de temps des événements avec EventId != 17523 :
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| where EventId != 17523
| summarize Count = count() by Timestamp = bin(TimeGenerated, 1h), strcat(tostring(EventId), " - ", case(EventName != "", EventName, "Unknown"))
| render timechart
Obtenir les événements opérationnels Service Fabric agrégés avec le service et le nœud spécifiques :
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Afficher le nombre d’événements Service Fabric par ID d’événement / EventName à l’aide d’une requête inter-ressources :
app('PlunkoServiceFabricCluster').traces
| where customDimensions.ProviderName == 'Microsoft-ServiceFabric'
| extend EventId = toint(customDimensions.EventId), TaskName = tostring(customDimensions.TaskName)
| where EventId != 17523
| join kind=leftouter ServiceFabricEvent on EventId
| extend EventName = case(EventName != '', EventName, 'Undocumented')
| summarize ["Event Count"]= count() by bin(timestamp, 30m), EventName = strcat(tostring(EventId), " - ", EventName)
| render timechart
Afficher les événements d’application Service Fabric
Vous pouvez afficher les événements pour les services fiables et les applications d’acteurs fiables déployés sur le cluster. Dans la page Service Fabric Analytics, sélectionnez le graphe des Événements d’application.
Exécutez la requête suivante pour afficher les événements de vos applications de services fiables :
ServiceFabricReliableServiceEvent
| sort by TimeGenerated desc
Vous pouvez voir différents événements qui surviennent lorsque le service runasync est démarré et terminé, ce qui est généralement le cas lors de déploiements et de mises à niveau.
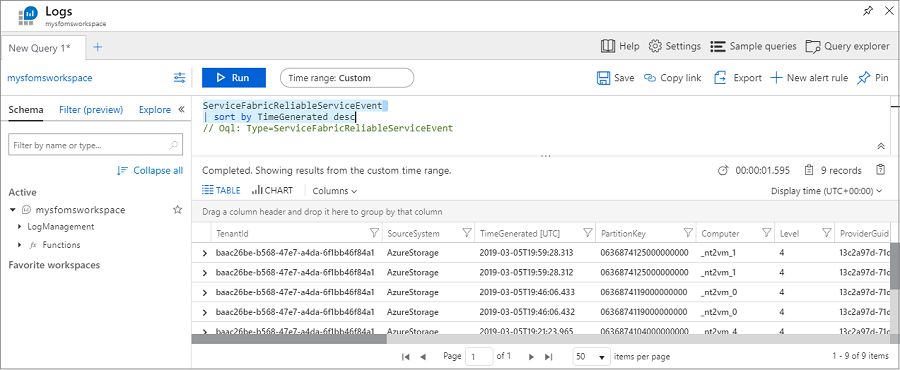
Vous pouvez également trouver les événements pour le service fiable avec ServiceName == "fabric:/Watchdog/WatchdogService" :
ServiceFabricReliableServiceEvent
| where ServiceName == "fabric:/Watchdog/WatchdogService"
| project TimeGenerated, EventMessage
| order by TimeGenerated desc
Les événements d’acteurs fiables peuvent être affichés de manière similaire :
ServiceFabricReliableActorEvent
| sort by TimeGenerated desc
Pour configurer des événements plus détaillés pour des acteurs fiables, vous pouvez modifier le scheduledTransferKeywordFilter dans le fichier config pour l’extension de diagnostic dans le modèle de cluster. Vous trouverez plus d’informations à ce sujet dans la référence des événements des acteurs fiables.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
Afficher les compteurs de performances avec les journaux Azure Monitor
Pour afficher les compteurs de performances, ouvrez le portail Azure et accédez au groupe de ressources dans lequel vous avez créé la solution Service Fabric Analytics.
Sélectionnez la ressource ServiceFabric(mysfomsworkspace) , puis espace de travail Log Analytics, puis Paramètres avancés.
Sélectionnez Données, puis choisissez Compteurs de performances Windows. Une liste des compteurs par défaut que vous pouvez choisir d’activer s’affiche, tout comme vous pouvez également définir l’intervalle de collecte. En outre, vous pouvez ajouter d’autres compteurs de performances à collecter. Le format approprié est référencé dans cet article. Cliquez sur Enregistrer, puis sélectionnez OK.
Fermez le panneau Paramètres avancés et sélectionnez Récapitulatif de l’espace de travail sous le titre Général. Pour chacune des solutions activées, il existe une vignette graphique, y compris pour Service Fabric. Sélectionnez le graphique Service Fabric pour accéder à la solution Service Fabric Analytics.
Il existe des vignettes graphiques pour le canal opérationnel et les événements de services fiables. La représentation graphique du flux de données correspondant aux compteurs que vous avez sélectionnés s’affiche dans Métriques de nœud.
