Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server 2017 (14.x) et versions ultérieures
SQL Server 2017 (14.x) et versions ultérieures
Cet article décrit l’extension Python permettant d’exécuter des scripts Python externes avec SQL Server Machine Learning Services. Elle ajoute les éléments suivants :
- Un environnement d’exécution Python
- La distribution Anaconda comportant le runtime et l’interpréteur Python 3.5
- Des outils et bibliothèques standard
- Paquets Python de Microsoft
- revoscalepy pour l’analytique à grande échelle
- microsoftml pour les algorithmes de Machine Learning
L’installation du runtime et de l’interpréteur Python 3.5 assure une compatibilité quasi-complète avec les solutions Python standard. Python s’exécute dans un processus distinct de SQL Server pour éviter de compromettre les opérations de base de données.
Composants Python
SQL Server comporte des packages open source et propriétaires. Le runtime Python installé par le programme d’installation est Anaconda 4.2 avec Python 3.5. Le runtime Python est installé indépendamment des outils SQL et est exécuté en dehors des processus du moteur de base, dans le framework d’extensibilité. Pendant l’installation de Machine Learning Services avec Python, vous devez accepter les termes du contrat de la licence publique GNU.
SQL Server ne modifie pas les exécutables Python, mais vous devez utiliser la version de Python qui est installée par le programme d’installation, car c’est à partir de cette version que les packages propriétaires sont créés et testés. Pour obtenir la liste des packages pris en charge par la distribution Anaconda, consultez le site Continuum Analytics : Liste des packages Anaconda.
La distribution Anaconda associée à une instance de moteur de base de données spécifique se trouve dans le dossier associé à l’instance. Par exemple, si vous avez installé le moteur de base de données SQL Server 2017 avec Machine Learning Services et Python sur l’instance par défaut, regardez sous C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Les packages Python ajoutés par Microsoft pour les charges de travail parallèles et distribuées incluent les bibliothèques suivantes.
| Bibliothèque | Description |
|---|---|
| revoscalepy | Prend en charge les objets de source de données ainsi que l’exploration, la manipulation, la transformation et la visualisation des données. Prend en charge la création de contextes de calcul distants ainsi qu’un certain nombre de modèles de Machine Learning scalables, comme rxLinMod. Pour plus d’informations, consultez Module revoscalepy avec SQL Server. |
| microsoftml | Contient des algorithmes de Machine Learning qui ont été optimisés pour la vitesse et la précision ainsi que des transformations en ligne pour permettre l’utilisation de texte et d’images. Pour plus d’informations, consultez Module microsoftml avec SQL Server. |
Les modules microsoftml et revoscalepy sont étroitement couplés ; les sources de données utilisées dans microsoftml sont définies en tant qu’objets revoscalepy. Les limitations du contexte de calcul dans revoscalepy sont transférées à microsoftml. À savoir, toutes les fonctionnalités sont disponibles pour les opérations locales, mais le basculement vers un contexte de calcul distant nécessite RxInSqlServer.
Utilisation de Python dans SQL Server
Vous importez le module revoscalepy dans votre code Python, puis vous appelez des fonctions à partir du module, comme n’importe quelle autre fonction Python.
Parmi les sources de données prises en charge figurent les bases de données ODBC, SQL Server et le format de fichier XDF pour l’échange de données avec d’autres sources ou avec des solutions R. Les données d’entrée pour Python doivent être tabulaires. Tous les résultats Python doivent être retournés sous la forme d’une trame de données pandas.
Parmi les contextes de calcul pris en charge figurent le contexte de calcul SQL Server local ou distant. Un contexte de calcul distant fait référence à une exécution de code qui commence sur un ordinateur, par exemple une station de travail, avant que l’exécution du script bascule sur un ordinateur distant. Pour que le basculement du contexte de calcul s’opère, les deux systèmes doivent avoir la même bibliothèque revoscalepy.
Comme vous pouvez le comprendre, le contexte de calcul local exécute notamment le code Python sur le même serveur que l’instance du moteur de base de données, avec le code à l’intérieur de T-SQL ou incorporé dans une procédure stockée. Vous pouvez aussi exécuter le code à partir d’un IDE Python local et faire en sorte que le script s’exécute sur l’ordinateur SQL Server, en définissant un contexte de calcul distant.
