Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Le moteur d’exécution natif est une amélioration révolutionnaire pour les exécutions de travaux Apache Spark dans Microsoft Fabric. Ce moteur vectorisé optimise les performances et l’efficacité de vos requêtes Spark en les exécutant directement sur votre infrastructure lakehouse. L'intégration transparente du moteur signifie qu'il ne nécessite aucune modification de code et évite le verrouillage fournisseur. Il prend en charge les API Apache Spark et est compatible avec Runtime 1.3 (Apache Spark 3.5) et Runtime 2.0 (Apache Spark 4.1) et fonctionne avec des formats Parquet, Delta et CSV. Quel que soit l’emplacement de vos données dans OneLake ou si vous accédez aux données via des raccourcis, le moteur d’exécution natif optimise l’efficacité et les performances.
Le moteur d’exécution natif élève considérablement les performances des requêtes tout en réduisant les coûts opérationnels. Les résultats réels varient selon les caractéristiques et la configuration de la charge de travail. Le moteur est capable de gérer un large éventail de scénarios de traitement de données, allant de l’ingestion des données de routine, des travaux par lots et des tâches ETL (extraire, transformer, charger), à des analyses de science des données complexes et à des requêtes interactives réactives. Les utilisateurs bénéficient de temps de traitement accélérés, d’un débit accru et d’une utilisation optimisée des ressources.
Le moteur d’exécution natif est basé sur deux composants OSS clés : Velox, une bibliothèque d’accélération de base de données C++ introduite par Meta et Apache Gluten (en développement), une couche intermédiaire chargée du déchargement de l’exécution des moteurs SQL basés sur JVM sur des moteurs natifs introduits par Intel.
Les opérateurs pris en charge sont transférés de Spark basé sur la JVM vers un chemin d'exécution vectorisé en C++, fournissant un traitement en colonne accéléré par SIMD avec prise en charge native des formats Parquet et Delta. Le moteur natif conserve les principales optimisations de requêtes de Fabric Spark, notamment l’exécution de requêtes adaptatives (AQE), les réécritures basées sur les coûts, l'élagage des colonnes et le pushdown de prédicat, de sorte que ces comportements d’optimiseur restent entièrement actifs lorsque les opérateurs sont déchargés. Le moteur prend également en charge le chargement parallèle d’instantanés Delta et accélère les opérations qui tirent parti du Z-ordering et du Liquid Clustering sur les tables Delta, ce qui offre des gains de performance supplémentaires pour les dispositions de données organisées.
Quand utiliser le moteur d’exécution natif
Le moteur d’exécution natif offre une solution pour exécuter des requêtes sur des jeux de données à grande échelle ; il optimise les performances à l’aide des fonctionnalités natives des sources de données sous-jacentes et réduit la surcharge généralement associée au déplacement et à la sérialisation des données dans les environnements Spark traditionnels. Le moteur prend en charge différents opérateurs et types de données, notamment l’agrégation par hachage avec regroupement, la jointure de boucle imbriquée diffusée (BNLJ), et les formats d’horodatage précis. Toutefois, pour tirer pleinement parti des fonctionnalités du moteur, vous devez prendre en compte ses cas d’usage optimaux :
- Le moteur est efficace lors de l’utilisation de données dans des formats Parquet et Delta, qu’il peut traiter en mode natif et efficace.
- Les requêtes qui impliquent des transformations complexes et des agrégations bénéficient considérablement des fonctionnalités de traitement et de vectorisation en colonnes du moteur.
- L’amélioration des performances est la plus notable dans les scénarios où les requêtes ne déclenchent pas le mécanisme de secours en évitant les fonctionnalités ou expressions non prises en charge.
- Le moteur est bien adapté aux requêtes qui sont gourmandes en calcul, plutôt que simples ou liées aux E/S.
Pour plus d’informations sur les opérateurs et les fonctions pris en charge par le moteur d’exécution natif, consultez la documentation Apache Gluten.
Activer le moteur d’exécution natif
Pour utiliser les fonctionnalités complètes du moteur d’exécution natif pendant la phase d’aperçu, des configurations spécifiques sont nécessaires. Les procédures suivantes montrent comment activer cette fonctionnalité pour les notebooks, les définitions de travaux Spark et les environnements entiers.
Important
Le moteur d’exécution natif prend en charge Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2) et Runtime 2.0 (Apache Spark 4.1, Delta Lake 4.1).
Activer au niveau de l’environnement
Pour garantir une amélioration uniforme des performances, activez le moteur d’exécution natif sur tous les travaux et notebooks associés à votre environnement :
Accédez à l’espace de travail contenant votre environnement et sélectionnez l’environnement. Si vous n’avez pas d’environnement créé, consultez Créer, configurer et utiliser un environnement dans Fabric.
Sous Calcul Spark , sélectionnez Accélération.
Cochez la case intitulée Activer le moteur d’exécution natif.
Enregistrer et publier les modifications.
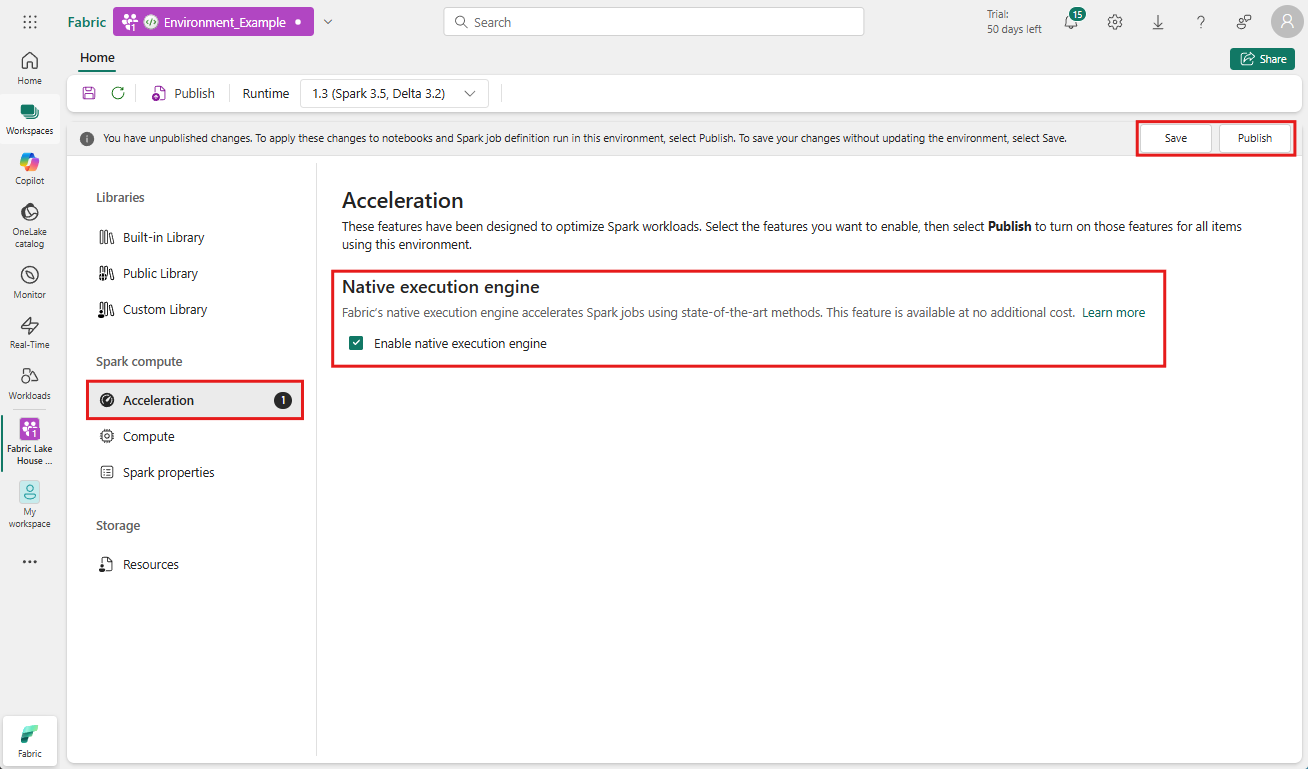

