Générer et effectuer l’apprentissage d’un modèle d’extraction personnalisé
Ce contenu s’applique à :![]() v4.0 (préversion) | Versions précédentes :
v4.0 (préversion) | Versions précédentes : ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1
v2.1
Important
Le comportement de formation du modèle génératif personnalisé est différent de celui de la formation du modèle personnalisé et du modèle neural. Le document suivant couvre uniquement la formation du modèle personnalisé et du modèle neural. Pour obtenir des conseils sur le modèle génératif personnalisé, reportez-vous au modèle génératif personnalisé
Les modèles personnalisés Intelligence documentaire nécessitent un certain nombre de documents de formation pour commencer. Si vous disposez d’au moins cinq documents, vous pouvez commencer l’apprentissage d’un modèle personnalisé. Vous pouvez entraîner un modèle de modèle personnalisé (formulaire personnalisé) ou un modèle neural personnalisé (document personnalisé) ou modèle de modèle personnalisé (formulaire personnalisé). Ce document vous guide tout au long du processus de formation des modèles personnalisés.
Exigences d’entrée de modèle personnalisé
Commencez par vous assurer que votre jeu de données d’apprentissage respecte les exigences d’entrée de l’Intelligence documentaire.
Formats de fichiers pris en charge :
Modèle PDF Image : JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Pour les PDF et TIFF, jusqu'à 2 000 pages peuvent être traitées (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse de documents est de 500 Mo pour le niveau payant (S0) et de
4Mo pour le niveau gratuit (F0).Les dimensions de l’image doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond environ à un texte de
8points à 150 points par pouce (ppp).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’apprentissage du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle de gabarit et de
1Go pour le modèle neuronal.Pour l’apprentissage du modèle de classification personnalisé, la taille totale des données d’entraînement est de
1Go, avec un maximum de 10 000 pages. Pour 2024-07-31-preview et les versions ultérieures, la taille totale des données de formation est de2Go, avec un maximum de 10 000 pages.
Conseils relatifs aux données d’entraînement
Pour optimiser davantage votre jeu de données à des fins d’apprentissage, suivez ces conseils :
- Utilisez des documents PDF utilisant du texte au lieu d’images. Les PDF numérisés sont traités comme des images.
- Utilisez des exemples dont tous les champs sont remplis pour les formulaires avec des champs d’entrée.
- Utilisez des formulaires avec des valeurs différentes dans chaque champ.
- Utilisez un plus grand jeu de données (10 à 15 images) si vos images de formulaire sont de faible qualité.
Charger vos données d’entraînement
Une fois que vous réunissez un ensemble des formulaires ou documents pour l’apprentissage, vous devez le charger sur un conteneur de stockage blob Azure. Si vous ignorez comment créer un compte de stockage Azure avec un conteneur, consultez le démarrage rapide du stockage Azure pour le portail Azure. Vous pouvez utiliser le niveau tarifaire Gratuit (F0) pour tester le service, puis passer par la suite à un niveau payant pour la production.
Vidéo : Effectuer l’apprentissage de votre modèle personnalisé
- Une fois que vous collectez et chargez votre jeu de données d’apprentissage, vous êtes prêt à effectuer l’apprentissage de votre modèle personnalisé. Dans la vidéo suivante, nous créons un projet et explorer certains des principes de base pour réussir l’étiquetage et la formation d’un modèle.
Créer un projet dans Document Intelligence Studio
Document Intelligence Studio fournit et orchestre l’ensemble des appels d’API requis pour créer votre jeu de données et effectuer l’apprentissage de votre modèle.
Pour commencer, accédez à Document Intelligence Studio. La première fois que vous utilisez Studio, vous devez initialiser votre abonnement, votre groupe de ressources et votre ressource. Suivez ensuite les prérequis pour les projets personnalisés afin de configurer Studio pour accéder à votre jeu de données d’apprentissage.
Dans Studio, sélectionnez la vignette Modèle d’extraction personnalisé, puis sélectionnez le bouton Créer un projet.
