Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Dans ce didacticiel, vous apprendrez à effectuer une analyse exploratoire des données à l'aide d'ensembles de données ouverts existants, sans configuration de stockage requise. Vous combinez différents Azure Open Datasets à l’aide d’un pool SQL sans serveur. Vous visualisez ensuite les résultats dans Synapse Studio pour Azure Synapse Analytics.
Dans ce tutoriel, vous allez :
- Accédez au pool SQL serverless intégré
- Accédez à Azure Open Datasets pour utiliser les données du didacticiel
- Effectuez une analyse de données de base à l'aide de SQL
Accédez au pool sans serveur SQL
Chaque espace de travail est livré avec un pool SQL serverless préconfiguré que vous pouvez utiliser, appelé Built-in. Pour y accéder :
- Ouvrez votre espace de travail et sélectionnez le hub Développer.
- Sélectionnez le bouton +Ajouter une nouvelle ressource .
- Sélectionnez Script SQL.
Vous pouvez utiliser ce script pour explorer vos données sans avoir à réserver de capacité SQL.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Accédez aux données du tutoriel
Toutes les données que nous utilisons dans ce didacticiel sont hébergées dans le compte de stockage azureopendatastorage, qui contient des ensembles de données ouverts Azure pour une utilisation ouverte dans des didacticiels comme celui-ci. Vous pouvez exécuter tous les scripts tels quels directement depuis votre espace de travail tant que votre espace de travail peut accéder à un réseau public.
Ce tutoriel utilise un jeu de données sur New York City (NYC) Taxi :
- Dates et heures de début et de fin de trajet
- Emplacements de début et de fin de trajet
- Distance des trajets
- Tarifs détaillés
- Types de tarifs
- Types de paiement
- Nombre de passagers indiqué par le chauffeur
La fonction OPENROWSET(BULK...) vous permet d’accéder à des fichiers dans Stockage Azure.
[OPENROWSET](develop-openrowset.md) lit le contenu d’une source de données distante (par exemple, un fichier) et retourne le contenu sous la forme d’un ensemble de lignes.
Pour vous familiariser avec les données NYC Taxi, exécutez la requête suivante :
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
Autres Azure Open DataSets accessibles
De même, vous pouvez interroger le jeu de données sur les jours fériés à l’aide de la requête suivante :
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
Vous pouvez également interroger le jeu de données sur les données météorologiques à l’aide de la requête suivante :
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
Vous pouvez en savoir plus sur la signification des différentes colonnes dans les descriptions des jeux de données :
Inférence de schéma automatique
Étant donné que les données sont stockées au format de fichier Parquet, une inférence automatique de schéma est disponible. Il est donc possible d’interroger les données sans lister les types de données de toutes les colonnes dans les fichiers. Vous pouvez aussi utiliser le mécanisme de colonne virtuelle et la fonction filepath pour filtrer un certain sous-ensemble de fichiers.
Note
Le classement par défaut est SQL_Latin1_General_CP1_CI_ASIf. Pour un classement non par défaut, prenez en compte la sensibilité de la casse.
Si vous créez une base de données avec un classement respectant la casse, quand vous spécifiez des colonnes, veillez à utiliser le nom correct de ces dernières.
Un nom de colonne tpepPickupDateTime serait correct, alors que tpeppickupdatetime ne fonctionnerait pas dans un classement autre que celui par défaut.