Sélectionnez un graphique de métrique de conteneur pour afficher plus de détails. Vous pouvez également interroger les données du compteur de performances de la même façon que les événements de cluster et appliquer des filtres sur les nœuds, le nom du compteur de performances et les valeurs à l’aide du langage de requête Kusto.
Interroger le service EventStore
Le service EventStore offre un moyen de comprendre l’état de votre cluster ou de vos charges de travail à un moment donné dans le temps. EventStore est un service Service Fabric avec état qui conserve les événements du cluster. Les événements sont exposés par le biais de Service Fabric Explorer, de REST et des API. EventStore interroge le cluster directement pour obtenir des données de diagnostics sur une entité dans votre cluster. Pour voir une liste complète des événements disponibles dans l’EventStore, consultez Événements Service Fabric.
Vous pouvez interroger les API EventStore par programmation à l’aide de la bibliothèque de client Service Fabric.
Voici un exemple de requête pour tous les événements de cluster entre 2018-04-03T18:00:00Z et 2018-04-04T18:00:00Z, par le biais de la fonction GetClusterEventListAsync.
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl, settings);
var clstrEvents = sfhttpClient.EventsStore.GetClusterEventListAsync(
"2018-04-03T18:00:00Z",
"2018-04-04T18:00:00Z")
.GetAwaiter()
.GetResult()
.ToList();
Voici un autre exemple qui interroge sur l’intégrité du cluster et tous les événements de nœud en septembre 2018 et les affiche.
const int timeoutSecs = 60;
var clusterUrl = new Uri(@"http://localhost:19080"); // This example is for a Local cluster
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl);
var clusterHealth = sfhttpClient.Cluster.GetClusterHealthAsync().GetAwaiter().GetResult();
Console.WriteLine("Cluster Health: {0}", clusterHealth.AggregatedHealthState.Value.ToString());
Console.WriteLine("Querying for node events...");
var nodesEvents = sfhttpClient.EventsStore.GetNodesEventListAsync(
"2018-09-01T00:00:00Z",
"2018-09-30T23:59:59Z",
timeoutSecs,
"NodeDown,NodeUp")
.GetAwaiter()
.GetResult()
.ToList();
Console.WriteLine("Result Count: {0}", nodesEvents.Count());
foreach (var nodeEvent in nodesEvents)
{
Console.Write("Node event happened at {0}, Node name: {1} ", nodeEvent.TimeStamp, nodeEvent.NodeName);
if (nodeEvent is NodeDownEvent)
{
var nodeDownEvent = nodeEvent as NodeDownEvent;
Console.WriteLine("(Node is down, and it was last up at {0})", nodeDownEvent.LastNodeUpAt);
}
else if (nodeEvent is NodeUpEvent)
{
var nodeUpEvent = nodeEvent as NodeUpEvent;
Console.WriteLine("(Node is up, and it was last down at {0})", nodeUpEvent.LastNodeDownAt);
}
}
Superviser l’intégrité des clusters
Service Fabric propose un modèle d’intégrité avec des entités d’intégrité sur lesquelles les composants système et les agents de supervision peuvent signaler les conditions locales qu’ils supervisent. Le magasin d’intégrité agrège toutes les données d’intégrité pour déterminer si les entités sont saines.
Les rapports d’intégrité envoyés par les composants système alimentent automatiquement le cluster. Pour en savoir plus, consultez l’article Utiliser les rapports d’intégrité du système pour la résolution des problèmes.
Service Fabric expose les requêtes d’intégrité pour chacun des types d’entitépris en charge. Elles sont accessibles par l’intermédiaire de l’API, via les méthodes sur FabricClient.HealthManager, des applets de commande PowerShell et de REST. Ces requêtes renvoient des informations complètes sur l’intégrité de l’entité : l’état d’intégrité agrégé, les événements d’intégrité de l’entité, les états d’intégrité enfants (le cas échéant), les évaluations de défaut d’intégrité (lorsque l’entité n’est pas intègre) et les statistiques d’intégrité enfants (au besoin).
Obtenir les données d’intégrité du cluster
L’applet de commande Get-ServiceFabricClusterHealth retourne les données d’intégrité de l’entité du cluster et contient les états d’intégrité des applications et des nœuds (enfants du cluster). Commencez par vous connecter au cluster à l’aide de l’applet de commande Connect-ServiceFabricCluster.
L’état du cluster indique 11 nœuds, l’application système et l’application fabric:/Voting, configurés comme indiqué.