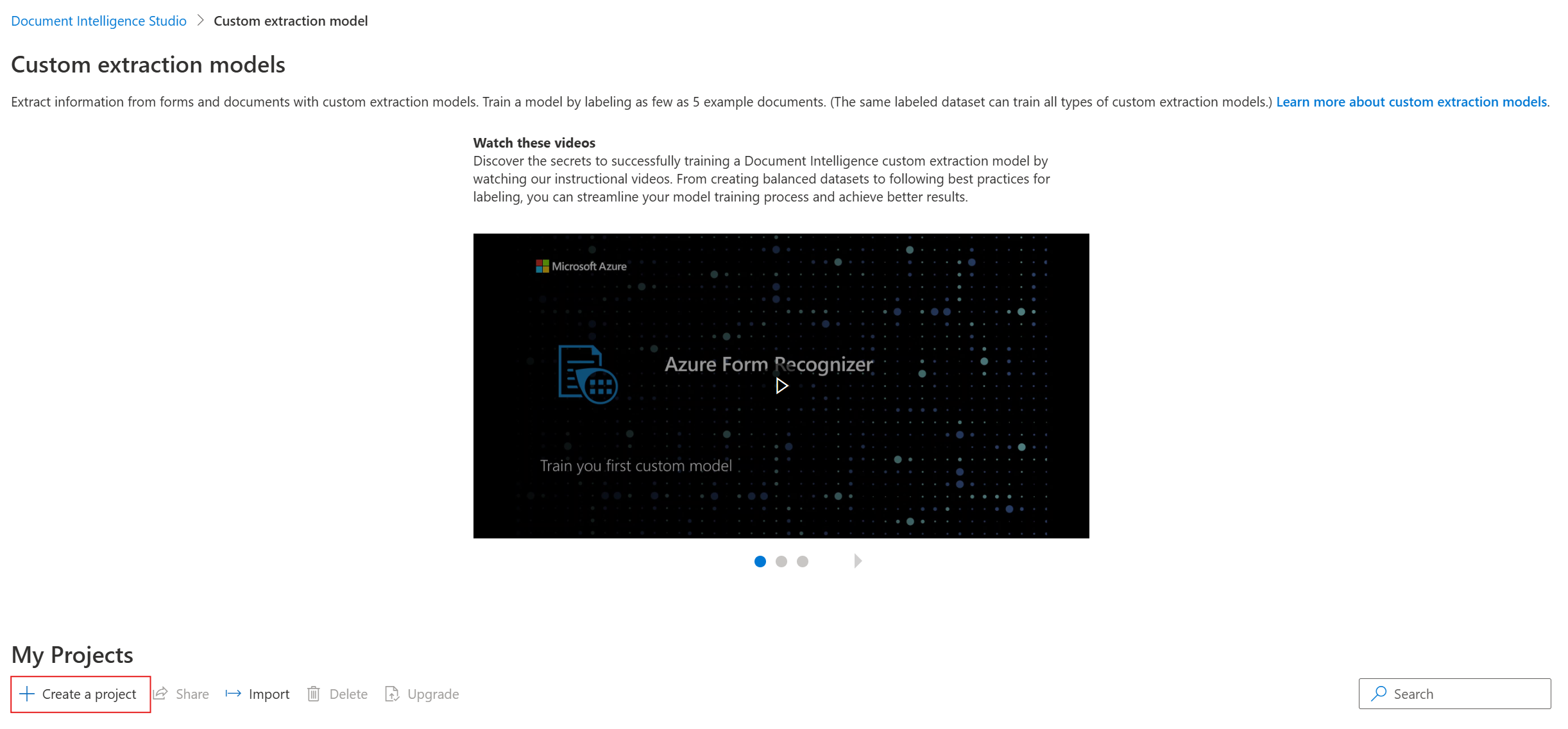
Dans la boîte de dialogue
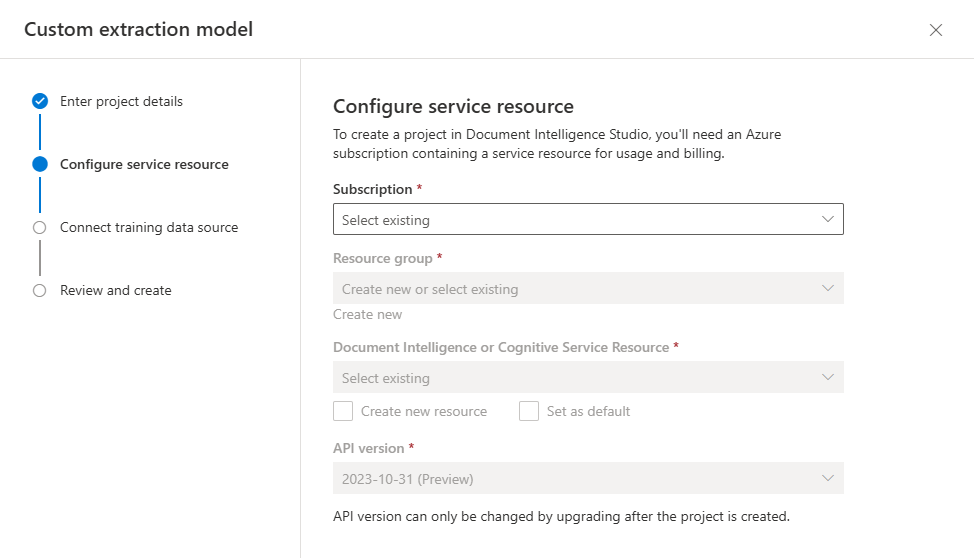
create project, indiquez un nom pour votre projet, entrez éventuellement une description, puis sélectionnez Continuer.À l’étape suivante du flux de travail, choisissez ou créez une ressource d’Intelligence documentaire avant de sélectionner Continuer.
Important
Les modèles neuraux personnalisés sont disponibles uniquement dans quelques régions. Si vous planifiez l’apprentissage d’un modèle neural, veuillez sélectionner ou créer une ressource dans l’une de ces régions prises en charge.
