Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :✅ Entrepôt dans Microsoft Fabric
Les clés de substitution sont des identificateurs utilisés dans l’entreposage de données pour distinguer de manière unique les lignes, indépendamment de leurs clés naturelles. Dans Fabric Data Warehouse, IDENTITY les colonnes activent la génération automatique de ces clés de substitution lors de l’insertion de nouvelles lignes dans une table. Cet article explique comment utiliser IDENTITY des colonnes dans Fabric Data Warehouse pour créer et gérer efficacement des clés de substitution.
Pourquoi utiliser une colonne IDENTITY ?
IDENTITY les colonnes éliminent la nécessité d’une affectation manuelle de clés, ce qui réduit les risques d’erreurs et simplifie l’ingestion des données. Les valeurs uniques gérées par le système sont idéales en tant que clés de substitution et clés primaires. Par rapport aux approches manuelles pour produire des clés de substitution, IDENTITY les colonnes offrent des performances supérieures, car les clés uniques sont générées automatiquement sans logique supplémentaire sur les requêtes.
Le type de données bigint , requis pour IDENTITY les colonnes, peut stocker jusqu’à 9 223 372 036 854 775 807 valeurs entières positives, ce qui garantit que pendant toute la durée de vie d’une table, chaque ligne reçoit une valeur unique dans sa IDENTITY colonne.
Pour obtenir un plan de migration des données avec des clés de substitution à partir d’autres plateformes de base de données, consultez Migrer des colonnes IDENTITY vers Fabric Data Warehouse.
Syntaxe
Pour définir une IDENTITY colonne dans Fabric Data Warehouse, la IDENTITY propriété est utilisée avec la colonne souhaitée. La syntaxe est la suivante :
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
[column_name] BIGINT IDENTITY,
[ ,... n ]
-- Other columns here
);
Fonctionnement des colonnes IDENTITY
Dans Fabric Data Warehouse, vous ne pouvez pas spécifier de valeur de départ ou d’incrémentation personnalisée ; le système gère les valeurs en interne pour garantir l’unicité.
IDENTITY les colonnes produisent toujours des valeurs entières positives. Chaque nouvelle ligne reçoit une nouvelle valeur et l’unicité est garantie tant que la table existe. Une fois qu’une valeur est utilisée, IDENTITY n’utilise pas cette même valeur à nouveau, préservant à la fois l’intégrité des clés et l’unicité. Les lacunes peuvent apparaître sur les valeurs produites par la IDENTITY colonne.
Allocation de valeurs
En raison de l’architecture distribuée du moteur d’entrepôt, la IDENTITY propriété ne garantit pas l’ordre dans lequel les valeurs de substitution sont allouées. La IDENTITY propriété est conçue pour effectuer un scale-out entre les nœuds de calcul afin d’optimiser le parallélisme, sans affecter les performances de charge. Par conséquent, les plages de valeurs sur différentes tâches d’ingestion peuvent avoir des plages de séquences différentes.
Pour illustrer ce comportement, considérez l’exemple suivant :
-- Create a table with an IDENTITY column
CREATE TABLE dbo.T1(
C1 BIGINT IDENTITY,
C2 VARCHAR(30) NULL
)
-- Ingestion task A
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Ingestion task B
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Reviewing the data
SELECT * FROM dbo.T1;
Exemple de résultat :
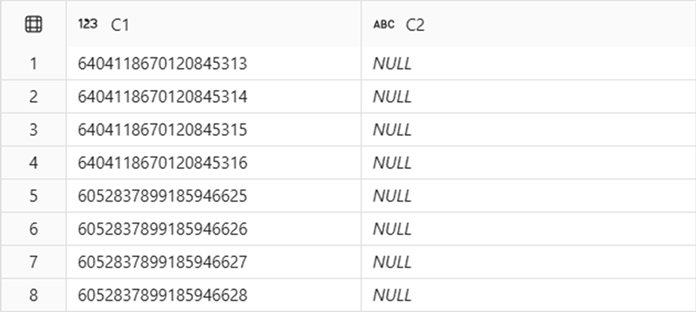
Dans cet exemple, Ingestion task A et Ingestion task B sont exécutés séquentiellement, en tant que tâches indépendantes. Bien que les tâches s’exécutaient consécutivement, les quatre premières et les quatre dernières lignes ont des plages de clés d’identité différentes en dbo.T1.C1. En plus de cela, comme indiqué dans cet exemple, les écarts entre les plages affectées pour la tâche A et la tâche B peuvent se produire.