Lorsqu’ils sont activés au niveau de l’environnement, tous les travaux et notebooks suivants héritent du paramètre. Cet héritage garantit que toutes les nouvelles sessions ou ressources créées dans l’environnement bénéficient automatiquement des fonctionnalités d’exécution améliorées.
Important
Auparavant, le moteur d’exécution natif était activé via les paramètres Spark dans la configuration de l’environnement. Le moteur d’exécution natif peut désormais être activé plus facilement à l’aide d’un bouton bascule sous l’onglet Accélération des paramètres d’environnement. Pour poursuivre son utilisation, accédez à l'onglet Accélération et activez l'interrupteur. Vous pouvez également l’activer via les propriétés Spark si vous le souhaitez.
Activer l'option pour un notebook ou une définition de tâche Spark
Vous pouvez également activer le moteur d’exécution natif pour un seul notebook ou une définition de travail Spark, vous devez incorporer les configurations nécessaires au début de votre script d’exécution :
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Pour les carnets, insérez les commandes de configuration requises dans la première cellule. Pour les définitions de tâche Spark, incluez les configurations au début de votre définition de tâche Spark. Le moteur d’exécution natif est intégré aux pools dynamiques. Par conséquent, une fois que vous avez activé la fonctionnalité, elle prend effet immédiatement sans vous obliger à lancer une nouvelle session.
Contrôle au niveau de la requête
Les mécanismes permettant d’activer le moteur d’exécution natif au niveau du locataire, de l’espace de travail et de l’environnement, intégrés en toute transparence à l’interface utilisateur, sont en cours de développement. En attendant, vous pouvez désactiver le moteur d’exécution natif pour des requêtes spécifiques, en particulier s’ils impliquent des opérateurs qui ne sont pas actuellement pris en charge (voir limitations). Pour désactiver, définissez spark.native.enabled sur false pour la cellule spécifique contenant votre requête.
%%sql
SET spark.native.enabled=FALSE;

