Effectuer des analyses avec Machine Learning Studio (classique) à l’aide d’une base de données SQL Server
S’APPLIQUE À : Machine Learning Studio (classique)
Machine Learning Studio (classique)  Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Souvent, les entreprises qui travaillent avec des données locales souhaitent tirer parti de l’échelle et de l’agilité du cloud pour leurs charges de travail d’apprentissage automatique. Mais elles ne souhaitent pas perturber leurs processus métier et leurs flux de travail actuels en déplaçant leurs données locales vers le cloud. Machine Learning Studio (classique) prend désormais en charge la lecture des données dans une base de données SQL Server, puis l’entraînement et le scoring d’un modèle avec ces données. Vous n’avez plus à copier et à synchroniser manuellement les données entre le cloud et votre serveur local. Au lieu de cela, le module Importer des données de Machine Learning Studio (classique) peut désormais lire directement dans votre base de données SQL Server pour vos travaux d’entraînement et de scoring.
Cet article fournit une vue d’ensemble de l’entrée de données SQL Server dans Machine Learning Studio (classique). Il part du principe que vous êtes familiarisé avec les concepts de Studio (classique), comme les espaces de travail, les modules, les jeux de données, les expériences, etc.
Notes
Cette fonctionnalité n’est pas disponible pour les espaces de travail gratuits. Pour plus d’informations sur les prix et les niveaux de Machine Learning, consultez les Tarification Machine Learning Studio (classique).
Installer le runtime d’intégration auto-hébergé Data Factory
Pour accéder à une base de données SQL Server dans Machine Learning Studio (classique), vous devez télécharger et installer le runtime d’intégration auto-hébergé Data Factory, anciennement connu sous le nom de passerelle de gestion des données. Lorsque vous configurez la connexion dans Machine Learning Studio (classique), vous avez la possibilité de télécharger et d’installer le runtime d’intégration à l’aide de la boîte de dialogue Télécharger et inscrire la passerelle de données décrite ci-dessous.
Vous pouvez également installer le runtime d’intégration au préalable en téléchargeant et exécutant le package d’installation MSI à partir du Centre de téléchargement Microsoft. Le package MSI peut aussi servir à mettre à niveau un runtime d’intégration existant avec la dernière version, en conservant tous les paramètres.
Le runtime d'intégration auto-hébergé Data Factory a les prérequis suivants :
- Le runtime d’intégration auto-hébergé Data Factory nécessite un système d’exploitation 64 bits avec .NET Framework 4.6.1 ou ultérieur.
- Les versions de système d’exploitation Windows prises en charge sont Windows 10, Windows Server 2012, Windows Server 2012 R2, Windows Server 2016.
- La configuration recommandée pour la machine de runtime d'intégration est la suivante : au moins 2 GHz, processeur 4 cœurs, 8 Go de RAM et 80 Go d’espace disque.
- Si la machine hôte est en veille prolongée, le runtime d’intégration ne répond pas aux demandes de données. Vous devez donc configurer un plan de gestion de l’alimentation approprié sur l’ordinateur avant d’installer le runtime d’intégration. Si la machine est configurée pour se mettre en veille prolongée, l’installation du runtime d’intégration affiche un message.
- Étant donné que l’activité de copie se déroule selon une fréquence spécifique, l’utilisation des ressources (processeur, mémoire) sur l’ordinateur suit également le même modèle avec des périodes de pointe et d’inactivité. L'utilisation des ressources dépend également en grande partie de la quantité de données déplacées. Quand plusieurs travaux de copie sont en cours, vous constaterez une augmentation des ressources utilisées pendant les heures de pointe. Si la configuration minimale listée ci-dessus est techniquement suffisante, vous pouvez choisir d’avoir une configuration avec plus de ressources que la configuration minimale en fonction de votre charge spécifique pour le déplacement des données.
Prenez en compte ce qui suit quand vous configurez et utilisez un runtime d'intégration auto-hébergé Data Factory :
Vous pouvez installer une seule instance de runtime d’intégration sur un même ordinateur.