IDENTITY dans Fabric Data Warehouse garantit que toutes les valeurs d’une colonne sont uniques, mais il peut y avoir des lacunes sur les plages produites pour une tâche d’ingestion IDENTITY donnée.
Vues du système
L’affichage catalogue sys.identity_columns peut être utilisé pour répertorier toutes les colonnes d’identité d’un entrepôt. L’exemple suivant répertorie toutes les tables qui contiennent une IDENTITY colonne sur leur définition, avec leur nom de schéma respectif et le nom de la IDENTITY colonne de cette table :
SELECT
s.name AS SchemaName,
t.name AS TableName,
c.name AS IdentityColumnName
FROM
sys.identity_columns AS ic
INNER JOIN
sys.columns AS c ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
INNER JOIN
sys.tables AS t ON ic.[object_id] = t.[object_id]
INNER JOIN
sys.schemas AS s ON t.[schema_id] = s.[schema_id]
ORDER BY
s.name, t.name;
Limites
- Seul le type de données Bigint est pris en charge pour
IDENTITYles colonnes dans Fabric Data Warehouse. Toute tentative d’utilisation d’autres types de données entraîne une erreur. -
IDENTITY_INSERTn’est pas pris en charge dans Fabric Data Warehouse. Les utilisateurs ne peuvent pas mettre à jour ou insérer manuellement des valeurs de colonne sur des colonnes d’identité dans Fabric Data Warehouse. - Définir un
seedet unincrementn'est pas pris en charge. Par conséquent, la réécriture de laIDENTITYcolonne n’est pas prise en charge. - L’ajout d’une nouvelle
IDENTITYcolonne à une table existante n’estALTER TABLEpas pris en charge. Envisagez d’utiliser CREATE TABLE AS SELECT (CTAS) ou SELECT... INTO comme alternative à la création d’une copie d’une table existante qui ajoute uneIDENTITYcolonne à sa définition. - Certaines limitations s’appliquent à la façon dont
IDENTITYles colonnes sont conservées lors de la création d’une table à la suite d’une sélection à partir d’une autre table avecCREATE TABLE AS SELECT (CTAS)ouSELECT... INTO. Pour plus d’informations, consultez la section Types de données de SELECT - INTO Clause (Transact-SQL).
Examples
R. Créer une table avec une colonne IDENTITY
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Cette instruction crée une table Employees où chaque nouvelle ligne reçoit automatiquement une valeur unique EmployeeID en tant que valeur bigint .
B. INSERT sur une table avec une colonne d’identité
Lorsque la première colonne est une IDENTITY colonne, vous n’avez pas besoin de la spécifier dans la liste des colonnes.
INSERT INTO Employees (FirstName, LastName) VALUES ('Ensi','Vasala')
Il est également possible d’émettre les noms de colonnes si les valeurs sont fournies pour toutes les colonnes de la table de destination (à l’exception de la colonne d’identité) :
INSERT INTO Employees VALUES ('Quarantino', 'Esposito')
Chapitre C. Créer une table avec une colonne IDENTITY à l’aide de CREATE TABLE AS SELECT (CTAS)
Prenons l’exemple d’une table simple :
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Nous pouvons utiliser CREATE TABLE AS SELECT (CTAS) pour créer une copie de cette table, en persistant la IDENTITY propriété dans la table cible :
CREATE TABLE RetiredEmployees
AS SELECT * FROM Employees
La colonne de la table cible hérite de la IDENTITY propriété de la table source. Pour une liste des limitations applicables à ce scénario, consultez la section Types de données de la clause SELECT - INTO.
D. Créer une nouvelle table avec une colonne IDENTITY à l’aide de SELECT... INTO
Prenons l’exemple d’une table simple :
CREATE TABLE dbo.Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Retired BIT
);
Nous pouvons utiliser SELECT... INTO pour créer une copie de cette table, en persistant la IDENTITY propriété dans la table cible :
SELECT *
INTO dbo.RetiredEmployees
FROM dbo.Employees
WHERE Retired = 1;
La colonne de la table cible hérite de la IDENTITY propriété de la table source. Pour une liste des limitations applicables à ce scénario, consultez la section Types de données de la clause SELECT - INTO.