L’exemple suivant obtient les données d’intégrité du cluster à l’aide des stratégies de contrôle d’intégrité par défaut. Les 11 nœuds sont intègres, mais l’état d’intégrité agrégé du cluster est Erreur, car l’état de l’application fabric:/Voting est Erreur. Notez que les évaluations de défaut d’intégrité fournissent des détails sur les conditions qui ont déclenché l’intégrité agrégée.
Get-ServiceFabricClusterHealth
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
33% (1/3) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates :
NodeName : _nt2vm_3
AggregatedHealthState : Ok
NodeName : _nt1vm_4
AggregatedHealthState : Ok
NodeName : _nt2vm_2
AggregatedHealthState : Ok
NodeName : _nt1vm_3
AggregatedHealthState : Ok
NodeName : _nt2vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_2
AggregatedHealthState : Ok
NodeName : _nt2vm_0
AggregatedHealthState : Ok
NodeName : _nt1vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_0
AggregatedHealthState : Ok
NodeName : _nt3vm_0
AggregatedHealthState : Ok
NodeName : _nt2vm_4
AggregatedHealthState : Ok
ApplicationHealthStates :
ApplicationName : fabric:/System
AggregatedHealthState : Ok
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
HealthStatistics :
Node : 11 Ok, 0 Warning, 0 Error
Replica : 4 Ok, 0 Warning, 0 Error
Partition : 2 Ok, 0 Warning, 0 Error
Service : 2 Ok, 0 Warning, 0 Error
DeployedServicePackage : 3 Ok, 1 Warning, 1 Error
DeployedApplication : 1 Ok, 1 Warning, 1 Error
Application : 0 Ok, 0 Warning, 1 Error
L’exemple PowerShell suivant obtient les données d’intégrité du cluster à l’aide d’une stratégie d’application personnalisée. Elle filtre les résultats afin d’identifier uniquement les applications et les nœuds indiquant une erreur ou un avertissement. Dans cet exemple, aucun nœud n’est retourné puisqu’ils sont tous sains. Seule l’application fabric:/Voting respecte le filtre d’applications. Comme la stratégie personnalisée exige de considérer les avertissements comme des erreurs pour l’application fabric:/Voting, l’application présente l’état d’erreur tout comme le cluster.
$appHealthPolicy = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicy
$appHealthPolicy.ConsiderWarningAsError = $true
$appHealthPolicyMap = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicyMap
$appUri1 = New-Object -TypeName System.Uri -ArgumentList "fabric:/Voting"
$appHealthPolicyMap.Add($appUri1, $appHealthPolicy)
Get-ServiceFabricClusterHealth -ApplicationHealthPolicyMap $appHealthPolicyMap -ApplicationsFilter "Warning,Error" -NodesFilter "Warning,Error" -ExcludeHealthStatistics
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
100% (5/5) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_2' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2466f2f9-d5fd-410c-a6a4-5b1e00630cca' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376486201388'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_4' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '5faa5201-eede-400a-865f-07f7f886aa32' is in Error.
'System.Hosting' reported Warning for property 'CodePackageActivation:Code:SetupEntryPoint:131959376207396204'. The evaluation treats
Warning as Error.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_0' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '204f1783-f774-4f3a-b371-d9983afaf059' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959375885791093'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt3vm_0' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2533ae95-2d2a-4f8b-beef-41e13e4c0081' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376108346272'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates : None
ApplicationHealthStates :
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
Obtenir les données d’intégrité du nœud
L’applet de commande Get-ServiceFabricNodeHealth retourne les données d’intégrité d’une entité de nœud et contient les événements d’intégrité signalés sur le nœud. Commencez par vous connecter au cluster à l’aide de l’applet de commande Connect-ServiceFabricCluster. L’exemple suivant obtient l’intégrité d’un nœud spécifique à l’aide des stratégies de contrôle d’intégrité par défaut :
Get-ServiceFabricNodeHealth _nt1vm_3
L’exemple suivant obtient les données d’intégrité de tous les nœuds du cluster :
Get-ServiceFabricNode | Get-ServiceFabricNodeHealth | select NodeName, AggregatedHealthState | ft -AutoSize
Obtenir l’intégrité du service système
Obtenir l’intégrité agrégée des services système :
Get-ServiceFabricService -ApplicationName fabric:/System | Get-ServiceFabricServiceHealth | select ServiceName, AggregatedHealthState | ft -AutoSize
Étapes suivantes
Dans ce didacticiel, vous avez appris à :
- Afficher les événements Service Fabric
- Interroger les API EventStore pour rechercher des événements de cluster
- Superviser l’infrastructure/recueillir des compteurs de performances
- Afficher des rapports d’intégrité de cluster
Maintenant, passez au tutoriel suivant pour savoir comment mettre à l’échelle un cluster.