Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Cet article contient des informations sur la façon de résoudre les problèmes les plus fréquents liés au pool SQL serverless dans Azure Synapse Analytics.
Pour en savoir plus sur Azure Synapse Analytics, consultez les rubriques de la Vue d’ensemble.
Synapse Studio
Synapse Studio est un outil simple d’utilisation qui vous permet d’accéder à vos données en utilisant navigateur sans devoir installer des outils d’accès aux bases de données. Synapse Studio n’est pas conçu pour lire un grand jeu de données ni pour la gestion complète d’objets SQL.
Le pool SQL serverless apparaît en grisé dans Synapse Studio
Si Synapse Studio ne peut pas établir de connexion au pool SQL serverless, vous voyez que le pool SQL serverless apparaît en grisé ou que son état est Hors connexion.
Généralement, ce problème se produit pour l’une des deux raisons suivantes :
- Votre réseau empêche la communication avec le back-end Azure Synapse Analytics. Le cas le plus fréquent est que le port TCP 1443 est bloqué. Pour que le pool SQL serverless fonctionne, débloquez ce port. D’autres problèmes peuvent empêcher le fonctionnement du pool SQL serverless. Pour plus d’informations, consultez le Guide de résolution des problèmes.
- Vous n’avez pas l’autorisation de vous connecter au pool SQL serverless. Pour obtenir l’accès, un administrateur de l’espace de travail Azure Synapse doit vous ajouter au rôle Administrateur de l’espace de travail ou au rôle Administrateur de SQL. Pour plus d’informations, consultez Contrôle d’accès d’Azure Synapse.
Connexion WebSocket fermée de manière inattendue
Votre requête peut échouer avec le message d’erreur Websocket connection was closed unexpectedly.. Ce message signifie que la connexion de votre navigateur à Synapse Studio a été interrompue, par exemple en raison d’un problème réseau.
- Pour résoudre ce problème, réexécutez votre requête.
- Essayez l’extension MSSQL pour Visual Studio Code ou SQL Server Management Studio pour les mêmes requêtes au lieu de Synapse Studio pour une investigation plus approfondie.
- Si ce message s’affiche souvent dans votre environnement, demandez de l’aide à votre administrateur réseau. Vous pouvez également vérifier les paramètres du pare-feu et consulter le Guide de résolution des problèmes.
- Si le problème persiste, créez un ticket de support via le portail Azure.
Les bases de données serverless ne sont pas affichées dans Synapse Studio
Si vous ne voyez pas les bases de données qui sont créées dans un pool SQL serverless, vérifiez que votre pool SQL serverless a démarré. Si le pool SQL serverless est désactivé, les bases de données ne sont pas affichées. Exécutez une requête, par exemple SELECT 1 sur le pool SQL serverless pour l’activer et faire apparaître les bases de données.
Le pool SQL serverless Synapse est affiché comme non disponible
Une configuration réseau incorrecte est souvent à l’origine de ce comportement. Vérifiez que les ports sont correctement configurés. Si vous utilisez un pare-feu ou des points de terminaison privés, vérifiez également ces paramètres.
Enfin, assurez-vous que les rôles appropriés sont accordés et n’ont pas été révoqués.
Impossible de créer une base de données, car la requête utilisera l’ancienne clé/la clé expirée
Cette erreur est due à la modification de la clé gérée par le client de l’espace de travail utilisée pour le chiffrement. Vous pouvez choisir de chiffrer à nouveau toutes les données de l’espace de travail avec la dernière version de la clé active. Pour effectuer un nouveau chiffrement, remplacez la clé du Portail Azure par une clé temporaire, puis revenez à la clé que vous souhaitez utiliser pour le chiffrement. En savoir plus sur la gestion des clés d’un espace de travail.
Le pool SQL serverless Synapse n’est pas disponible après le transfert d’un abonnement vers un autre locataire Microsoft Entra
Si vous avez déplacé un abonnement vers un autre locataire Microsoft Entra, vous pouvez rencontrer des problèmes avec le pool SQL serverless. Créez un ticket de support et le support Azure vous contactera pour résoudre le problème.
Accès au stockage
Si vous recevez des erreurs quand vous essayez d’accéder à des fichiers dans le stockage Azure, vérifiez que vous disposez des autorisations nécessaires pour accéder aux données. Vous devez être en mesure d’accéder aux fichiers accessibles publiquement. Si vous essayez d’accéder aux données sans informations d’identification, assurez-vous que votre identité Microsoft Entra peut accéder directement aux fichiers.
Si vous avez une clé de signature d’accès partagé que vous devez utiliser pour accéder aux fichiers, vérifiez que vous avez créé des informations d’identification au niveau du serveur ou délimitée à la base de données qui contiennent ces informations d’identification. Les informations d’identification sont nécessaires si vous devez accéder aux données en utilisant l’identité managée et le nom de principal du service personnalisé de l’espace de travail.
Impossible de lire, de lister ou d’accéder aux fichiers dans Azure Data Lake Storage
Si vous utilisez une connexion Microsoft Entra sans informations d’identification explicites, assurez-vous que votre identité Microsoft Entra peut accéder aux fichiers dans le stockage. Pour accéder aux fichiers, votre identité Microsoft Entra doit disposer de l’autorisation Lecteur de données Blob , ou des autorisations pour Liste et Lirelistes de contrôle d’accès (ACL) dans ADLS. Pour plus d’informations, consultez La requête échoue, car le fichier ne peut pas être ouvert.
Si vous accédez au stockage à l'aide d’informations d'identification, assurez-vous que votre identité managée ou votre SPN possède le rôle de lecteur de données ou de contributeur ou des autorisations ACL spécifiques. Si vous avez utilisé un jeton de signature d’accès partagé, vérifiez qu’il dispose de l’autorisation rl et qu’il n’a pas expiré.
Si vous utilisez une connexion SQL et la OPENROWSETfonctionsans source de données, vérifiez que vous disposez d’informations d’identification au niveau du serveur qui correspondent à l’URI du stockage et qu’elles ont l’autorisation d’accéder au stockage.
La requête échoue, car le fichier ne peut pas être ouvert
Si votre requête échoue avec l’erreur File cannot be opened because it does not exist or it is used by another process, et si vous êtes sûr que les deux fichiers existent et qu’il ne sont pas utilisés par un autre processus, c’est que le pool SQL serverless ne peut pas accéder au fichier. Ce problème se produit généralement parce que votre identité Microsoft Entra n’a pas les droits d’accès au fichier ou parce qu’un pare-feu bloque l’accès au fichier.
Par défaut, le pool SQL serverless tente d’accéder au fichier à l’aide de votre identité Microsoft Entra. Pour résoudre ce problème, vous devez disposer des droits appropriés pour accéder au fichier. Le moyen le plus simple consiste à vous accorder vous-même un rôle « Contributeur aux données Blob du stockage » pour le compte de stockage que vous tentez d’interroger.
Pour plus d'informations, consultez les pages suivantes :
- Contrôle d’accès Microsoft Entra ID pour le stockage
- Contrôler l’accès au compte de stockage pour le pool SQL serverless dans Synapse Analytics
Alternative au rôle Contributeur aux données Blob du stockage
Au lieu de vous accorder à vous-même le rôle Contributeur aux données Blob du stockage, vous pouvez aussi accorder des autorisations plus précises sur un sous-ensemble de fichiers.
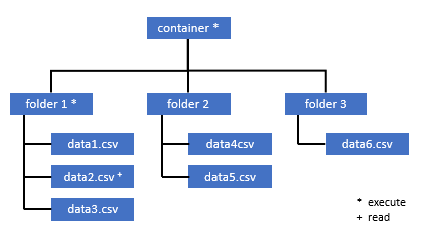
Tous les utilisateurs qui doivent accéder à certaines données de ce conteneur doivent également avoir l’autorisation EXECUTE sur tous les dossiers parents jusqu’à la racine (le conteneur).
En savoir plus sur la définition des listes de contrôle d’accès dans Azure Data Lake Storage Gen2.
Remarque
L’autorisation Execute au niveau du conteneur doit être définie dans Azure Data Lake Storage Gen2. Les autorisations sur le dossier peuvent être définies dans Azure Synapse.
Si vous voulez interroger data2.csv dans cet exemple, les autorisations suivantes sont nécessaires :
- Autorisation Execute sur le conteneur
- Autorisation Execute sur folder1
- Autorisation de lecture sur data2.csv
Connectez-vous à Azure Synapse avec un utilisateur administrateur disposant d’autorisations complètes sur les données auxquelles vous souhaitez accéder.
Dans le volet des données, cliquez avec le bouton droit sur le fichier, puis sélectionnez Gérer l’accès.