Vous pouvez utiliser un seul runtime d’intégration pour plusieurs sources de données locales.
Vous pouvez connecter plusieurs runtimes d’intégration sur différents ordinateurs à la même source de données locale.
Vous configurez un runtime d’intégration pour un seul espace de travail à la fois. Pour le moment, les runtimes d’intégration ne peuvent pas être partagés entre espaces de travail.
Vous pouvez configurer plusieurs runtimes d’intégration pour un seul espace de travail. Par exemple, vous pouvez choisir d’utiliser un runtime d’intégration connecté à vos sources de données de test pendant le développement et un runtime d’intégration de production quand vous êtes prêt à le rendre opérationnel.
Le runtime d’intégration n’a pas besoin d’être sur la même machine que la source de données. Toutefois, le fait d’avoir une passerelle plus proche de la source de données réduit le temps de connexion de la passerelle à la source de données. Nous vous recommandons d’installer le runtime d’intégration sur une autre machine que celle qui héberge la source de données locale, pour que la passerelle et la source de données ne soient pas en concurrence pour l’attribution de ressources.
Si un runtime d’intégration est déjà installé sur l’ordinateur qui traite des scénarios Power BI ou Azure Data Factory, installez un autre runtime d’intégration pour Machine Learning Studio (classique) sur un autre ordinateur.
Notes
Vous ne pouvez pas exécuter le runtime d’intégration auto-hébergé Data Factory et Power BI Gateway sur le même ordinateur.
Vous devez utiliser le runtime d’intégration auto-hébergé Data Factory pour Machine Learning Studio (classique), même si vous utilisez Azure ExpressRoute pour d’autres données. Traitez votre source de données comme une source de données locale (derrière un pare-feu), même quand vous utilisez ExpressRoute. Utilisez le runtime d’intégration auto-hébergé Data Factory pour établir la connectivité entre Machine Learning et la source de données.
Des informations détaillées sur les prérequis pour l’installation, des étapes d’installation et des conseils de dépannage sont disponibles dans l’article Runtime d’intégration dans Data Factory.
Entrer des données de votre base de données SQL Server dans Machine Learning
Au cours de cette procédure pas à pas, vous allez installer un runtime d'intégration Azure Data Factory dans un espace de travail Azure Machine Learning, le configurer, puis lire des données dans une base de données SQL Server.
Conseil
Avant de commencer, désactivez le bloqueur de fenêtres publicitaires de votre navigateur pour studio.azureml.net. Si vous utilisez le navigateur Google Chrome, téléchargez et installez l’un des modules disponibles sur le WebStore de Google Chrome Extension de l’application Click Once.
Notes
Le runtime d’intégration auto-hébergé Azure Data Factory est l’ancienne passerelle de gestion des données. Ce tutoriel étape par étape continue d’y faire référence sous le nom de passerelle.
Étape 1 : Créer une passerelle
La première étape consiste à créer et à configurer la passerelle pour accéder à votre base de données SQL.
Connectez-vous à Machine Learning Studio (classique) et sélectionnez l’espace de travail dans lequel vous souhaitez travailler.
Cliquez sur le panneau PARAMÈTRES sur la gauche, puis cliquez sur l’onglet PASSERELLES DE DONNÉES en haut.
Cliquez sur NOUVELLE PASSERELLE DE DONNÉES en bas de l’écran.