Analyse des séries chronologiques, de la saisonnalité et des valeurs hors norme
Vous pouvez totaliser le nombre annuel de courses de taxi à l’aide de la requête suivante :
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
L’extrait de code suivant présente le résultat pour le nombre annuel de courses de taxi :
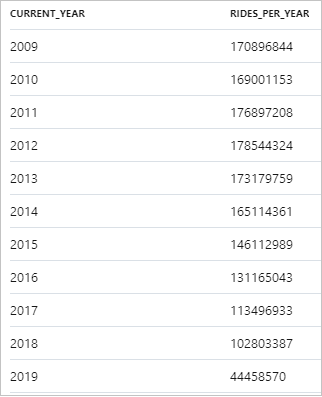
Vous pouvez visualiser les données dans Synapse Studio en passant de la vue Table à la vue Graphique. Vous pouvez choisir parmi différents types de graphiques, par exemple Aires, Barres, Histogramme, Courbes, Secteurs et Nuages de points. Dans le cas présent, tracez l’histogramme avec la colonne Category définie sur current_year :
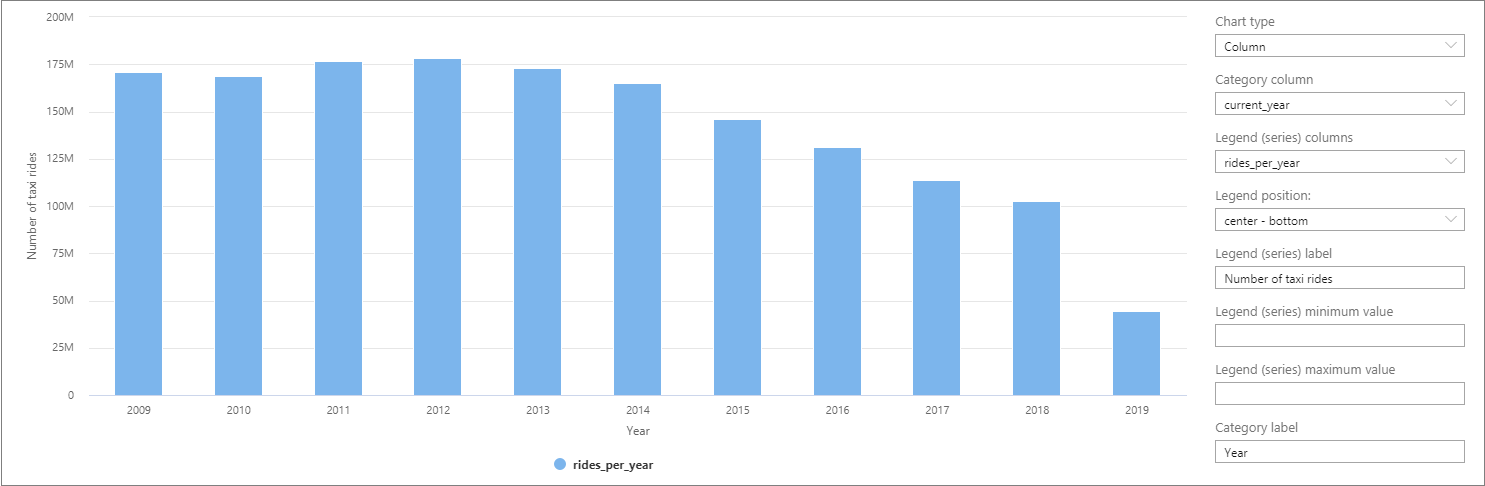
À partir de cette visualisation, vous pouvez voir une tendance à la baisse du nombre de trajets au cours des années. Cette baisse est vraisemblablement due à une augmentation récente du nombre d’entreprises de covoiturage.
Note
Au moment de la rédaction de ce tutoriel, les données pour 2019 sont incomplètes. Il en résulte une forte baisse du nombre de trajets pour cette année.
Vous pouvez concentrer l’analyse sur une seule année, par exemple, 2016. La requête suivante retourne le nombre quotidien de courses au cours de cette année :
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
L’extrait de code suivant présente le résultat de cette requête :
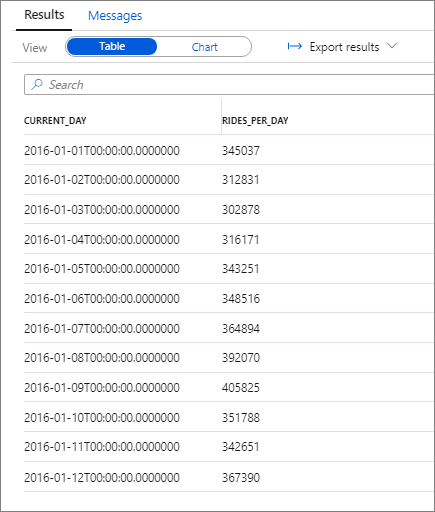
Là encore, vous pouvez visualiser les données en traçant l’histogramme avec la colonne Category définie sur current_day et la colonne Legend (series) définie sur rides_per_day.