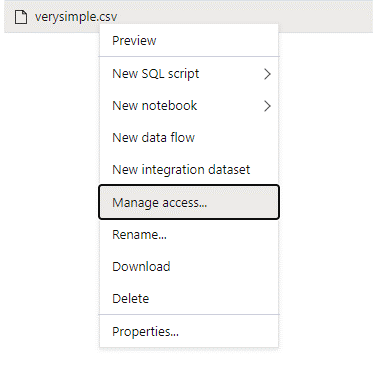
Sélectionnez au moins l’autorisation Lecture. Entrez l’UPN ou l’ID d’objet de l’utilisateur, par exemple
user@contoso.com. Sélectionnez Ajouter.Accordez une autorisation de lecture à cet utilisateur.

Remarque
Pour les utilisateurs invités, cette étape doit être effectuée directement avec Azure Data Lake, car elle ne peut pas être effectuée directement via Azure Synapse.
Impossible de lister le contenu du répertoire sur le chemin
Cette erreur indique que l’utilisateur qui interroge Azure Data Lake ne peut pas lister les fichiers présents dans le stockage. Cette erreur peut se produire dans plusieurs scénarios :
- L’utilisateur Microsoft Entra qui utilise l’authentification directe Microsoft Entra n’est pas autorisé à répertorier les fichiers dans Data Lake Storage.
- Microsoft Entra ID ou l’utilisateur SQL qui lit des données à l’aide d’une clé de signature d’accès partagé ou identité managée de l’espace de travail et cette clé ou identité n’a pas l’autorisation de répertorier les fichiers dans le stockage.
- L’utilisateur qui accède aux données Dataverse et qui n’a pas l’autorisation d’interroger des données dans Dataverse. Ce scénario peut se produire si vous utilisez des utilisateurs SQL.
- L’utilisateur qui accède à Delta Lake peut ne pas avoir l’autorisation de lire le journal des transactions Delta Lake.
Le moyen le plus simple de résoudre ce problème est de vous accorder à vous-même le rôle Contributeur aux données Blob du stockage dans le compte de stockage que vous essayez d’interroger.
Pour plus d'informations, consultez les pages suivantes :
- Contrôle d’accès Microsoft Entra ID pour le stockage
- Contrôler l’accès au compte de stockage pour le pool SQL serverless dans Synapse Analytics
Impossible de lister le contenu de la table Dataverse
Si vous utilisez Azure Synapse Link pour Dataverse pour lire les tables DataVerse liées, vous devez utiliser le compte Microsoft Entra pour accéder aux données liées à l’aide du pool SQL serverless. Pour plus d’informations, consultez Azure Synapse Link pour Dataverse avec Azure Data Lake.
Si vous essayez d’utiliser une connexion SQL pour lire une table externe qui fait référence à la table DataVerse, vous obtiendrez l’erreur suivante : External table '???' is not accessible because content of directory cannot be listed.
Les tables externes Dataverse utilisent toujours l’authentification directe Microsoft Entra. Vous ne pouvez pas les configurer pour utiliser une clé de signature d’accès partagé ou une identité managée de l’espace de travail.
Impossible de lister le contenu du journal des transactions Delta Lake
L’erreur suivante est retournée quand le pool SQL serverless ne peut pas lire le dossier du journal des transactions Delta Lake :
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Vérifiez que le dossier _delta_log existe. Vous interrogez peut-être des fichiers Parquet bruts qui ne sont pas convertis au format Delta Lake. Si le dossier _delta_log existe, vérifiez que vous disposez des autorisations de Lire et Liste sur les dossiers Delta Lake sous-jacents. Essayez de lire des fichiers .json directement FORMAT='csv'. Placez votre URI dans le paramètre BULK :
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Si cette requête échoue, l’appelant n’est pas autorisé à lire les fichiers de stockage sous-jacents.
Exécution d’une requête
Vous pouvez recevoir des erreurs pendant l’exécution de la requête dans les cas suivants :
- L’appelant ne peut pas accéder à certains objets.
- La requête ne peut pas accéder à des données externes.
- La requête contient certaines fonctionnalités qui ne sont pas prises en charge dans les pools SQL serverless.
La requête échoue, car elle ne peut pas être exécutée en raison de contraintes de ressources actuelles
Votre requête peut échouer avec le message d'erreurThis query cannot be executed due to current resource constraints. Ce message signifie que le pool SQL sans serveur ne peut pas être exécuté pour le moment. Voici quelques options de résolution du problème :
- Veillez à utiliser des types de données de taille raisonnable.
- Si votre requête cible des fichiers Parquet, définissez des types explicites pour les colonnes de chaîne, car ils seront VARCHAR (8000) par défaut. Vérifiez les types de données déduits.
- Si votre requête cible des fichiers CSV, envisagez de créer des statistiques.
- Pour optimiser votre requête, consultez Bonnes pratiques concernant les performances du pool SQL serverless.
Délai d'attente de requête expiré
L’erreur Query timeout expired est retournée si la requête s’est exécutée pendant plus de 30 minutes sur un pool SQL serverless. Cette limite pour le pool SQL serverless ne peut pas être changée.
- Essayez d’optimiser votre requête en appliquant les bonnes pratiques.
- Essayez de matérialiser des parties de vos requêtes en utilisant CETAS (Create External Table As Select).
- Vérifiez s’il existe une autre charge de travail simultanée en cours d’exécution sur le pool SQL serverless, car les autres requêtes peuvent accaparer les ressources. Dans ce cas, vous pouvez diviser la charge de travail sur plusieurs espaces de travail.
Nom d’objet non valide
L’erreur Invalid object name 'table name' indique que vous utilisez un objet, tel qu’une table ou une vue, qui n’existe pas dans la base de données du pool SQL serverless. Essayez ces options :
Listez les tables ou les vues, et vérifiez si l’objet existe. Utilisez SQL Server Management Studio ou Visual Studio Code, car Synapse Studio peut afficher certaines tables qui ne sont pas disponibles dans le pool SQL serverless.
Si vous voyez l’objet, vérifiez que vous utilisez un classement de base de données respectant la casse/binaire. Le nom de l’objet peut ne pas correspondre au nom que vous avez utilisé dans la requête. Avec un classement de base de données binaire,
Employeeetemployeesont deux objets différents.Si vous ne voyez pas l’objet, vous essayez peut-être d’interroger une table d’une base de données Lake ou Spark. La table peut ne pas être disponible dans le pool SQL serverless pour ces raisons :
- La table comporte des types de colonnes qui ne peuvent pas être représentés dans le pool SQL serverless.
- La table a un format qui n’est pas pris en charge dans un pool SQL serverless. Avro ou ORC sont des exemples.
Les données de type chaîne ou binaire sont tronquées
Cette erreur se produit si la longueur de votre type de colonne binaire ou de chaîne (par exemple VARCHAR, VARBINARY ou NVARCHAR) est inférieure à la taille réelle des données que vous lisez. Vous pouvez corriger cette erreur en augmentant la longueur du type de colonne :
- Si votre colonne de chaîne est définie comme type
VARCHAR(32)et que le texte contient 60 caractères, utilisez le typeVARCHAR(60)(ou plus long) dans votre schéma de colonne. - Si vous utilisez l’inférence de schéma (sans le schéma
WITH), toutes les colonnes de chaîne sont automatiquement définies en tant que typeVARCHAR(8000). Si vous obtenez cette erreur, définissez explicitement le schéma dans une clauseWITHavec le type de colonneVARCHAR(MAX)plus grand pour résoudre cette erreur. - Si votre table se trouve dans la base de données Lake, essayez d’augmenter la taille de la colonne de chaîne dans le pool Spark.
- Essayez la commande
SET ANSI_WARNINGS OFFpour activer le pool SQL serverless afin de tronquer automatiquement les valeurs VARCHAR, si cela n’a pas d’impact sur vos fonctionnalités.
Ouvrez les guillemets après la chaîne de caractères
Dans de rares cas, si vous utilisez l’opérateur LIKE sur une colonne de chaîne ou une comparaison avec les littéraux de chaîne, vous pouvez obtenir l’erreur suivante :
Unclosed quotation mark after the character string
Cette erreur peut se produire si vous utilisez le classement Latin1_General_100_BIN2_UTF8 sur la colonne. Essayez de définir le classement Latin1_General_100_CI_AS_SC_UTF8 sur la colonne au lieu du classement Latin1_General_100_BIN2_UTF8 pour résoudre le problème. Si l’erreur persiste, déclenchez une demande de support via le Portail Azure.
