Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Dans cette section, vous apprendrez à créer et utiliser des vues pour encapsuler des requêtes de pool SQL sans serveur. Les vues vous permettent de réutiliser ces requêtes. Les vues sont également nécessaires si vous souhaitez utiliser des outils, tels que Power BI, en conjonction avec un pool SQL serverless.
Prérequis
La première étape consiste à créer une base de données dans laquelle la vue sera créée et à initialiser les objets nécessaires pour s’authentifier sur le stockage Azure en exécutant le script d’installation sur cette base de données. Toutes les requêtes de cet article seront exécutées sur votre exemple de base de données.
Vues de données externes
Vous pouvez créer des vues de la même façon que vous créez des vues SQL Server standard. La requête suivante crée une vue qui lit le fichier population.csv.
Note
Modifiez la première ligne de la requête, c’est-à-dire [mydbname], afin d’utiliser la base de données que vous avez créée.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
La vue utilise EXTERNAL DATA SOURCE avec une URL racine de votre stockage, en tant que DATA_SOURCE et ajoute un chemin de fichier relatif aux fichiers.
Vues de Delta Lake
Si vous créez les vues pour un dossier Delta Lake, vous devez spécifier l’emplacement du dossier racine après l’option BULK au lieu de spécifier le chemin d’accès au fichier.
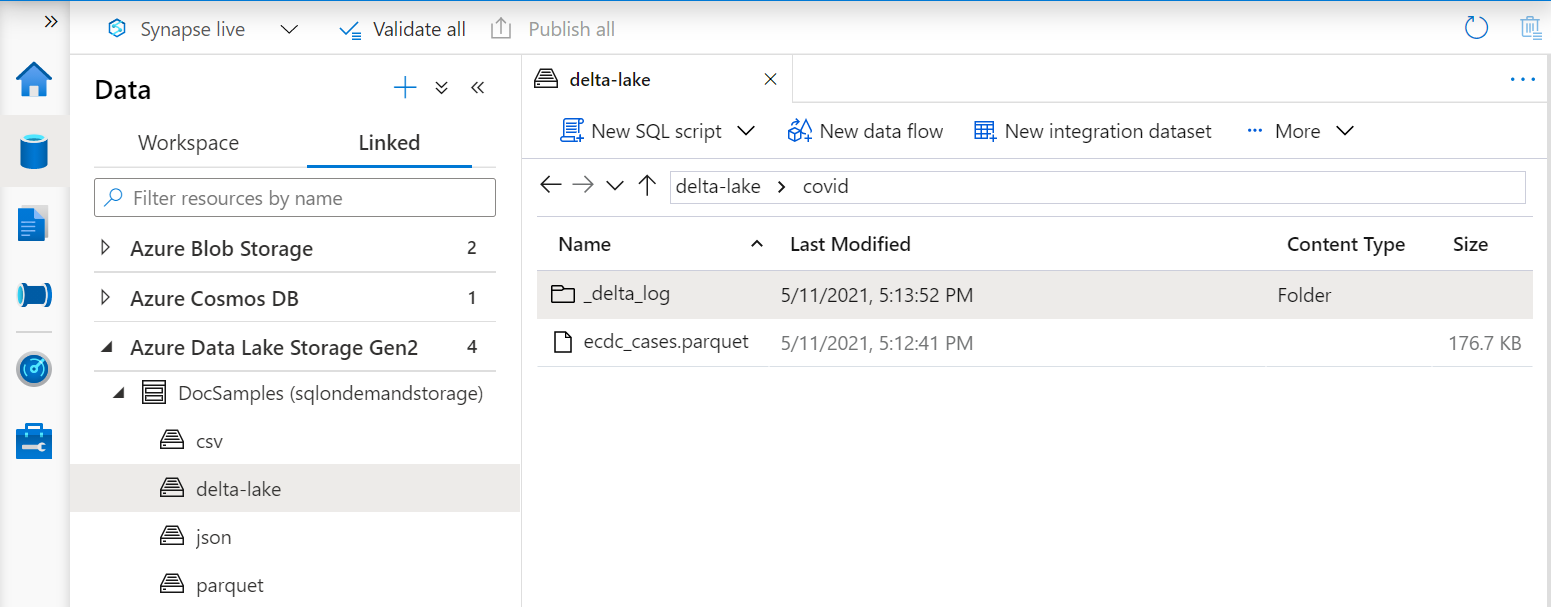
La fonction OPENROWSET qui lit les données du dossier Delta Lake examine la structure de celui-ci et identifie automatiquement les emplacements des fichiers.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Pour plus d’informations, consultez la page d’aide autonome du pool SQL serverless Synapse et Problèmes connus d’Azure Synapse Analytics.
Vues partitionnées
Si vous disposez d’un ensemble de fichiers partitionnés dans la structure de dossiers hiérarchique, vous pouvez décrire le modèle de partition à l’aide des caractères génériques dans le chemin du fichier. Utilisez la fonction FILEPATH pour exposer des parties du chemin de dossier en tant que colonnes de partitionnement.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Les vues partitionnées peuvent améliorer les performances de vos requêtes en effectuant l’élimination de partition lorsque vous les interrogez avec des filtres sur les colonnes de partitionnement. Toutefois, l’élagage de partition n’est pas pris en charge par toutes les requêtes ; il est donc essentiel de respecter certaines bonnes pratiques.
Pour garantir une élimination de partition, évitez d’utiliser des sous-requêtes dans des filtres, car elles peuvent interférer avec la possibilité d’éliminer des partitions. Au lieu de cela, transmettez le résultat de la sous-requête en tant que variable au filtre.