Sélectionnez ensuite le compte de stockage que vous avez utilisé pour charger le jeu de données d’apprentissage de votre modèle personnalisé. Le chemin du dossier doit être vide si vos documents d’apprentissage se trouvent à la racine du conteneur. Si vos documents se trouvent dans un sous-dossier, entrez le chemin d’accès relatif à partir de la racine du conteneur dans le champ Chemin du dossier. Une fois votre compte de stockage configuré, sélectionnez Continuer.
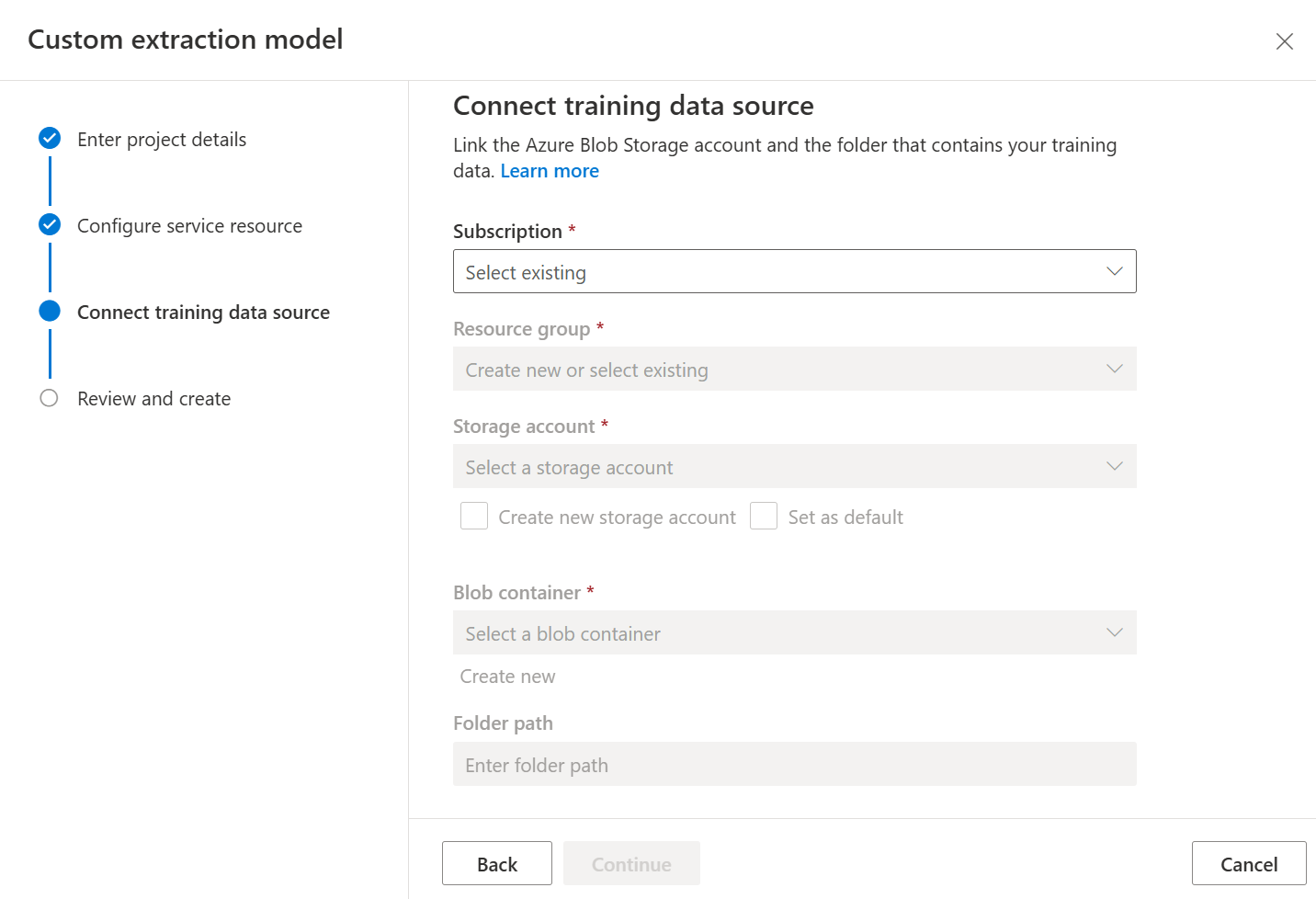
Enfin, passez en revue les paramètres de votre projet et sélectionnez Créer un projet pour créer un nouveau projet. Vous devez maintenant vous trouver dans la fenêtre d’étiquetage et voir les fichiers de votre jeu de données.
Étiqueter vos données
Dans votre projet, la première tâche consiste à étiqueter votre jeu de données avec les champs que vous souhaitez extraire.
Les fichiers que vous avez chargés sur le stockage sont listés à gauche de votre écran. Le premier fichier est prêt à être étiqueté.
Commencez à étiqueter votre jeu de données et à créer votre premier champ en sélectionnant le bouton plus (➕) en haut à droite de l’écran.