Impossible d’allouer de l’espace tempdb lors du transfert de données d’une distribution à une autre
L’erreur Could not allocate tempdb space while transferring data from one distribution to anotherest renvoyée lorsque le moteur d'exécution des requêtes ne peut pas traiter les données et les transférer entre les nœuds qui exécutent la requête. C’est un cas spécifique de l’erreur générique La requête échoue, car elle ne peut pas être exécutée en raison de contraintes de ressources. Cette erreur est retournée quand les ressources allouées à la base de données tempdb sont insuffisantes pour exécuter la requête.
Appliquez les bonnes pratiques avant d’envoyer un ticket de support.
La requête échoue avec une erreur lors de la gestion d’un fichier externe (nombre maximal d’erreurs atteint)
Si votre requête échoue avec le message d’erreur error handling external file: Max errors count reached, cela signifie qu’il existe une incompatibilité entre un type de colonne spécifié et les données à charger.
Pour obtenir plus d’informations sur l’erreur, et sur quelles les lignes et colonnes examiner, changez la version de l’analyseur de 2.0 en 1.0.
Exemple
Si vous voulez interroger le fichier names.csv avec cette Requête 1, le pool SQL serverless Azure Synapse retourne l’erreur suivante :Error handling external file: 'Max error count reached'. File/External table name: [filepath]. Par exemple :
Le fichier names.csv contient :
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Requête 1 :
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Cause
Dès que la version de l’analyseur passe de la version 2.0 à la version 1.0, les messages d’erreur permettent d’identifier le problème. Le nouveau message d’erreur est désormais Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
La troncation vous indique que le type de colonne est trop petit pour contenir nos données. Le prénom le plus long dans ce fichier names.csv comporte sept caractères. Le type de données à utiliser doit donc être au moins VARCHAR(7). L’erreur est provoquée par cette ligne de code :
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
La modification de la requête en conséquence résout l’erreur. Après le débogage, changez la version de l’analyseur en 2.0 pour obtenir les performances maximales.
Pour plus d’informations sur quand utiliser quelle version de l’analyseur, consultez Utiliser OPENROWSET avec un pool SQL serverless dans Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Chargement en masse impossible, car le fichier est impossible à ouvrir
L’erreur Cannot bulk load because the file could not be openedest renvoyée si un fichier est modifié lors de l’exécution de la requête. Souvent, vous risquez d’obtenir une erreur telle que Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Les pools SQL serverless ne peuvent pas lire les fichiers qui sont modifiés pendant l’exécution de la requête. La requête ne peut pas prendre un verrou sur les fichiers. Si vous savez que l’opération de modification est ajouter, vous pouvez essayer de définir l’option suivante :{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Pour plus d’informations, découvrez comment interroger des fichiers en ajout seul ou créer des tables sur des fichiers en ajout seul.
Échec de la requête avec une erreur de conversion de données
Votre requête peut échouer avec le message d'erreur Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath].Ce message signifie que vos types de données ne correspondent pas aux données réelles pour la ligne numéro n et la colonne m.
Par exemple, si vous attendez seulement des entiers dans vos données, mais que dans la ligne n, il y a une chaîne, c’est le message d’erreur que vous recevez.
Pour résoudre ce problème, inspectez le fichier et les types de données que vous avez choisis. Vérifiez également si vos paramètres de délimiteur de ligne et de marque de fin de champ sont corrects. L’exemple suivant montre comment l’inspection peut être effectuée en utilisant VARCHAR comme type de colonne.
Pour plus d’informations sur les marques de fin de champ, les délimiteurs de ligne et les caractères d’échappement, consultez Interroger des fichiers CSV.
Exemple
Si vous voulez interroger le fichier names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Avec la requête suivante :
Requête 1 :
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse pool SQL serverless retourne l’erreurBulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Il est nécessaire de parcourir les données et de prendre une décision en connaissance de cause pour traiter ce problème. Avant d’examiner les données à l’origine de ce problème, vous devez modifier le type de données. Au lieu d’interroger la colonne ID avec le type de données SMALLINT, VARCHAR(100) est maintenant utilisé pour analyser ce problème.
Avec cette Requête 2 légèrement modifiée, vous pouvez maintenant traiter les données pour retourner la liste des noms.
Requête 2 :
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Vous pourriez constater que les données comportent des valeurs inattendues pour l’ID sur la cinquième ligne. Dans de telles circonstances, il est important de s’accorder avec le propriétaire métier des données sur la manière d’éviter les données endommagées comme dans cet exemple. Si la prévention n’est pas possible au niveau de l’application, une taille raisonnable de VARCHAR peut être ici la seule option.
Conseil
Essayez de raccourcir VARCHAR() autant que possible. Évitez VARCHAR(MAX) si possible, car cela peut nuire aux performances.
Le résultat de la requête ne se présente pas comme prévu
Votre requête peut ne pas échouer, mais vous pouvez voir que votre jeu de résultats n’est pas ce qui était prévu. Les colonnes résultantes peuvent être vides ou des données inattendues peuvent être retournées. Dans ce scénario, il est probable qu’un délimiteur de ligne ou une marque de fin de champ ait été choisi de façon incorrecte.
Pour résoudre ce problème, il est nécessaire de réexaminer les données et de modifier ces paramètres. Le débogage de cette requête est facile, comme illustré dans l’exemple suivant.
Exemple
Si vous souhaitez interroger le fichier names.csv avec la requête dans Requête 1, le pool SQL serverless Azure Synapse retourne un résultat étrange :
Dans names.csv :
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Il semble ne pas y avoir de valeur dans la colonne Firstname. Au lieu de cela, toutes les valeurs ont fini par se retrouver dans la colonne ID. Ces valeurs sont séparées par une virgule. Le problème a été provoqué par cette ligne de code, car il est nécessaire de choisir la virgule comme marque de fin de champ au lieu du symbole de point-virgule :
FIELDTERMINATOR =';',
Pour résoudre le problème, il suffit de modifier ce caractère unique :
FIELDTERMINATOR =',',
Le jeu de résultats créé par Requête 2 se présente maintenant comme prévu :
Requête 2 :
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Retourne les informations suivantes :
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
La colonne de type n’est pas compatible avec le type de données externe
Si votre requête échoue avec le message d'erreurColumn [column-name] of type [type-name] is not compatible with external data type […], il est probable qu'un type de données PARQUET a été mappé à un type de données SQL incorrect.
Par exemple, si votre fichier Parquet contient une colonne de prix avec des nombres à virgule flottante (par exemple « 12,89 ») et que vous avez essayé de la mapper à INT, c’est le message d’erreur que vous recevrez.
Pour résoudre ce problème, examinez le fichier et les types de données que vous avez choisis. Cette table de mappage permet de choisir un type de données SQL correct. À titre de bonne pratique, spécifiez un mappage seulement pour les colonnes qui sans cela se résoudraient en un type de données VARCHAR. Éviter VARCHAR quand c’est possible permet d’améliorer les performances des requêtes.
Exemple
Si vous voulez interroger le fichier taxi-data.parquet avec cette Requête 1, le pool SQL serverless Azure Synapse retourne l’erreur suivante :
Le fichier taxi-data.parquetcontient :
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Requête 1 :
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Ce message d’erreur vous indique que les types de données ne sont pas compatibles et s’accompagne de la suggestion d’utiliser FLOAT au lieu de INT. L’erreur est provoquée par cette ligne de code :
SumTripDistance INT,
Si vous utilisez cette Requête 2 légèrement modifiée, les données peuvent maintenant être traitées et montrer les trois colonnes :
Requête 2 :
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
La requête fait référence à un objet qui n’est pas pris en charge en mode de traitement distribué
L’erreur The query references an object that is not supported in distributed processing mode indique que vous avez utilisé un objet ou une fonction qui ne peut pas l’être lors de l’interrogation des données dans Stockage Azure ou dans le stockage analytique Azure Cosmos DB.
Certains objets, comme les vues système, et certaines fonctions ne peuvent pas être utilisés lors de l’interrogation de données stockées dans Azure Data Lake ou dans le stockage analytique Azure Cosmos DB. Évitez d’utiliser des requêtes qui joignent des données externes à des vues système. Chargez les données externes dans une table temporaire ou utilisez des fonctions de sécurité ou de métadonnées pour filtrer les données externes.
Échec de l’appel WaitIOCompletion
Le message d’erreur WaitIOCompletion call failed indique que la requête a échoué lors de l’attente de l’exécution d’une opération d’E/S qui lit des données à partir du stockage distant, Azure Data Lake.
Le message d’erreur se présente comme suit :Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Assurez-vous que votre stockage se trouve dans la même région que le pool SQL serverless. Vérifiez les métriques de stockage et qu’aucune autre charge de travail sur la couche de stockage, comme le chargement de nouveaux fichiers, ne peut saturer les demandes d’E/S.