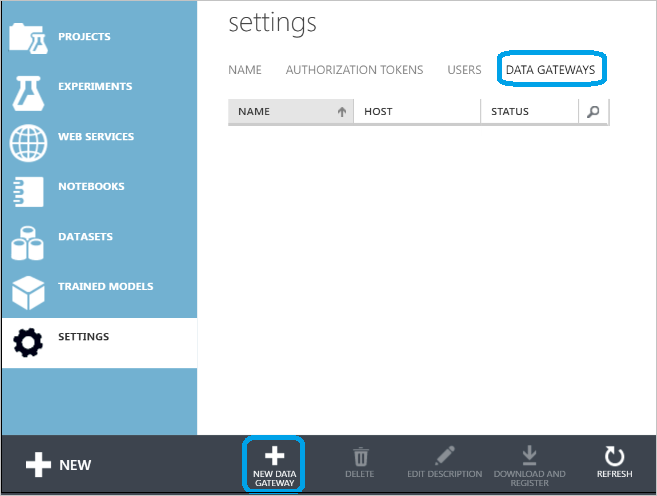
Dans la boîte de dialogue Nouvelle passerelle de données, entrez le Nom de la passerelle et ajoutez éventuellement une Description. Cliquez sur la flèche située dans l’angle inférieur droit pour accéder à l’étape suivante de la configuration.
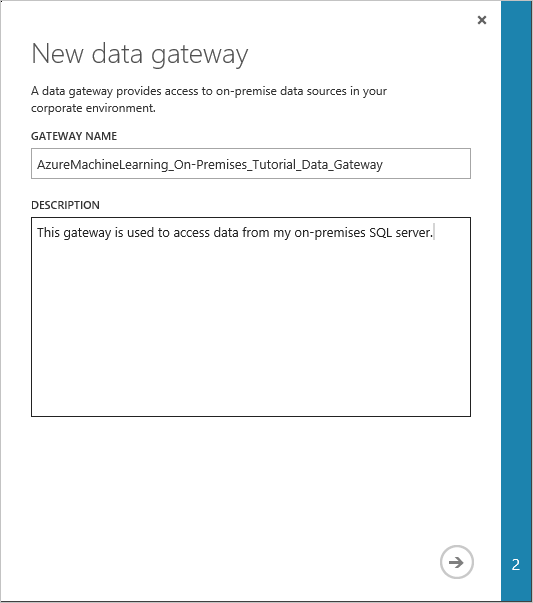
Dans la boîte de dialogue Télécharger et inscrire une passerelle de données, copiez la CLÉ D’INSCRIPTION DE LA PASSERELLE dans le presse-papiers.
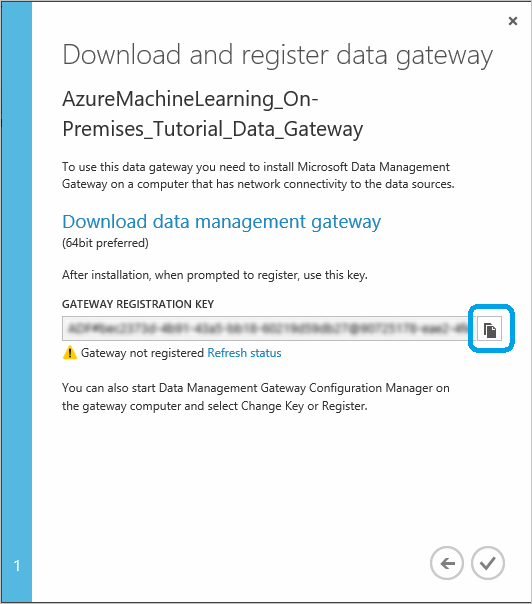
Si vous n’avez pas encore téléchargé et installé la passerelle de gestion des données de Microsoft, cliquez sur Télécharger la passerelle de gestion des données. Vous accéderez au Centre de téléchargement Microsoft, où vous pourrez sélectionner la version de la passerelle dont vous avez besoin, la télécharger et l’installer. Vous trouverez des informations détaillées sur les conditions préalables à l’installation, des étapes d’installation et des conseils de dépannage dans les sections du début de l’article Déplacer des données entre des sources locales et le cloud à l’aide de la passerelle de gestion des données.
Une fois la passerelle installée, le Gestionnaire de configuration de la passerelle de gestion des données s’ouvre et la boîte de dialogue Inscrire la passerelle s’affiche. Collez la Clé d’inscription de la passerelle que vous avez copiée dans le presse-papiers et cliquez sur Inscrire.