Architecture d’exécution
Les schémas ci-dessous décrivent l’interaction des composants SQL Server avec le runtime Python dans chacun des scénarios pris en charge suivants : exécution de script dans la base de données et exécution à distance à partir d’un terminal Python, en utilisant un contexte de calcul SQL Server.
Scripts Python exécutés dans la base de données
Quand vous exécutez Python « à l’intérieur » de SQL Server, vous devez encapsuler le script Python à l’intérieur d’une procédure stockée spéciale, sp_execute_external_script.
Une fois que le script a été incorporé dans la procédure stockée, toute application capable d’effectuer un appel de procédure stockée peut lancer l’exécution du code Python. SQL Server gère ensuite l’exécution du code comme le résume le schéma suivant.
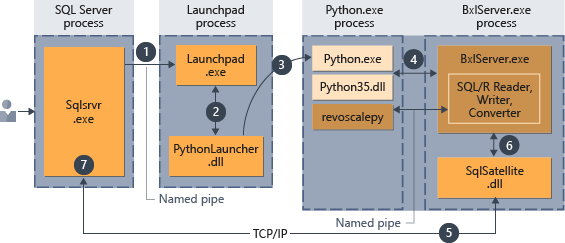
- Le paramètre
@language='Python'transmis à la procédure stockée indique une demande pour l'environnement d'exécution Python. SQL Server envoie cette demande au service launchpad. Dans Linux, SQL utilise un service launchpad pour communiquer avec un processus launchpad distinct pour chaque utilisateur. Pour plus d’informations, consultez le schéma de l’architecture d’extensibilité. - Le service launchpad démarre le lanceur approprié (en l’occurrence, PythonLauncher).
- PythonLauncher démarre le processus Python35 externe.
- En coordination avec le runtime Python, BxlServer gère les échanges de données et le stockage des résultats du travail.
- SQL Satellite gère les communications avec SQL Server sur les tâches et les processus associés.
- BxlServer utilise SQL Satellite pour communiquer l’état et les résultats à SQL Server.
- SQL Server obtient les résultats et ferme les tâches et les processus associés.
Scripts Python exécutés à partir d’un client distant
Vous pouvez exécuter les scripts Python à partir d'un ordinateur distant, par exemple un ordinateur portable, et les faire exécuter dans le contexte de l'ordinateur SQL Server, si les conditions suivantes sont réunies :
- Vous concevez les scripts de manière appropriée
- Les bibliothèques d’extensibilité utilisées par Machine Learning Services sont installées sur l’ordinateur distant. Le package revoscalepy est nécessaire à l’utilisation de contextes de calcul distants.
Le schéma suivant résume le workflow global correspondant à l’envoi de scripts à partir d’un ordinateur distant.
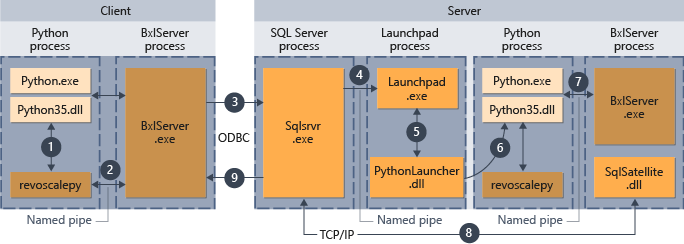
- Pour les fonctions prises en charge dans revoscalepy, le runtime Python appelle une fonction de liaison, qui à son tour appelle BxlServer.
- BxlServer est fourni avec Machine Learning Services (dans la base de données) et s’exécute dans un processus distinct du runtime Python.
- BxlServer détermine la cible de connexion et initie une connexion à l’aide d’ODBC, en transmettant les informations d’identification fournies dans la chaîne de connexion du script Python.
- BxlServer ouvre une connexion à l’instance SQL Server.
- Quand le runtime d’un script externe est appelé, le service launchpad est invoqué, lequel démarre à son tour le lanceur approprié (en l’occurrence, PythonLauncher.dll). Après quoi, le traitement du code Python est géré dans un workflow similaire à celui au cours duquel le code Python est invoqué à partir d’une procédure stockée dans T-SQL.
- PythonLauncher effectue un appel à l’instance du runtime Python qui est installé sur l’ordinateur SQL Server.
- Les résultats sont retournés à BxlServer.
- SQL Satellite gère la communication avec SQL Server et le nettoyage des objets de travail associés.
- SQL Server transmet en retour les résultats au client.