Le champ HRESULT contient le code du résultat. Voici les codes d’erreur les plus courants avec leurs solutions potentielles.
Ce code d’erreur signifie que le fichier source n’est pas dans le stockage.
Il y a plusieurs raisons pour lesquelles ce code d'erreur peut se produire :
- Le fichier a été supprimé par une autre application.
- Dans ce scénario courant, l’exécution de la requête démarre, elle énumère les fichiers et les fichiers sont trouvés. Plus tard, pendant l’exécution de la requête, un fichier est supprimé. Par exemple, il peut être supprimé par Databricks, Spark ou Azure Data Factory. La requête échoue, car le fichier est introuvable.
- Ce problème peut également se produire avec le format Delta. La requête peut échouer à nouveau, car il existe une nouvelle version de la table et le fichier supprimé n’est pas réinterrogé.
- Un plan d’exécution non valide mis en cache.
- Pour une atténuation temporaire, exécutez la commande
DBCC FREEPROCCACHE. Si le problème persiste, créez un ticket de support.
- Pour une atténuation temporaire, exécutez la commande
Syntaxe incorrecte près de NOT
L’erreur Incorrect syntax near 'NOT' indique qu’il existe des tables externes avec des colonnes contenant la contrainte NOT NULL dans la définition de colonne.
- Mettez à jour la table pour supprimer NOT NULL de la définition de colonne.
- Cette erreur peut parfois se produire de façon transitoire avec des tables créées à partir d’une instruction CETAS. Si le problème ne se résout pas, vous pouvez essayer de supprimer et de recréer la table externe.
La colonne de partitionnement renvoie des valeurs NULL
Si votre requête retourne des valeurs NULL au lieu de colonnes de partitionnement ou ne peut pas trouver les colonnes de partition, vous avez quelques étapes possibles de résolution du problème :
- Si vous utilisez des tables pour interroger un jeu de données partitionné, notez que les tables ne prennent pas en charge le partitionnement. Remplacez la table par les vues partitionnées.
- Si vous utilisez les vues partitionnées avec OPENROWSET qui interroge des fichiers partitionnés avec la fonction FILEPATH(), vérifiez que vous avez correctement spécifié le modèle de caractère générique à l’emplacement et que vous avez utilisé l’index approprié pour référencer le caractère générique.
- Si vous interrogez les fichiers directement dans le dossier partitionné, notez que les colonnes de partitionnement ne sont pas les composants des colonnes du fichier. Les valeurs de partitionnement sont placées dans les chemins aux dossiers, pas dans les fichiers. Pour cette raison, les fichiers ne contiennent pas les valeurs de partitionnement.
Échec de l’insertion d’une valeur dans le lot pour le type de colonne DATETIME2
L’erreur Inserting value to batch for column type DATETIME2 failed indique que le pool serverless ne peut pas lire les valeurs de date dans les fichiers sous-jacents. La valeur de DateHeure stockée dans le fichier Parquet ou Delta Lake ne peut pas être représentée en tant que colonne DATETIME2.
Recherchez la valeur minimale dans le fichier en utilisant Spark et vérifiez si certaines dates sont antérieures au 03-01-0001. Si vous avez stocké les fichiers en utilisant une version ultérieure de Spark utilisant toujours le format de stockage DateHeure hérité, les valeurs de DateHeure antérieures sont écrites en utilisant le calendrier julien, qui n’est pas aligné avec le calendrier grégorien proleptique utilisé dans les pools SQL serverless.
Il peut y avoir une différence de deux jours entre le calendrier Julien utilisé pour écrire les valeurs dans Parquet (dans certaines versions de Spark) et le calendrier Grégorien proleptique utilisé dans le pool SQL serverless. Cette différence peut entraîner une conversion vers une valeur de date négative, qui n’est pas valide.
Essayez d’utiliser Spark pour mettre à jour ces valeurs, car elles sont traitées comme des valeurs de date non valides dans SQL. L’exemple suivant montre comment mettre à jour les valeurs qui sont en dehors des plages de dates SQL sur NULL dans Delta Lake :
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Cette modification supprime les valeurs qui ne peuvent pas être représentées. Les autres valeurs de date peuvent être chargées correctement, mais elles ne sont pas représentées correctement, car il existe encore une différence entre le calendrier Julien et le calendrier Grégorien proleptique. Vous pouvez voir des décalages de dates inattendus, même pour les dates avant 1900-01-01, si vous utilisez Spark 3.0 ou des versions antérieures.
Envisagez de migrer vers Spark 3.1 ou version ultérieure et de basculer vers le calendrier grégorien proleptique. Les dernières versions de Spark utilisent par défaut un calendrier grégorien proleptique qui est aligné sur le calendrier dans le pool SQL serverless. Recharger vos données héritées avec la version ultérieure de Spark et utilisez le paramètre suivant pour corriger les dates :
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Échec de la requête en raison d’un échec de modification de la topologie ou du conteneur de calcul
Cette erreur peut indiquer qu’un problème de processus interne s’est produit dans le pool SQL serverless. Ouvrez un ticket de support avec tous les détails nécessaires susceptibles d’aider l’équipe du support technique Azure à investiguer le problème.
Décrivez tout ce qui paraît inhabituel relativement à la charge de travail normale. Par exemple, il y avait peut-être un grand nombre de requêtes simultanées, ou une charge de travail ou une requête spéciale qui a commencé à s’exécuter avant que cette erreur ne se produise.
Délai d’extension générique expiré
Comme décrit dans la section Interroger des dossiers et plusieurs fichiers, le pool SQL serverless prend en charge la lecture de plusieurs fichiers/dossiers à l’aide de caractères génériques. Le nombre maximal de caractères génériques par requête est 10. Vous devez savoir que cette fonctionnalité a un coût. Il faut du temps pour que le pool serverless répertorie tous les fichiers qui peuvent correspondre au caractère générique. Cela introduit une latence, et cette latence peut augmenter si le nombre de fichiers que vous essayez d’interroger est élevé. Dans ce cas, vous pourriez rencontrer l’erreur suivante :
"Wildcard expansion timed out after X seconds."
Vous pouvez effectuer plusieurs étapes d’atténuation pour éviter cela :
- Appliquez les meilleures pratiques décrites dans Meilleures pratiques pour les pools SQL serverless.
- Essayez de réduire le nombre de fichiers que vous essayez d’interroger en compactant les fichiers dans des fichiers plus volumineux. Essayez de conserver des tailles de fichiers supérieures à 100 Mo.
- Vérifiez que des filtres sur les colonnes de partitionnement sont utilisés dans la mesure du possible.
- Si vous utilisez le format de fichier delta, utilisez la fonctionnalité Optimiser l’écriture dans Spark. Cela peut améliorer les performances des requêtes en réduisant la quantité de données à lire et à traiter. L’utilisation de l’optimisation de l’écriture est décrite dans Utilisation d’Optimiser l’écriture sur Apache Spark.
- Pour éviter certains caractères génériques de niveau supérieur en décodant de fait en dur, les filtres implicites sur les colonnes de partitionnement utilisent du SQL dynamique.
Colonne manquante lors de l’utilisation de l’inférence automatique de schéma
Vous pouvez interroger facilement des fichiers sans connaître ou spécifier le schéma, en omettant la clause WITH. Dans ce cas, les noms de colonnes et les types de données seront inférés à partir des fichiers. N’oubliez pas que si vous lisez plusieurs fichiers à la fois, le schéma sera déduit du premier fichier que le service reçoit du stockage. Cela peut signifier que certaines des colonnes attendues seront omises, tout cela parce que le fichier utilisé par le service pour définir le schéma ne contenait pas ces colonnes. Pour spécifier explicitement le schéma, utilisez la clause OPENROWSET WITH. Si vous spécifiez le schéma (en utilisant une table externe ou une clause OPENROWSET WITH), le mode de chemin lax par défaut sera utilisé. Cela signifie que les colonnes qui n’existent pas dans certains fichiers sont retournées avec des valeurs Null (pour les lignes provenant de ces fichiers). Pour comprendre comment le mode de chemin est utilisé, consultez la documentation et l’exemple suivants.
Configuration
Les pools SQL serverless vous permettent d’utiliser T-SQL pour configurer des objets de base de données. Il existe quelques contraintes :
- Vous ne pouvez pas créer d’objets dans des bases de données
masteretlakehouseou Spark. - Vous devez disposer d’une clé principale pour créer des informations d’identification.
- Vous devez disposer de l’autorisation de référencer des données utilisées dans les objets.
Impossible de créer une base de données
Si vous obtenez cette erreurCREATE DATABASE failed. User database limit has been already reached., vous avez créé le nombre maximal de bases de données prises en charge dans un espace de travail. Pour plus d’informations, consultez Contraintes.