La capture d'écran montre un graphique en colonnes qui affiche le nombre quotidien de trajets pour 2016.
Dans le graphique, vous pouvez voir qu’il existe un schéma hebdomadaire, où le samedi est le jour de pointe. Pendant les mois d’été, il y a moins de courses de taxi en raison des vacances. Notez également des baisses importantes du nombre de courses de taxi, sans schéma clair de quand et pourquoi elles se produisent.
Ensuite, voyons s’il existe une corrélation entre la baisse du nombre de courses et les jours fériés. Vérifiez s’il existe une corrélation en joignant le jeu de données sur les courses de taxi de la ville de New York au jeu de données sur les jours fériés :
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
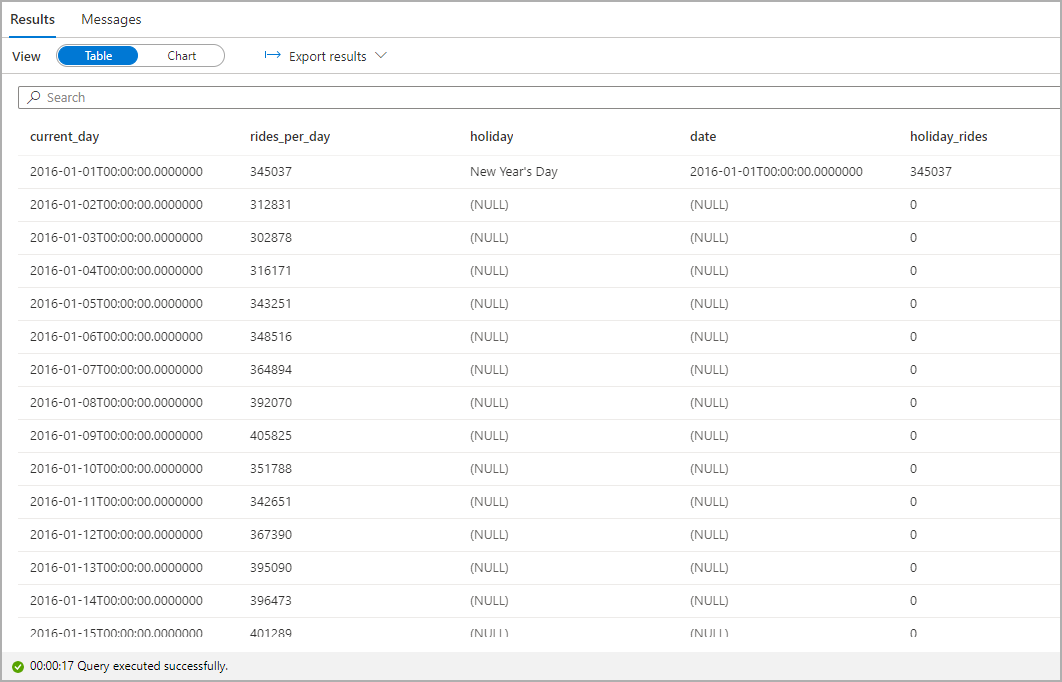
Mettez en surbrillance le nombre de courses de taxi pendant les jours fériés. Dans ce but, choisissez current_day pour la colonne Category, et rides_per_day et holiday_rides pour les colonnes Legend (series).