Si vous avez déjà installé une passerelle, exécutez le Gestionnaire de configuration de la passerelle de gestion des données. Cliquez sur Modifier la clé, collez la Clé d’inscription de la passerelle que vous avez copiée dans le Presse-papiers à l’étape précédente, puis cliquez sur OK.
Une fois l’installation terminée, la boîte de dialogue Inscrire la passerelle du Gestionnaire de configuration de la passerelle de gestion des données de Microsoft s’affiche. Collez la CLÉ D’INSCRIPTION DE LA PASSERELLE que vous avez copiée dans le Presse-papiers lors d’une étape précédente et cliquez sur Inscrire.
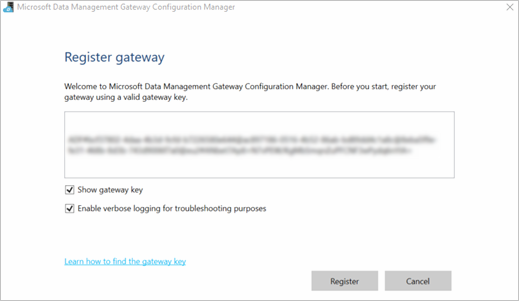
La configuration de la passerelle est terminée lorsque les valeurs suivantes sont définies sur l’onglet Accueil dans le Gestionnaire de configuration de la passerelle de gestion des données de Microsoft :
Le nom de la passerelle et le nom de l’instance sont définis sur le nom de la passerelle.
Inscription est défini sur Inscrit.
État est défini sur Démarré.
La barre d’état située au bas de l’écran affiche le message Connecté au service cloud de la passerelle de gestion des données accompagné d’une coche verte.
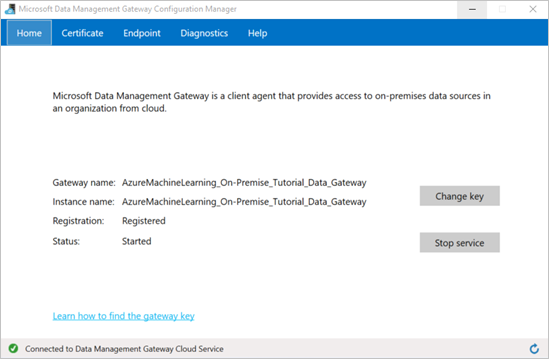
Machine Learning Studio (classique) se met également à jour quand l’inscription réussit.
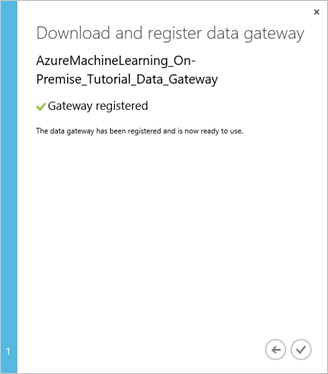
Dans la boîte de dialogue Télécharger et inscrire la passerelle de données , cliquez sur la coche pour terminer l’installation. La page Paramètres affiche l’état « En ligne » pour la passerelle. Dans le volet de droite, vous trouverez l’état et d’autres informations utiles.
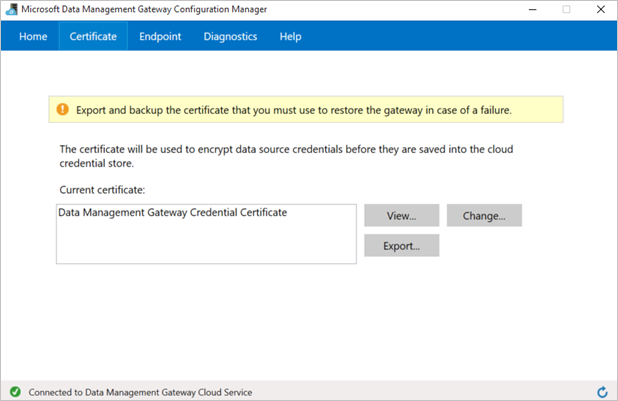
Dans le Gestionnaire de configuration de la passerelle de gestion des données de Microsoft, basculez vers l’onglet Certificat . Le certificat spécifié dans cet onglet sert à chiffrer/déchiffrer les informations d’identification pour le magasin de données local que vous spécifiez dans le portail. Il s’agit du certificat par défaut. Microsoft recommande de le modifier pour spécifier votre propre certificat, que vous sauvegardez dans votre système de gestion des certificats. Cliquez sur Modifier pour utiliser votre propre certificat à la place.