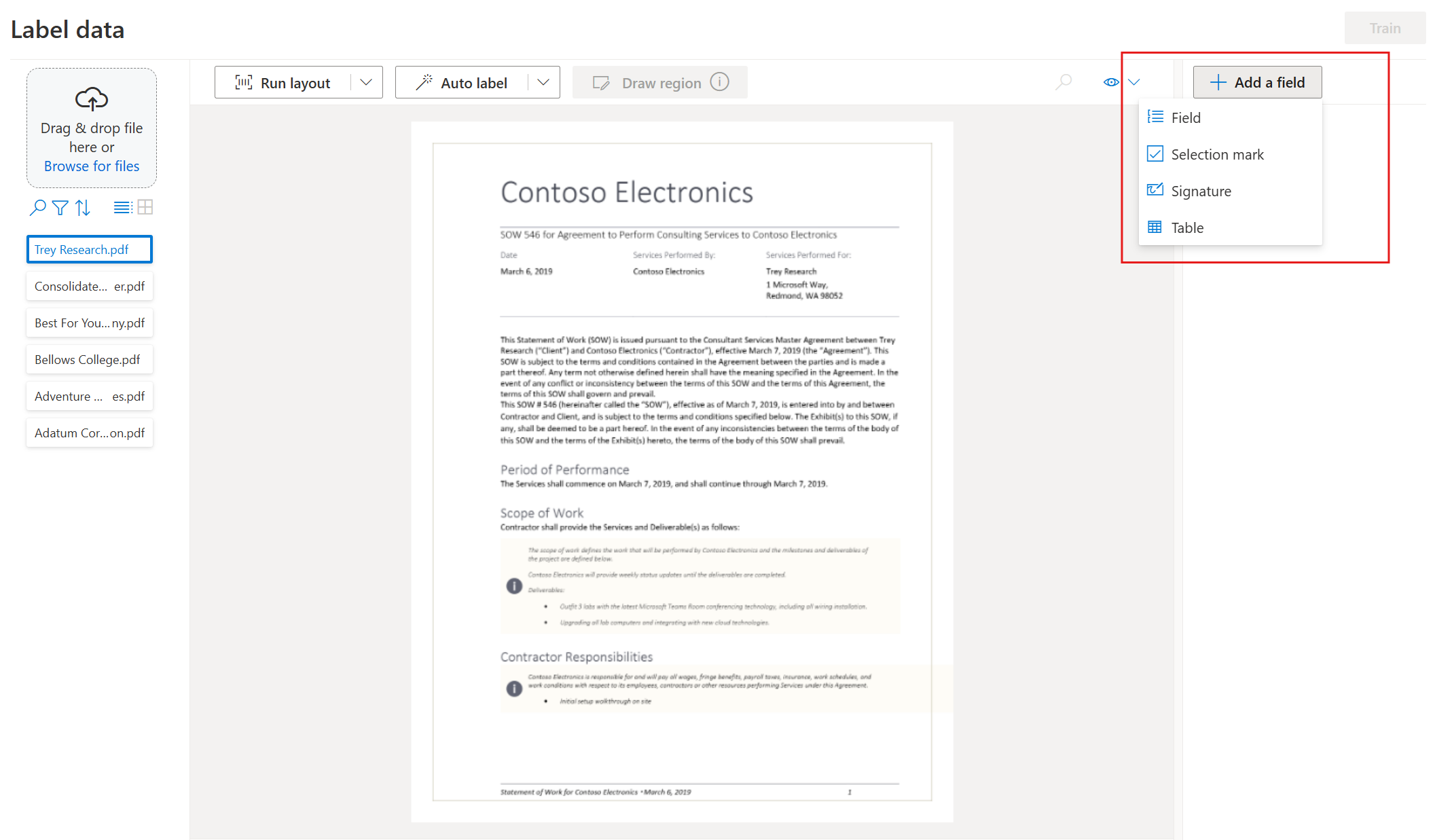
Entrez un nom pour le champ.
Affectez une valeur au champ en choisissant un mot ou des mots dans le document. Sélectionnez le champ dans la liste déroulante ou la liste des champs dans la barre de navigation de droite. La valeur étiquetée se trouve sous le nom du champ dans la liste des champs.
Répétez le processus pour tous les champs que vous souhaitez étiqueter pour votre jeu de données.
Étiquetez les documents restants de votre jeu de données en les sélectionnant et en sélectionnant le texte à étiqueter.
L’ensemble des documents de votre jeu de données sont désormais étiquetés. Les fichiers .labels.json et .ocr.json qui correspondent à chaque document de votre jeu de données d’apprentissage et un nouveau fichier fields.json. Ce jeu de données d’apprentissage est envoyé pour l’apprentissage du modèle.
Entraîner votre modèle
Une fois votre jeu de données étiqueté, vous êtes prêt pour l’apprentissage de votre modèle. Sélectionnez le bouton Apprentissage en haut à droite.
Dans la boîte de dialogue d’apprentissage du modèle, fournissez un ID de modèle unique et éventuellement une description. L’ID de modèle accepte un type de données String.