Après avoir exécuté la requête dans laquelle le moteur d’exécution natif est désactivé, vous devez le réactiver pour les cellules suivantes en définissant spark.native.enabled sur true. Cette étape est nécessaire, car Spark exécute des cellules de code de manière séquentielle.
%%sql
SET spark.native.enabled=TRUE;
Identifier les opérations exécutées par le moteur
Il existe plusieurs méthodes pour déterminer si un opérateur dans votre travail Apache Spark a été traité à l’aide du moteur d’exécution natif.
Interface utilisateur Spark et serveur d’historique Spark
Accédez au serveur d’historique Spark ou à l’interface utilisateur Spark pour localiser la requête que vous devez inspecter. Pour accéder à l’interface utilisateur web Spark, accédez à votre définition de travail Spark et exécutez-la. Dans l’onglet Exécutions, sélectionnez … en regard de Nom de l’application et sélectionnez Ouvrir l’interface utilisateur web de Spark. Vous pouvez également accéder à l’interface utilisateur Spark à partir de l’onglet Moniteur

Dans le plan de requête affiché dans l’interface utilisateur Spark, recherchez les noms de nœuds qui se terminent par le suffixe Transformer, *NativeFileScan ou VeloxColumnarToRowExec. Le suffixe indique que le moteur d’exécution natif a exécuté l’opération. Par exemple, les nœuds peuvent être étiquetés comme RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer, ou BroadcastNestedLoopJoinExecTransformer. Pour les sources de données CSV, les analyses natives peuvent apparaître en tant que nœuds d’analyse de fichiers ou de transformateurs natifs dans l’interface utilisateur Spark, comme les nœuds d’analyse Parquet et Delta.

Explication du DataFrame
Vous pouvez également exécuter la commande df.explain() dans votre notebook pour afficher le plan d'exécution. Dans la sortie, recherchez les mêmes suffixes Transformer, *NativeFileScan ou VeloxColumnarToRowExec. Cette méthode permet de vérifier rapidement si des opérations spécifiques sont gérées par le moteur d’exécution natif.

Alertes Fabric Spark Advisor
Fabric Spark Advisor fournit une visibilité sur les solutions de repli en temps réel pendant l'exécution de cellules dans le notebook. Lorsqu’un opérateur ou un segment de plan revient à Spark basé sur JVM au lieu du chemin natif, Advisor affiche une alerte directement dans la sortie de la cellule du notebook, vous permettant d’identifier rapidement les opérateurs ou configurations non pris en charge sans quitter le notebook. Vous pouvez utiliser ces alertes pour diagnostiquer quand le déchargement natif n’est pas appliqué et décider s’il faut ajuster votre requête ou votre configuration.
Mécanisme de secours
Dans certains cas, le moteur d’exécution natif peut ne pas être en mesure d’exécuter une requête en raison de raisons telles que des fonctionnalités non prises en charge. Dans ces cas, l’opération revient au moteur Spark traditionnel. Ce mécanisme de secours automatique permet de garantir l’absence d’interruption dans votre workflow.


Surveiller les requêtes et les dataFrames exécutés par le moteur
Pour bien comprendre comment le moteur d’exécution natif est appliqué aux requêtes SQL et aux opérations DataFrame, et pour descendre dans la hiérarchie au niveau de la phase et de l’opérateur, vous pouvez vous référer à l’interface utilisateur Spark et au serveur d’historique Spark pour obtenir des informations plus détaillées sur l’exécution du moteur natif.
Onglet Moteur d’exécution natif
Vous pouvez accéder à la nouvelle onglet « Gluten SQL / DataFrame » pour afficher les informations de génération de Gluten et les détails de l’exécution des requêtes. Le tableau Requêtes fournit des informations sur le nombre de nœuds qui s’exécutent sur le moteur natif et ceux qui reviennent à la machine virtuelle Java pour chaque requête.

Graphique d’exécution de requête
Vous pouvez également sélectionner la description de la requête pour la visualisation du plan d’exécution de requête Apache Spark. Le graphique d’exécution fournit des détails d’exécution natifs entre les étapes et leurs opérations respectives. Les couleurs d’arrière-plan différencient les moteurs d’exécution : le vert représente le moteur d’exécution natif, tandis que le bleu clair indique que l’opération s’exécute sur le moteur JVM par défaut.