(Facultatif) Si vous souhaitez activer la journalisation détaillée pour résoudre les problèmes de passerelle, dans le Gestionnaire de configuration de la passerelle de gestion des données de Microsoft, basculez sur l’onglet Diagnostics et cochez l’option Activer la journalisation détaillée pour résoudre des problèmes. Vous trouverez les informations de journalisation dans l’Observateur d’événements Windows sous le nœud >Journaux des applications et des servicesPasserelle de gestion des données. Vous pouvez également utiliser l’onglet Diagnostics pour tester la connexion à une source de données locale à l’aide de la passerelle.
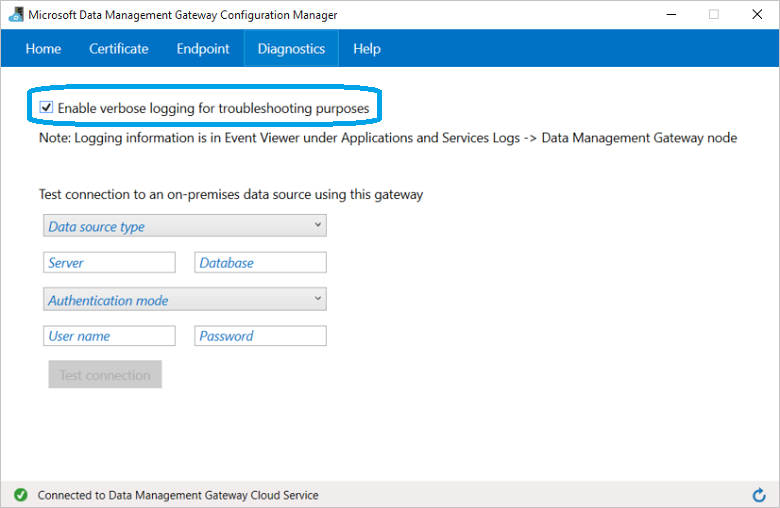
Le processus de configuration de la passerelle dans Machine Learning Studio (classique) est terminé. Vous êtes maintenant prêt à utiliser vos données locales.
Vous pouvez créer et configurer plusieurs passerelles dans Studio (classique) pour chaque espace de travail. Par exemple, vous pouvez avoir une passerelle que vous souhaitez connecter à vos sources de données de test pendant le développement et une passerelle distincte pour vos sources de données en production. Machine Learning Studio (classique) vous donne la possibilité de configurer plusieurs passerelles en fonction de votre environnement d’entreprise. Actuellement, vous ne pouvez pas partager une passerelle entre différents espaces de travail et une seule passerelle peut être installée sur un même ordinateur. Pour plus d’informations, consultez Déplacement de données entre des sources locales et le cloud à l’aide de la passerelle de gestion des données.
Étape 2 : Utiliser la passerelle pour lire des données à partir d’une source de données locale
Après avoir configuré la passerelle, vous pouvez ajouter un module Importer des données à une expérience qui entre les données à partir de la base de données SQL Server.
Dans Machine Learning Studio (classique), sélectionnez l’onglet EXPÉRIENCES, cliquez sur +NOUVELLE dans le coin inférieur gauche, puis sélectionnez Expérience vide (ou sélectionnez l’un des exemples d’expériences disponibles).
Recherchez et faites glisser le module Importer des données jusqu’à la zone de dessin de l’expérience.