Pour le mode de génération, sélectionnez le type de modèle dont vous souhaitez effectuer l’apprentissage. En savoir plus sur les types de modèles et les fonctionnalités.
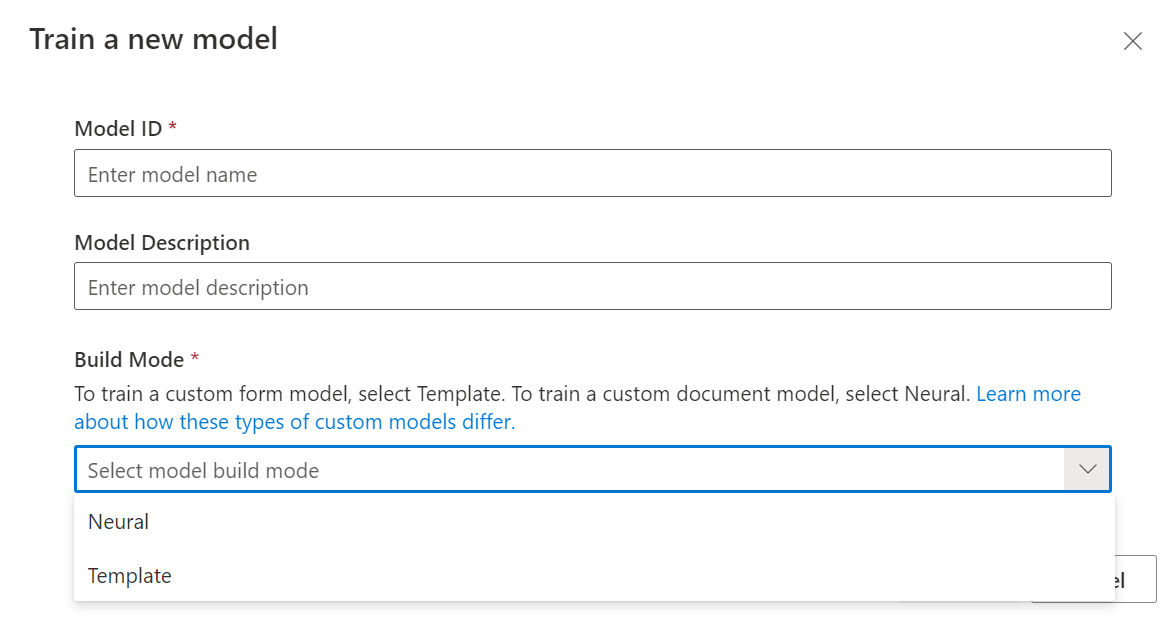
Sélectionnez Apprentissage pour initier le processus d’apprentissage.
L’apprentissage des modèles s’effectue en quelques minutes. L’apprentissage des modèles neuraux peut durer jusqu’à 30 minutes.
Accédez au menu Modèles pour afficher l’état de l’opération d’apprentissage.
Tester le modèle
Une fois l’apprentissage du modèle effectué, vous pouvez tester votre modèle en le sélectionnant dans la page de liste des modèles.
Sélectionnez le modèle et sélectionnez le bouton Test.
Sélectionnez le bouton
+ Addpour sélectionner un fichier pour tester le modèle.Une fois un fichier sélectionné, cliquez sur le bouton Analyser pour tester le modèle.
Les résultats du modèle s’affichent dans la fenêtre principale et les champs extraits sont répertoriés dans la barre de navigation de droite.
Validez votre modèle en évaluant les résultats de chaque champ.
La barre de navigation de droite contient également l’exemple de code permettant d’appeler votre modèle et les résultats JSON de l’API.
Félicitations, vous avez appris à effectuer l’apprentissage d’un modèle personnalisé dans Intelligence documentaire Studio ! Votre modèle est prêt être utilisé avec l’API REST ou le kit SDK pour analyser les documents.