- Si vous devez séparer les objets, utilisez des schémas dans les bases de données.
- Si vous devez référencer le stockage Azure Data Lake, créez des bases de données Lake House ou des bases de données Spark qui seront synchronisées dans le pool SQL serverless.
Échec de la création ou de la modification d'une table, car la taille minimale des lignes de la table dépasse la taille maximale autorisée de 8 060 octets
Toute table peut avoir jusqu'à 8 Ko de taille par ligne (sans inclure les données VARCHAR(MAX)/VARBINARY(MAX)). Si vous créez une table dont la taille totale des cellules de la ligne dépasse 8060 octets, vous obtenez l'erreur suivante :
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Cette erreur peut également se produire dans la base de données Lake si vous créez une table Spark avec les tailles de colonne qui dépassent 8060 octets et que le pool SQL serverless ne peut pas créer une table qui référence les données de la table Spark.
En guise d'atténuation, évitez d'utiliser les types de taille fixe comme CHAR(N) et de les remplacer par des types de taille VARCHAR(N) variable, ou diminuez la taille en CHAR(N). Consultez Limitation de groupe de lignes de 8 Ko dans SQL Server.
Créez une clé principale dans la base de données ou ouvrez la clé principale dans la session avant d’effectuer cette opération.
Si votre requête échoue avec le message d’erreur Please create a master key in the database or open the master key in the session before performing this operation., cela signifie que votre base de données utilisateur n’a actuellement pas accès à une clé principale.
Vous avez probablement créé une base de données utilisateur et que vous n’avez pas encore créé de clé principale.
Pour résoudre ce problème, créez une clé principale avec la requête suivante :
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Remarque
Remplacez ici 'strongpasswordhere' par un autre secret.
L’instruction CREATE n’est pas prise en charge dans la base de données master
Si votre requête échoue avec le message d’erreur Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database., cela signifie que la base de données master masterdans le pool SQL serverless ne prend pas en charge la création des éléments suivants :
- Tables externes.
- Sources de données externes.
- Informations d’identification délimitées à la base de données.
- Formats de fichier externe.
Voici la solution :
Créer une base de données utilisateur :
CREATE DATABASE <DATABASE_NAME>Exécutez une instruction CREATE dans le contexte de <DATABASE_NAME> qui a échoué précédemment pour la base de données
master.Voici un exemple de création d’un format de fichier externe :
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Impossible de créer une connexion ou un utilisateur Microsoft Entra
Si vous recevez une erreur lorsque vous essayez de créer une connexion Microsoft Entra ou un utilisateur dans une base de données, vérifiez la connexion que vous avez utilisée pour vous connecter à votre base de données. La connexion qui tente de créer un utilisateur Microsoft Entra doit avoir l’autorisation d’accéder au domaine Microsoft Entra et vérifier si l’utilisateur existe. Sachez que :
- Les connexions SQL n’ont pas cette autorisation : vous recevrez donc toujours cette erreur si vous utilisez l’authentification SQL.
- Si vous utilisez une connexion Microsoft Entra pour créer de nouvelles connexions, vérifiez si vous êtes autorisé à accéder au domaine Microsoft Entra.
Azure Cosmos DB
Les pools SQL serverless vous permettent d’interroger un stockage analytique Cosmos DB en utilisant la fonction OPENROWSET. Vérifiez que votre conteneur Azure Cosmos DB a un stockage analytique. Vérifiez que vous avez correctement spécifié le compte, la base de données et le nom du conteneur. Vérifiez aussi que la clé de votre compte Azure Cosmos DB est valide. Pour plus d’informations, consultez Prérequis.
Impossible d’interroger Azure Cosmos DB en utilisant la fonction OPENROWSET
Si vous ne pouvez pas vous connecter à votre compte Azure Cosmos DB, vérifiez les prérequis. Les erreurs possibles et les actions de résolution des problèmes sont répertoriées dans le tableau suivant.
| Error | Cause racine |
|---|---|
| Erreurs de syntaxe : - Syntaxe incorrecte près de OPENROWSET.- ... n’est pas une option reconnue du fournisseur BULK OPENROWSET.- Syntaxe incorrecte près de .... |
Causes principales possibles : - Azure Cosmos DB n’est pas utilisé comme premier paramètre. - Utilise un littéral de chaîne au lieu d’un identificateur dans le troisième paramètre, - Ne spécifie pas le troisième paramètre (nom de conteneur). |
| Il y avait une erreur dans la chaîne de connexion Azure Cosmos DB. | -Le compte, la base de données ou la clé n’est pas spécifié(e), - Une option dans une chaîne de connexion n’est pas reconnue. - Un point-virgule ; est placé à la fin d’une chaîne de connexion. |
| La résolution du chemin d’Azure Cosmos DB a échoué avec l’erreur « Nom de compte incorrect » ou « Nom de base de données incorrect ». | Le nom de compte, le nom de la base de données ou le conteneur spécifié est introuvable, ou le stockage analytique n’a pas été activé pour la collection spécifiée. |
| La résolution du chemin Azure Cosmos DB a échoué avec l’erreur « Valeur de secret incorrecte » ou « Secret null ou vide ». | La clé du compte n’est pas valide ou est manquante. |
Un avertissement de classement UTF-8 est retourné lors de la lecture des types de chaîne Azure Cosmos DB
Le pool SQL serverless retourne un avertissement au moment de la compilation si le classement de la colonne OPENROWSET n’a pas d’encodage UTF-8. Vous pouvez facilement modifier le classement par défaut pour toutes les fonctions OPENROWSET en cours d’exécution dans la base de données actuelle à l’aide de l’instruction T-SQL :
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Le classement Latin1_General_100_BIN2_UTF8 fournit les meilleurs résultats quand vous filtrez vos données en utilisant des prédicats de chaîne.
Lignes manquantes dans le magasin analytique Azure Cosmos DB
Certains éléments d’Azure Cosmos DB peuvent ne pas être retournés par la fonction OPENROWSET. Sachez que :
- Il existe un délai de synchronisation entre le magasin transactionnel et le magasin analytique. Le document que vous avez entré dans le magasin transactionnel Azure Cosmos DB peut apparaître dans le magasin analytique au bout de 2 à 3 minutes.
- Le document peut enfreindre certaines contraintes de schéma.
La requête retourne des valeurs NULL dans certains éléments Azure Cosmos DB
Azure Synapse SQL retourne NULL à la place des valeurs que vous voyez dans le magasin des transactions dans les cas suivants :
- Il existe un délai de synchronisation entre le magasin transactionnel et le magasin analytique. La valeur que vous avez entrée dans le magasin transactionnel Azure Cosmos DB peut apparaître dans le magasin analytique au bout de 2 à 3 minutes.
- Il peut y avoir un nom de colonne ou une expression de chemin incorrects dans la clause WITH. Le nom de colonne (ou l’expression de chemin après le type de colonne) dans la clause WITH doit correspondre aux noms de propriété dans la collection Azure Cosmos DB. La comparaison respecte la casse. Par exemple,
productCodeetProductCodesont des propriétés différentes. Vérifiez que les noms de colonne correspondent exactement aux noms de propriété d’Azure Cosmos DB. - La propriété ne peut pas être déplacée vers le stockage analytique, car elle enfreint certaines contraintes de schéma : par exemple, il y a plus de 1 000 propriétés ou plus de 127 niveaux d’imbrication.
- Si vous utilisez une représentation de schéma bien définie, la valeur dans le magasin transactionnel peut avoir un type incorrect. Un schéma bien défini verrouille les types pour chaque propriété en échantillonnant les documents. Toute valeur ajoutée dans le magasin transactionnel qui ne correspond pas au type est traitée comme une valeur incorrecte et n’est pas migrée vers le magasin analytique.
- Si vous utilisez la représentation de schéma de fidélité optimale, veillez à ajouter le suffixe du type après le nom de la propriété, par exemple
$.price.int64. Si vous ne voyez pas de valeur pour le chemin référencé, elle est peut-être stockée sous un autre chemin de type, par exemple$.price.float64. Pour plus d’informations, consultez Interroger les collections de bases de données Azure Cosmos DB dans le schéma de fidélité complète.
La colonne n’est pas compatible avec le type de données externe
L’erreurColumn 'column name' of the type 'type name' is not compatible with the external data type 'type name'. est renvoyée si le type de colonne spécifié dans la clause WITH ne correspond pas au type dans le conteneur Azure Cosmos DB. Essayez de changer le type de colonne comme décrit dans la section Mappages des types Azure Cosmos DB à SQL ou utilisez le type VARCHAR.