Cliquez sur Enregistrer sous sous le canevas. Entrez « Tutoriel SQL Server local Machine Learning Studio (classique) » comme nom d’expérience, sélectionnez l’espace de travail, puis cochez la case OK.
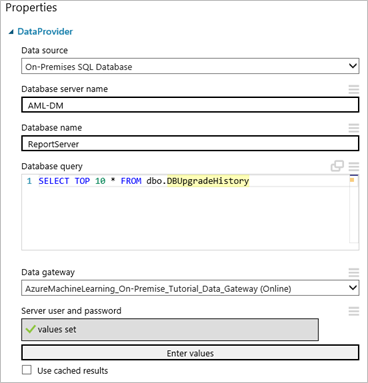
Cliquez sur le module Importer des données pour le sélectionner puis, dans le volet Propriétés à droite de la zone de dessin, sélectionnez « Base de données SQL locale » dans la liste déroulante Source de données.
Sélectionnez la Passerelle de données que vous avez installée et inscrite. Vous pouvez configurer une autre passerelle en sélectionnant « (ajouter une nouvelle passerelle de données...) ».
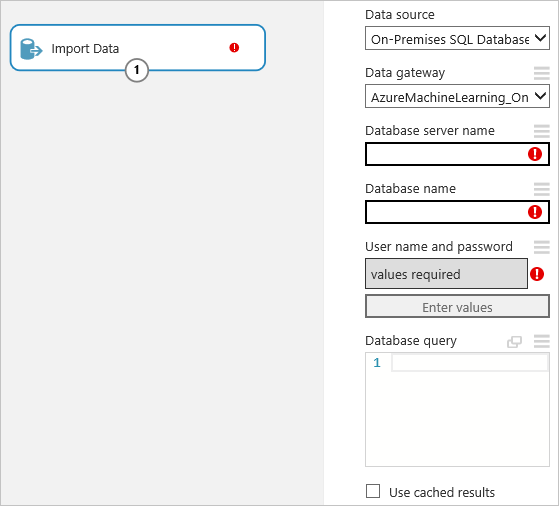
Entrez le Nom du serveur de base de données et le Nom de la base de données SQL, ainsi que la Requête de base de données SQL que vous souhaitez exécuter.
Cliquez sur Entrer des valeurs sous Nom d’utilisateur et mot de passe et entrez vos informations d’identification de base de données. Vous pouvez utiliser l'Authentification Windows intégrée ou l'Authentification SQL Server en fonction de la configuration de votre instance de SQL Server.
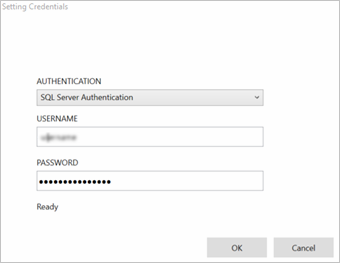
Le message « valeurs requises » devient « valeurs définies » avec une coche verte. Il vous suffit d’entrer les informations d’identification une seule fois, sauf si les informations de base de données ou de mot de passe changent. Machine Learning Studio (classique) utilise le certificat que vous avez fourni lors de l’installation de la passerelle pour chiffrer les informations d’identification dans le cloud. Azure ne stocke jamais d’informations d’identification locales sans chiffrement.
Cliquez sur EXÉCUTER pour lancer l’expérience.
Une fois l’expérimentation terminée, vous pouvez visualiser les données que vous avez importées à partir de la base de données en cliquant sur le port de sortie du module Importer des données et en sélectionnant Visualiser.
Une fois que vous avez terminé le développement de votre expérience, vous pouvez déployer et opérationnaliser votre modèle. Grâce au service d’exécution de lots, les données de la base de données SQL Server configurées dans le module Importer des données seront lues et utilisées pour le scoring. Vous pouvez utiliser le service de réponse aux demandes pour l’évaluation des données locales, mais Microsoft recommande d’utiliser plutôt le complément Excel . L'écriture dans une base de données SQL Server avec Exporter des données n'est actuellement pas prise en charge dans vos expériences ou dans les services web publiés.