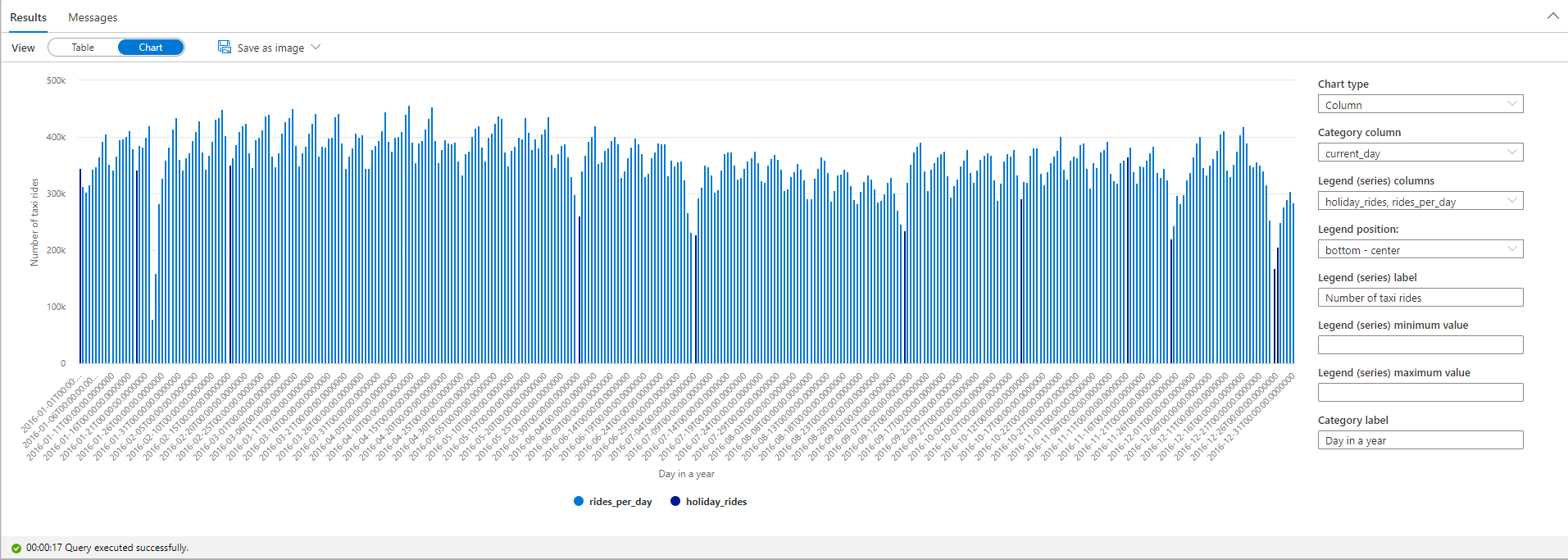
À partir du diagramme, vous pouvez voir que pendant les jours fériés, le nombre de trajets de taxi est plus faible. Il existe toujours une forte chute inexpliquée le 23 janvier. Vérifions la météo de ce jour-là à New York en interrogeant le jeu de données sur les données météorologiques :
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

Les résultats de la requête indiquent que la chute du nombre de courses de taxi était liée aux raisons suivantes :
- Il y avait du blizzard ce jour-là à New-York, avec de fortes chutes de neige (environ 30 cm).
- Il faisait froid (la température était inférieure à zéro degré Celsius).
- Il y avait du vent (environ 10 m/s).
Ce tutoriel a montré comment un analyste de données peut rapidement effectuer une analyse exploratoire des données. Vous pouvez combiner différents jeux de données à l’aide d’un pool SQL serverless et visualiser les résultats à l’aide d’Azure Synapse Studio.
Contenu connexe
Pour savoir comment connecter un pool SQL serverless à Power BI Desktop et créer des rapports, consultez Connecter un pool SQL serverless à Power BI Desktop et créer des rapports.
Pour découvrir comment utiliser des tables externes dans un pool SQL serverless, consultez Utiliser des tables externes avec Synapse SQL.