Résoudre : le chemin d’accès Azure Cosmos DB a échoué avec une erreur
Si vous obtenez l'erreurResolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. vérifiez si vous avez utilisé des points de terminaison privés dans Azure Cosmos DB. Pour permettre à un pool SQL serverless d’accéder à un magasin analytique avec des points de terminaison privés, vous devez configurer des points de terminaison privés pour le magasin analytique Azure Cosmos DB.
Problèmes de performances d’Azure Cosmos DB
Si vous rencontrez des problèmes de performances inattendus, vérifiez que vous avez appliqué les bonnes pratiques, y compris :
- Vérifiez que vous avez placé l’application cliente, le pool serverless et le stockage analytique Azure Cosmos DB dans la même région.
- Vérifiez que vous utilisez la clause WITH avec des types de données optimaux.
- Vérifiez que vous utilisez le classement Latin1_General_100_BIN2_UTF8 quand vous filtrez vos données en utilisant des prédicats de chaîne.
- En présence de requêtes répétitives susceptibles d’être mises en cache, essayez d’utiliser CETAS pour stocker les résultats des requêtes dans Azure Data Lake Storage.
Delta Lake
Il existe des limitations que vous risquez de constater dans la prise en charge de Delta Lake dans les pools SQL serverless :
- Vérifiez que vous référencez le dossier Delta Lake racine dans la fonction OPENROWSET ou l’emplacement de la table externe.
- Le dossier racine doit contenir un sous-dossier nommé
_delta_log. La requête échoue s’il n’y a pas de dossier_delta_log. Si vous ne voyez pas ce dossier, c’est que vous référencez des fichiers Parquet bruts qui doivent être convertis au format Delta Lake en utilisant des pools Apache Spark. - Ne spécifiez pas de caractères génériques pour décrire le schéma de partition. La requête Delta Lake identifie automatiquement les partitions Delta Lake.
- Le dossier racine doit contenir un sous-dossier nommé
- Les tables Delta Lake créées dans les pools Apache Spark sont automatiquement disponibles dans le pool SQL serverless, mais le schéma n’est pas mis à jour (limitation de la préversion publique). Si vous ajoutez des colonnes dans la table Delta à l’aide d’un pool Spark, les modifications ne s’affichent pas dans la base de données du pool SQL serverless.
- Les tables externes ne prennent pas en charge le partitionnement. Utilisez des vues partitionnées dans le dossier Delta Lake pour exploiter l’élimination des partitions. Consultez problèmes connus et solutions de contournement plus loin dans cet article.
- Les pools SQL serverless ne prennent pas en charge les requêtes de voyage dans le temps. Utilisez des pools Apache Spark dans Synapse Analytics pour lire des données d’historique.
- Les pools SQL serverless ne prennent pas en charge la mise à jour des fichiers Delta Lake. Vous pouvez utiliser un pool SQL serverless pour interroger la dernière version de Delta Lake. Utilisez des pools Apache Spark dans Synapse Analytics pour mettre à jour Delta Lake.
- Vous ne pouvez pas stocker les résultats des requêtes dans le stockage au format Delta Lake en utilisant la commande CETAS (Create external table as select). La commande CETAS prend uniquement en charge Parquet et CSV en tant que formats de sortie.
- Les pools SQL serverless dans Synapse Analytics sont compatibles avec le lecteur Delta version 1.
- Les pools SQL serverless dans Synapse Analytics ne prennent pas en charge les jeux de données avec le filtre BLOOM. Le pool SQL serverless ignore les filtres BLOOM.
- La prise en charge de Delta Lake n’est pas disponible dans les pools SQL dédiés. Veillez à utiliser des pools SQL serverless pour interroger des fichiers Delta Lake.
- Pour plus d’informations sur les problèmes connus liés aux pools SQL serverless, consultez Problèmes connus Azure Synapse Analytics.
Prise en charge serverless de Delta version 1.0
Les pools SQL serverless lisent seulement Delta Lake version 1.0. Les pools SQL serverless sont des lecteurs Delta de niveau 1 et ne prennent pas en charge les fonctionnalités suivantes :
- Les mappages de colonnes sont ignorés : les pools SQL serverless retournent les noms de colonne d’origine.
- Les vecteurs de suppression sont ignorés et l’ancienne version des lignes supprimées/mises à jour est retournée (résultats possiblement incorrects).
- Les fonctionnalités Delta Lake suivantes ne sont pas prises en charge : points de contrôle V2, horodatage sans fuseau horaire, vérification du protocole VACUUM.
Les vecteurs de suppression sont ignorés.
Si votre table Delta Lake est configurée pour utiliser l’enregistreur Delta version 7, elle va stocker les lignes supprimées et les anciennes versions des lignes mises à jour dans des vecteurs de suppression. Comme les pools SQL serverless ont un lecteur Delta de niveau 1, ils vont ignorer les vecteurs de suppression et produire probablement des résultats incorrects lors de la lecture de la version de Delta Lake non prise en charge.
Le renommage d’une colonne dans la table Delta n’est pas pris en charge
Le pool SQL serverless ne prend pas en charge l’interrogation des tables Delta Lake avec les colonnes renommées. Le pool SQL serverless ne peut pas lire les données de la colonne renommée.
La valeur d’une colonne dans la table Delta est NULLE
Si vous utilisez un jeu de données Delta qui nécessite un lecteur Delta version 2 ou ultérieure et utilise les fonctionnalités non prises en charge dans la version 1 (par exemple, le changement de noms de colonnes, l’annulation de colonnes ou le mappage de colonnes), les valeurs des colonnes référencées risquent de ne pas s’afficher.
Le texte JSON n’est pas mis en forme correctement
Cette erreur indique que le pool SQL serverless ne peut pas lire le journal des transactions Delta Lake. Vous verrez probablement l’erreur suivante :
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Vérifiez que votre jeu de données Delta Lake n’est pas endommagé. Vérifiez que vous pouvez lire le contenu du dossier Delta Lake en utilisant le pool Apache Spark dans Azure Synapse. De cette façon, vous serez sûr que le fichier _delta_log n’est pas endommagé.
Solution de contournement
Essayez de créer un point de contrôle sur le jeu de données Delta Lake en utilisant le pool Apache Spark, puis réexécutez la requête. Le point de contrôle agrège les fichiers journaux JSON transactionnels et peut résoudre le problème.
Si le jeu de données est valide, créez un ticket de support et fournissez plus d’informations :
- N’apportez pas de modifications, comme ajouter/supprimer des colonnes ou optimiser la table, car cette opération peut modifier l’état des fichiers du journal des transactions Delta Lake.
- Copiez le contenu du dossier
_delta_logdans un nouveau dossier vide. Ne copiez pas les fichiers.parquet data. - Essayez de lire le contenu que vous avez copié dans le nouveau dossier et vérifiez que vous obtenez la même erreur.
- Envoyez le contenu du fichier copié
_delta_logau support Azure.
Vous pouvez maintenant continuer à utiliser le dossier Delta Lake avec le pool Spark. Vous fournirez les données copiées au support Microsoft si vous êtes autorisé à partager ces informations. L’équipe Azure va examiner le contenu du fichier delta_log, et fournir plus d’informations sur les erreurs possibles et les solutions de contournement.
Résoudre les journaux Delta qui ont échoué
L’erreur suivante indique que le pool SQL serverless ne peut pas résoudre les journaux Delta : Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. la cause la plus courante est que last_checkpoint_file dans le dossier _delta_log est supérieur à 200 octets en raison du champ checkpointSchema ajouté dans Spark 3.3.
Deux options sont disponibles pour contourner cette erreur :
- Modifiez la configuration appropriée dans le notebook Spark et générez un nouveau point de contrôle pour que
last_checkpoint_filesoit recréé. Si vous utilisez Azure Databricks, la modification de la configuration est la suivante :spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Revenir à Spark 3.2.1.
Notre équipe d’ingénierie travaille actuellement à une prise en charge complète pour Spark 3.3.
La table Delta créée dans Spark n’est pas affichée dans le pool serverless
Remarque
La réplication des tables Delta créées dans Spark est toujours en préversion publique.
Si vous avez créé une table Delta dans Spark et qu’elle n’est pas affichée dans le pool SQL serverless, vérifiez les points suivants :
- Attendez un certain temps (généralement 30 secondes), car les tables Spark sont synchronisées avec retard.
- Si la table n’apparaît pas dans le pool SQL serverless après un certain temps, vérifiez le schéma de la table Spark Delta. Les tables Spark avec des types complexes ou les types qui ne sont pas pris en charge dans serverless ne sont pas disponibles. Essayez de créer une table Parquet Spark avec le même schéma dans une base de données de lac et vérifiez si cette table s’affiche dans le pool SQL serverless.