Limites
Bien que le moteur d’exécution natif (NEE) dans Microsoft Fabric améliore considérablement les performances des travaux Apache Spark, il présente actuellement les limitations suivantes :
Limitations existantes
Fonctionnalités Spark incompatibles : le moteur d’exécution natif ne prend actuellement pas en charge la diffusion en continu structurée. Si les fonctionnalités non prises en charge sont utilisées directement ou par le biais de bibliothèques importées, Spark revient à son moteur par défaut. Les UDF Python, les UDF Scala et les types de données complexes (tableaux, mappages, structures) sont désormais pris en charge. Pour plus d’informations, consultez les fonctions définies par l’utilisateur Python, les fonctions définies par l’utilisateur Scala et les types de données complexes dans le moteur d’exécution natif.
Formats de fichier non pris en charge : les requêtes sur
JSONetXMLles formats ne sont pas accélérées par le moteur d’exécution natif. Ces valeurs sont renvoyées par défaut au moteur JVM Spark standard pour l’exécution. Csv est désormais pris en charge par le biais de l’analyseur CSV vectorisé.Mode ANSI non pris en charge : le moteur d’exécution natif ne prend pas en charge le mode SQL ANSI. Si elle est activée, l’exécution revient au moteur Spark par défaut.
Incompatibilités de type dans les filtres de date : pour tirer parti de l’accélération du moteur d’exécution natif, assurez-vous que les deux côtés d’une comparaison de dates correspondent dans le type de données. Par exemple, au lieu de comparer une
DATETIMEcolonne à un littéral de chaîne, convertissez-la explicitement comme illustré ci-dessous.CAST(order_date AS DATE) = '2024-05-20'
Autres considérations et limitations
Incompatibilité lors de la conversion de décimal en virgule flottante : lorsqu’on effectue une conversion à partir de
DECIMALversFLOAT, Spark conserve la précision en convertissant les valeurs en chaîne de caractères avant de les analyser. NEE (via Velox) effectue une conversion directe à partir de la représentation interneint128_t, ce qui peut entraîner des discrépances d'arrondissement.Erreurs de configuration de fuseau horaire : la définition d’un fuseau horaire non reconnu dans Spark entraîne l’échec du travail sous NEE, tandis que Spark JVM le gère correctement. Par exemple:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEComportement d’arrondi incohérent : la
round()fonction se comporte différemment dans NEE à cause de sa dépendance àstd::round, ce qui ne permet pas de répliquer la logique d’arrondi de Spark. Cela peut entraîner des incohérences numériques dans les résultats d’arrondi.Absence de vérification des clés dupliquées dans la fonction
map(): lorsquespark.sql.mapKeyDedupPolicyest défini sur EXCEPTION, Spark génère une erreur pour les clés dupliquées. NEE ignore actuellement cette vérification et permet à la requête de réussir correctement.
Exemple:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Écart d'ordre dans
collect_list()avec tri : lors de l'utilisation deDISTRIBUTE BYetSORT BY, Spark conserve l'ordre des éléments danscollect_list(). NEE peut retourner des valeurs dans un ordre différent en raison de différences aléatoires, ce qui peut entraîner des attentes incompatibles pour la logique sensible à l’ordre.Incompatibilité de type intermédiaire pour
collect_list()/collect_set(): Spark utiliseBINARYcomme type intermédiaire pour ces agrégations, tandis que NEE utiliseARRAY. Cette incompatibilité peut entraîner des problèmes de compatibilité pendant la planification ou l’exécution des requêtes.Points de terminaison privés managés requis pour l’accès au stockage : lorsque le moteur d’exécution natif (NEE) est activé et si des travaux Spark tentent d’accéder à un compte de stockage à l’aide d’un point de terminaison privé managé, les utilisateurs doivent configurer des points de terminaison privés managés distincts pour les points de terminaison Blob (blob.core.windows.net) et DFS /File System (dfs.core.windows.net), même s’ils pointent vers le même compte de stockage. Un point de terminaison unique ne peut pas être réutilisé pour les deux. Il s’agit d’une limitation actuelle et peut nécessiter une configuration réseau supplémentaire lors de l’activation du moteur d’exécution natif dans un espace de travail disposant de points de terminaison privés managés pour les comptes de stockage.
Contenu connexe
- Delta Lake dans Microsoft Fabric vue d’ensemble
- UDF Python, UDF Scala et types de données complexes dans le moteur d’exécution natif
- Réduction efficace et gestionnaire de brassage à distance
- Environnements d'exécution Apache Spark dans Fabric
- Qu’est-ce que le réglage automatique pour les configurations Apache Spark dans Fabric ?