Lorsque vous utilisez des JOINTURES dans des requêtes SQL, déclarez le prédicat de filtre en tant que NVARCHAR pour réduire la complexité du plan de requête et augmenter la probabilité d’élimination correcte de la partition. Les colonnes de partition sont généralement interprétées comme NVARCHAR(1024) ; l’utilisation du même type dans le prédicat permet d’éviter une conversion implicite de type, susceptible d’alourdir la complexité du plan de requête.
Vues partitionnées de Delta Lake
Si vous créez des vues partitionnées au-dessus d'un stockage Delta Lake, vous pouvez spécifier uniquement un dossier racine Delta Lake et vous n'avez pas besoin d'exposer explicitement les colonnes de partitionnement en utilisant la fonction FILEPATH :
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
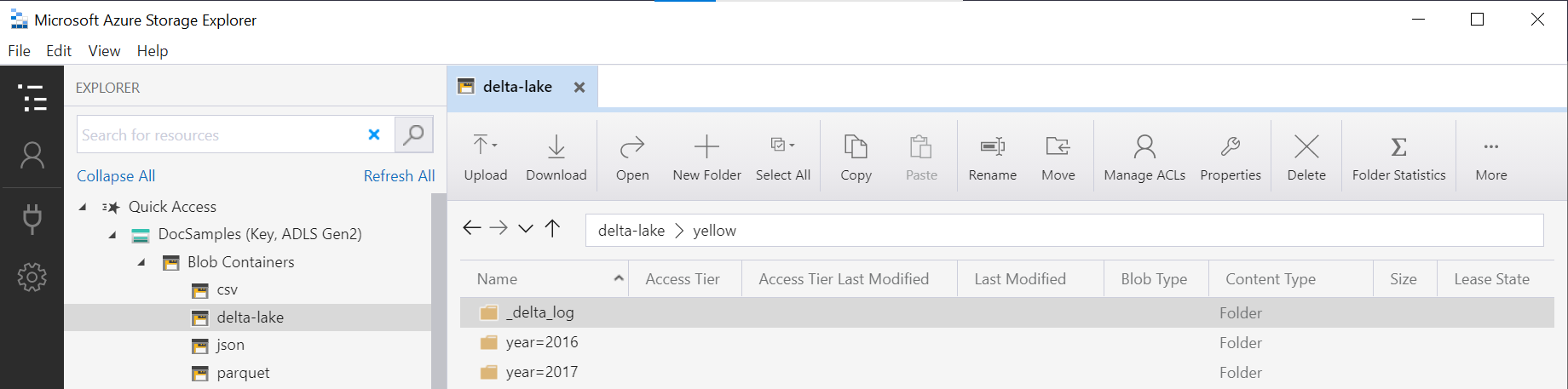
La fonction OPENROWSET examine la structure du dossier Delta Lake sous-jacent, puis identifie et expose automatiquement les colonnes de partitionnement. L’élimination des partitions est effectuée automatiquement si vous placez la colonne de partitionnement dans la clause WHERE d’une requête.
Le nom de dossier dans la fonction OPENROWSET (yellow dans cet exemple), qui est concaténé avec l’URI LOCATION défini dans la source de données DeltaLakeStorage doit référencer le dossier Delta Lake racine contenant un sous-dossier nommé _delta_log.
Pour plus d’informations, consultez la page d’aide autonome du pool SQL serverless Synapse et Problèmes connus d’Azure Synapse Analytics.
Vues JSON
Les vues représentent une solution pertinente lorsque vous devez appliquer un traitement supplémentaire au jeu de résultats extrait des fichiers. Par exemple, il peut s’agir d’analyser des fichiers JSON auxquels nous devons appliquer les fonctions JSON afin d’extraire les valeurs des documents JSON :
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
La fonction OPENJSON analyse chaque ligne du fichier JSON qui contient un document JSON par ligne au format textuel.
Les vues sur les conteneurs dans Azure Cosmos DB
Les vues peuvent être créées sur les conteneurs Azure Cosmos DB si le stockage analytique Azure Cosmos DB est activé sur le conteneur. Le nom du compte Azure Cosmos DB, le nom de la base de données et le nom du conteneur doivent être ajoutés dans la vue, et la clé d'accès en lecture seule doit être placée dans l'identifiant d'authentification lié à la base de données auquel la vue fait référence.
Cet exemple de script utilise une base de données et un conteneur que vous pouvez configurer en suivant ces instructions.
Important
Dans le script, remplacez ces valeurs par vos propres valeurs :
- your-cosmosdb : le nom de votre compte Cosmos DB
- access-key : la clé de votre compte Cosmos DB
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Pour plus d’informations, consultez Interroger des données Azure Cosmos DB avec un pool SQL sans serveur dans Azure Synapse Link.
Utiliser une vue
Vous pouvez utiliser des vues dans vos requêtes, de la même façon que vous utilisez des vues dans les requêtes SQL Server.
La requête suivante illustre l’utilisation de la vue population_csv que nous avons créée à la section Créer une vue. Elle retourne les noms des pays/régions avec leur population en 2019, dans l’ordre décroissant.
Note
Modifiez la première ligne de la requête, c’est-à-dire [mydbname], afin d’utiliser la base de données que vous avez créée.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
Lorsque vous interrogez la vue, vous pouvez rencontrer des erreurs ou des résultats inattendus. Cela signifie vraisemblablement que la vue fait référence à des colonnes ou des objets qui ont été modifiés ou qui n’existent plus. Vous devez ajuster manuellement la définition de la vue pour l’aligner sur les modifications sous-jacentes de schéma.
Contenu connexe
Pour plus d’informations sur la façon d’interroger différents types de fichiers, reportez-vous aux articles Interroger un fichier CSV, Interroger des fichiers Parquet et Interroger des fichiers JSON.