- Vérifiez que l’identité managée de l’espace de travail peut accéder au dossier Delta Lake référencé par la table. Le pool SQL serverless utilise l’identité managée de l’espace de travail pour obtenir les informations de colonne de table à partir du stockage afin de créer la table.
Base de données de lac
Les tables de base de données Lake créées à l’aide du concepteur Spark ou Synapse sont automatiquement disponibles dans le pool SQL serverless pour l’interrogation. Vous pouvez utiliser un pool SQL serverless pour interroger les tables Parquet, CSV et Delta Lake créées à l’aide du pool Spark, et ajouter d’autres schémas, des vues, des procédures, des fonctions table et des utilisateurs Microsoft Entra dans le rôle db_datareader à votre base de données Lake. Les problèmes possibles sont répertoriés dans cette section.
Une table créée dans Spark n’est pas disponible dans le pool serverless
Les tables créées peuvent ne pas être immédiatement disponibles dans le pool SQL serverless.
- Les tables seront disponibles dans des pools serverless après un certain délai. Vous devrez peut-être attendre 5 à 10 minutes après la création d’une table dans Spark pour la voir dans un pool SQL serverless.
- Seules les tables qui référencent les formats Parquet, CSV et Delta sont disponibles dans le pool SQL serverless. Les autres types de tables ne sont pas disponibles.
- Une table qui contient certains types de colonnes non pris en charge ne sera pas disponible dans le pool SQL serverless.
- L’accès aux tables Delta Lake dans les bases de données Lake est en préversion publique. Vérifiez les autres problèmes répertoriés dans cette section ou dans la section Delta Lake.
Une table externe créée dans Spark affiche des résultats inattendus dans un pool serverless
Il se peut qu’il y ait une incompatibilité entre la table externe Spark source et la table externe répliquée sur le pool serverless. Cela peut se produire si les fichiers utilisés lors de la création de tables externes Spark n’ont pas d’extensions. Pour obtenir les résultats appropriés, vérifiez que tous les fichiers ont une extension telle que .parquet.
L’opération n’est pas autorisée pour une base de données répliquée
Cette erreur est retournée si vous essayez de modifier une base de données Lake, de créer des tables externes, des sources de données externes, des informations d’identification étendues à la base de données ou d’autres objets dans votre base de données Lake. Ces objets peuvent être créés uniquement sur les bases de données SQL.
Les bases de données Lake sont répliquées à partir du pool Apache Spark et gérées par Apache Spark. Par conséquent, vous ne pouvez pas créer d’objets comme dans les bases de données SQL à l’aide du langage T-SQL.
Seules les opérations suivantes sont autorisées dans les bases de données de lac :
- Création, suppression ou modification des vues, des procédures et des fonctions iTVF (fonctions table inline) dans les schémas autres que
dbo. - Création et suppression des utilisateurs de base de données à partir de Microsoft Entra ID.
- Ajout ou suppression d’utilisateurs de base de données dans le schéma
db_datareader.
Les autres opérations ne sont pas autorisées dans les bases de données de lac.
Remarque
Si vous créez une vie, une procédure ou une fonction dans le schéma dbo (ou si vous omettez le schéma et si vous utilisez le schéma par défaut qui est généralement dbo), vous recevez le message d’erreur.
Les tables delta dans les bases de données Lake ne sont pas disponibles dans le pool SQL serverless
Assurez-vous que l’identité managée de votre espace de travail dispose d’un accès en lecture sur le stockage ADLS qui contient le dossier Delta. Le pool SQL serverless lit le schéma de table Delta Lake à partir des journaux Delta placés dans ADLS et utilise l’identité managée de l’espace de travail pour accéder aux journaux des transactions Delta.
Essayez de configurer une source de données dans certaines bases de données SQL, qui référence votre stockage Azure Data Lake à l’aide des informations d’identification de l’identité managée et essayez de créer une table externe en plus de la source de données avec identité managée pour confirmer qu’une table avec l’identité managée peut accéder à votre stockage.
Les tables Delta dans les bases de données Lake n’ont pas un schéma identique dans les pools Spark et serverless
Les pools SQL serverless vous permettent d’accéder aux tables Parquet, CSV et Delta créées dans une base de données Lake à l’aide du concepteur Spark ou Synapse. L’accès aux tables Delta est toujours en préversion publique. De plus, SQL serverless synchronise actuellement une table Delta avec Spark au moment de la création, mais ne met pas à jour le schéma si les colonnes sont ajoutées ultérieurement à l’aide de l’instruction ALTER TABLE dans Spark.
Il s’agit d’une limitation de la préversion publique. Pour résoudre ce problème, supprimez et recréez la table Delta dans Spark (si cela est possible) au lieu de modifier des tables.
Délai d’expiration de la requête ou détérioration des performances d’une table
Lorsque la table d’origine dans Spark ou Dataverse est modifiée, les tables correspondantes du pool serverless sont automatiquement recréées. Ce processus entraîne une suppression des statistiques existantes sur la table. Sans ces statistiques, les requêtes sur la table peuvent subir des retards ou même des délais d’expiration.
Si vous rencontrez ce problème, envisagez de mettre en place un travail pour recréer des statistiques sur les tables après des changements dans Spark/Dataverse ou à intervalles réguliers.
Performances
Le pool SQL serverless affecte les ressources aux requêtes en fonction de la taille du jeu données et de la complexité des requêtes. Vous ne pouvez pas changer ou limiter les ressources fournies aux requêtes. Dans certains cas, il se peut que vous rencontriez des dégradations de performances de requête inattendues et que vous deviez identifier les causes racines.
La durée des requêtes est très longue
Si vous avez des requêtes d’une durée supérieure à 30 minutes, cela indique que la requête retourne les résultats au client lentement. Le pool SQL serverless a une limite de 30 minutes pour l’exécution. Le temps supplémentaire est consacré au streaming des résultats. Essayez les solutions de contournement suivantes :
- Si vous utilisez Synapse Studio, essayez de reproduire les problèmes liés à une autre application comme SQL Server Management Studio ou Visual Studio Code.
- Si votre requête est lente lorsqu’elle est exécutée à l’aide de SQL Server Management Studio, de Visual Studio Code, de Power BI ou d’une autre application, vérifiez les problèmes de mise en réseau et les meilleures pratiques.
- Placez la requête dans la commande CETAS et mesurez la durée de la requête. La commande CETAS stocke les résultats dans Azure Data Lake Storage et ne dépend pas de la connexion du client. Si la commande CETAS se termine plus rapidement que la requête d’origine, vérifiez la bande passante réseau entre le client et le pool SQL serverless.
La requête est lente quand elle est exécutée en utilisant Synapse Studio
Si vous utilisez Synapse Studio, essayez d’utiliser un client de bureau tel que SQL Server Management Studio ou Visual Studio Code. Synapse Studio est un client web qui se connecte à un pool SQL serverless à l’aide du protocole HTTP, généralement plus lent que les connexions SQL natives utilisées dans SQL Server Management Studio ou Visual Studio Code.
La requête est lente quand elle est exécutée en utilisant une application
Si vous constatez un ralentissement de l’exécution des requêtes, vérifiez les points suivants :
- Assurez-vous que les applications clientes sont colocalisées avec le point de terminaison du pool SQL serverless. L’exécution d’une requête dans la région peut entraîner une latence supplémentaire et ralentir le streaming du jeu de résultats.
- Vérifiez que vous n’avez pas de problèmes de réseau susceptibles de provoquer un ralentissement du streaming du jeu de résultats.
- Veillez à ce que l’application cliente dispose de suffisamment de ressources (par exemple, en n’utilisant pas 100 % du processeur).
- Vérifiez que le compte de stockage ou le stockage analytique Azure Cosmos DB se trouve dans la même région que votre point de terminaison SQL serverless.
Consultez les bonnes pratiques pour colocaliser les ressources.
Variations élevées des durées des requêtes
Si vous exécutez la même requête et que vous observez des variations des durées des requêtes, ce comportement peut avoir plusieurs raisons :
- Vérifiez si c’est la première exécution d’une requête. La première exécution d’une requête collecte les statistiques nécessaires à la création d’un plan. Ces statistiques sont collectées en analysant les fichiers sous-jacents et peuvent allonger la durée de la requête. Dans Synapse Studio, vous verrez les requêtes de « création de statistiques globales » dans la liste des demandes SQL qui sont exécutées avant votre requête.
- Les statistiques peuvent expirer après un certain temps. Périodiquement, vous pouvez observer un impact sur les performances, car le pool serverless doit analyser et recréer les statistiques. Vous pouvez remarquer d’autres requêtes de « création de statistiques globales » dans la liste des demandes SQL, qui sont exécutées avant votre requête.