S’applique à : ![]() v2.1. Autre versions : v3.0
v2.1. Autre versions : v3.0
Quand vous utilisez le modèle personnalisé d’Intelligence documentaire, vous fournissez vos propres données d’apprentissage pour l’opération Effectuer l’apprentissage d’un modèle personnalisé afin que l’apprentissage du modèle s’effectue sur des formulaires spécifiques au secteur. Suivez ce guide pour apprendre à collecter et préparer des données afin d’effectuer l’apprentissage du modèle efficacement.
Vous avez besoin d’au moins cinq formulaires remplis du même type.
Si vous souhaitez utiliser des données d’apprentissage étiquetées manuellement, il vous faut pour commencer au moins cinq formulaires remplis du même type. Vous pouvez également utiliser des formulaires sans étiquette en plus du jeu de données requis.
Exigences d’entrée de modèle personnalisé
Commencez par vous assurer que votre jeu de données d’apprentissage respecte les exigences d’entrée de l’Intelligence documentaire.
Formats de fichiers pris en charge :
Modèle PDF Image : JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Pour les PDF et TIFF, jusqu'à 2 000 pages peuvent être traitées (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse de documents est de 500 Mo pour le niveau payant (S0) et de
4Mo pour le niveau gratuit (F0).Les dimensions de l’image doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond environ à un texte de
8points à 150 points par pouce (ppp).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’apprentissage du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle de gabarit et de
1Go pour le modèle neuronal.Pour l’apprentissage du modèle de classification personnalisé, la taille totale des données d’entraînement est de
1Go, avec un maximum de 10 000 pages. Pour 2024-07-31-preview et les versions ultérieures, la taille totale des données de formation est de2Go, avec un maximum de 10 000 pages.
Conseils relatifs aux données d’entraînement
Pour optimiser davantage votre jeu de données à des fins d’apprentissage, suivez ces conseils.
- Utilisez des documents PDF utilisant du texte au lieu d’images. Les PDF numérisés sont traités comme des images.
- Utilisez les exemples dont les champs sont tous renseignés pour les formulaires remplis.
- Utilisez des formulaires avec des valeurs différentes dans chaque champ.
- Utilisez un jeu de données plus volumineux (10 à 15 images) pour les formulaires remplis.
Charger vos données d’entraînement
Une fois que vous réunissez l’ensemble des documents pour l’apprentissage, vous devez le charger sur un conteneur de stockage blob Azure. Si vous ignorez comment créer un compte de stockage Azure avec un conteneur, suivez le Guide de démarrage rapide du Stockage Azure pour le portail Azure. Utilisez le niveau de performance standard.
Si vous souhaitez utiliser des données étiquetées manuellement, chargerz les fichiers .labels.json et .ocr.json correspondant à vos documents d’entraînement. Vous pouvez vous servir de l’outil d’étiquetage des exemples (ou de votre propre interface utilisateur) pour générer ces fichiers.
Organiser vos données dans des sous-dossiers (facultatif)
Par défaut, l’API Entraîner un modèle personnalisé utilise uniquement les documents situés à la racine de votre conteneur de stockage. Toutefois, l’entraînement peut être effectué avec des données dans les sous-dossiers si vous le spécifiez dans l’appel d’API. Normalement, le corps de l’appel Entraîner un modèle personnalisé se présente au format suivant, où <SAS URL> correspond à l’URL de signature d’accès partagé du conteneur :
{
"source":"<SAS URL>"
}
Si vous ajoutez le contenu suivant au corps de la demande, l’API entraîne en utilisant les documents situés dans les sous-dossiers. Le champ "prefix" est facultatif et limite le jeu de données d’apprentissage de manière à utiliser uniquement les fichiers dont les chemins d’accès commencent par la chaîne donnée. Ainsi, avec une valeur de "Test" par exemple, l’API n’examine que les fichiers ou les dossiers qui commencent par le mot Test.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Étapes suivantes
Maintenant que vous avez découvert comment créer un jeu de données d’apprentissage, suivez un guide de démarrage rapide pour effectuer l’apprentissage d’un modèle Intelligence documentaire personnalisé et commencer à l’utiliser sur vos formulaires.