- Vérifiez si des charges de travail s’exécutent sur le même point de terminaison quand vous exécutez la requête avec la plus longue durée. Le point de terminaison SQL serverless alloue de manière égale les ressources à toutes les requêtes exécutées en parallèle, et la requête peut être retardée.
Connexions
Le pool SQL serverless vous permet de vous connecter en utilisant le protocole TDS et le langage T-SQL pour interroger les données. La plupart des outils qui peuvent se connecter à SQL Server ou à Azure SQL Database peuvent également se connecter à un pool SQL serverless.
Le pool SQL est en cours de préchauffage
Après une période d’inactivité plus longue, le pool SQL serverless est désactivé. L’activation se produit automatiquement lors de la première activité suivante, par exemple la première tentative de connexion. Le processus d’activation peut prendre un peu plus de temps qu’un seul intervalle de tentative de connexion : le message d’erreur s’affiche donc. Une nouvelle tentative de connexion devrait être suffisante.
Pour les clients qui le prennent en charge, il est recommandé d’utiliser les mots clés de chaîne de connexion ConnectionRetryCount et ConnectRetryInterval pour contrôler le comportement de reconnexion. La plupart des pilotes clients SQL ont le délai d’expiration de connexion par défaut défini sur 15 secondes. Vérifiez que le délai d’expiration de la connexion est configuré pour autoriser toutes les tentatives de nouvelle tentative. Par exemple, les valeurs choisies doivent satisfaire à la condition suivante : Connection Timeout > ConnectRetryCount * ConnectionRetryInterval.
Si le message d’erreur persiste, envoyez un ticket de support via le portail Azure.
Impossible de se connecter depuis Synapse Studio
Reportez-vous à la section Synapse Studio.
Impossible de se connecter au pool Azure Synapse depuis un outil
Certains outils peuvent ne pas disposer d’une option explicite qui vous permet de vous connecter au pool SQL serverless Azure Synapse. Utilisez une option que vous utiliseriez pour vous connecter à SQL Server ou à SQL Database. La boîte de dialogue de connexion n’a pas besoin d’être marquée en tant que « Synapse », car le pool SQL serverless utilise le même protocole que SQL Server ou SQL Database.
Même si un outil vous permet d’entrer seulement un nom de serveur logique et prédéfinit le domaine database.windows.net, placez le nom de l’espace de travail Azure Synapse suivi du suffixe -ondemand et du domaine database.windows.net.
Sécurité
Vérifiez qu’un utilisateur dispose des autorisations nécessaires pour accéder aux bases de données, des autorisations pour exécuter des commandes, et des autorisations pour accéder au stockage Data Lake ou Azure Cosmos DB.
Impossible d’accéder au compte Azure Cosmos DB
Vous devez utiliser une clé Azure Cosmos DB en lecture seule pour accéder à votre stockage analytique : vérifiez donc qu’elle n’a pas expiré ou qu’elle n’est pas regénérée.
Si vous recevez l’erreur « La résolution du chemin Azure Cosmos DB a échoué avec une erreur »,, vérifiez que vous avez configuré un pare-feu.
Impossible d’accéder à la base de données Lakehouse ou Spark
Si un utilisateur ne peut pas accéder à une base de données Lakehouse ou Spark, il se peut qu’il ne dispose pas des autorisations nécessaires pour accéder à la base de données et la lire. Un utilisateur disposant de l’autorisation CONTROL SERVER doit avoir un accès complet à toutes les bases de données. En tant qu’autorisation restreinte, vous pouvez essayer d’utiliser CONNECT ANY DATABASE et SELECT ALL USER SECURABLES.
L’utilisateur SQL ne peut pas accéder aux tables Dataverse
Les tables Dataverse accèdent au stockage à l’aide de l’identité Microsoft Entra de l’appelant. Un utilisateur SQL disposant d’autorisations élevées peut essayer de sélectionner des données dans une table, mais la table ne peut pas accéder aux données Dataverse. Ce scénario n’est pas pris en charge.
Échecs de connexion du principal du service Microsoft Entra lorsque SPI crée une attribution de rôle
Si vous souhaitez créer une attribution de rôle pour un identificateur de principal de service (SPI) ou une application Microsoft Entra à l’aide d’un autre SPI, ou si vous en avez déjà créé un et qu’il ne parvient pas à se connecter, vous recevrez probablement l’erreur suivante : Login error: Login failed for user '<token-identified principal>'.
Pour les principaux de service, la connexion doit être créée avec un ID d’application en tant qu’ID de sécurité (SID), et non pas avec un ID d’objet. Il existe une limitation connue pour les principaux de service qui empêche Azure Synapse de récupérer l’ID d’application auprès de Microsoft Graph lors de la création d’une attribution de rôle pour un autre SPI ou une autre application.
Solution 1
Accédez au portail Azure>Synapse Studio>Gérer>Contrôle d’accès et ajoutez manuellement Administrateur Synapse ou Administrateur Synapse SQL pour le principal de service souhaité.
Solution 2
Vous devez créer manuellement une connexion appropriée avec du code SQL :
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Solution 3
Vous pouvez aussi configurer un administrateur Azure Synapse du principal de service en utilisant PowerShell. Le module Az.Synapse doit être installé.
La solution doit utiliser la cmdlet New-AzSynapseRoleAssignment avec -ObjectId "parameter". Dans ce champ de paramètre, spécifiez l’ID d’application au lieu de l’ID d’objet en utilisant les informations d’identification du principal du service Azure de l’administrateur de l’espace de travail.
Script PowerShell :
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Remarque
Dans ce cas, l’interface utilisateur de Synapse Data Studio n’affichera pas l’attribution de rôle ajoutée par la méthode ci-dessus. Il est donc recommandé d’ajouter l’attribution de rôle à la fois à l’ID de l’objet et à l’ID de l’application en même temps afin qu’elle puisse être affichée sur l’interface utilisateur.
New-AzSynapseRoleAssignment -WorkspaceName « <workspaceName> » -RoleDefinitionName « Administrateur Synapse » -ObjectId « <object_id_to_add_as_admin> » [-Debug]
Validation
Connectez-vous au point de terminaison SQL sans serveur et vérifiez que le login externe avec SID (app_id_to_add_as_admin dans l'échantillon précédent) est créé :
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Ou, vous pouvez aussi essayer de vous connecter au point de terminaison SQL serverless en utilisant l’application d’administration que vous avez définie.
Contraintes
Certaines contraintes système générales peuvent affecter votre charge de travail :
| Propriété | Limitation |
|---|---|
| Nombre maximal d’espaces de travail Azure Synapse par abonnement | Consultez Limites. |
| Nombre maximal de bases de données par pool serverless | 100 (sans compter les bases de données synchronisées depuis le pool Apache Spark). |
| Nombre maximal de bases de données synchronisées à partir du pool Apache Spark | Non limité. |
| Nombre maximal d’objets de bases de données par base de données | Au total, le nombre de tous les objets d’une base de données ne peut pas dépasser 2 147 483 647. Consultez Limitations du moteur de base de données SQL Server. |
| Longueur maximale de l’identificateur (en caractères) | 128. Consultez Limitations du moteur de base de données SQL Server. |
| Durée maximale des requêtes | 30 min. |
| Taille maximale du jeu de résultats | Jusqu’à 400 Go, partagés entre les requêtes simultanées. |
| Concurrence maximale | Non limitée et basée sur la complexité des requêtes et le volume de données analysées. Un pool SQL serverless peut traiter simultanément 1 000 sessions actives exécutant des requêtes légères. Les nombres diminuent si les requêtes sont plus complexes ou analysent une plus grande quantité de données ; envisagez ainsi de réduire la concurrence et d’exécuter des requêtes sur une période plus longue si possible. |
| Taille maximale du nom de la table externe | 100 caractères. |
Impossible de créer une base de données dans un pool SQL serverless
Les pools SQL serverless ont des limites, et vous ne pouvez pas créer plus de 100 bases de données par espace de travail. Si vous devez séparer des objets et les isoler, utilisez des schémas.
Si vous obtenez cette erreurCREATE DATABASE failed. User database limit has been already reached, vous avez créé le nombre maximal de bases de données prises en charge dans un espace de travail.
Vous n’avez pas besoin d’utiliser des bases de données distinctes pour isoler les données de différents locataires. Toutes les données sont stockées en externe sur une instance Data Lake et Azure Cosmos DB. Les métadonnées, comme les tables, les vues et les définitions de fonction, peuvent être isolées en utilisant des schémas. L’isolement basé sur un schéma est également utilisé dans Spark, où les bases de données et les schémas sont les mêmes concepts.