Étiqueter vos énoncés dans Language Studio
Une fois que vous avez créé un schéma pour votre projet, vous devez ajouter des énoncés d’apprentissage à votre projet. Les énoncés doivent être similaires à ce que vos utilisateurs utiliseront lors de l’interaction avec le projet. Lorsque vous ajoutez un énoncé, vous devez lui assigner l’intention à laquelle il appartient. Une fois l’énoncé ajouté, étiquetez les mots dans votre énoncé que vous souhaitez extraire sous forme d’entités.
L’étiquetage des données est une étape cruciale dans le cycle de vie du développement ; ces données seront utilisées à l’étape suivante pour entraîner votre modèle afin qu’il puisse apprendre à partir des données étiquetées. Si vous avez déjà des énoncés étiquetés, vous pouvez directement les importer dans votre projet, mais vous devez vérifier que vos données sont conformes au format de données accepté. Consultez créer un projet pour en savoir plus sur l’importation de données étiquetées dans votre projet. Les données étiquetées informent le modèle de la façon d’interpréter le texte et sont utilisées pour l’entraînement et l’évaluation.
Prérequis
Avant de pouvoir étiqueter des données, vous avez besoin des éléments suivants :
- Un projet créé avec succès.
Pour plus d’informations, consultez le cycle de vie du développement de projets.
Instructions relatives à l’étiquetage des données
Après avoir conçu votre schéma et créé votre projet, vous devez étiqueter vos données. L’étiquetage de vos données est important afin que votre modèle sache quels mots et phrases seront associés aux intentions et entités de votre projet. Vous avez tout intérêt à passer du temps à étiqueter vos énoncés, le but étant d’introduire et d’affiner les données qui seront utilisées pour l’entraînement de vos modèles.
Au moment d’ajouter des énoncés et de les étiqueter, ne perdez pas de vue que :
Les modèles Machine Learning généralisent en fonction des exemples étiquetés que vous fournissez ; plus vous fournissez d’exemples, plus le modèle dispose de points de données pour effectuer de meilleurs généralisations.
La précision, la cohérence et l’exhaustivité de vos données étiquetées sont des facteurs clés pour les performances du modèle.
- Étiqueter avec précision : étiquetez toujours chaque intention et chaque entité avec le type approprié. Incluez uniquement ce que vous souhaitez classifier et extraire, évitez les données inutiles dans vos étiquettes.
- Étiqueter de manière cohérente : une même entité doit avoir la même étiquette dans tous les énoncés.
- Étiqueter de manière complète : fournissez des énoncés variés pour chaque intention. Étiquetez toutes les instances de l’entité dans tous vos énoncés.
Étiqueter clairement les énoncés
Assurez-vous que les concepts auxquels vos entités font référence sont bien définis et séparables. Vérifiez si vous pouvez facilement déterminer les différences de manière fiable. Si ce n’est pas possible, ce manque de distinction peut indiquer que le composant appris aura également des difficultés.
En cas de similarité entre les entités, assurez-vous qu’un aspect de vos données signale la différence entre elles.
Par exemple, si vous avez créé un modèle pour réserver des vols, un utilisateur peut utiliser un énoncé tel que le suivant : « Je veux un vol de Boston à Seattle » La ville d’origine et la ville de destination de ces énoncés sont censées être similaires. Un signal permettant de différencier la ville d’origine peut être le mot de qui la précède souvent.
Veillez à étiqueter toutes les instances de chaque entité dans vos données d’apprentissage et de test. Une approche consiste à utiliser la fonction de recherche pour rechercher toutes les instances d’un mot ou d’une expression dans vos données afin de vérifier si elles sont correctement étiquetées.
Étiquetez les données de test pour les entités qui n’ont pas de composant appris et pour celles qui en ont un. Cette pratique permet de garantir l’exactitude de vos métriques d’évaluation.
Pour les projets multilingues, l’ajout d’énoncés dans d’autres langues accroît les performances du modèle dans ces langue, mais évitez de dupliquer vos données dans toutes les langues que vous souhaitez prendre en charge. Par exemple, pour améliorer les performances d’un bot de calendrier avec les utilisateurs, un développeur peut ajouter des exemples en anglais en anglais, et quelques-uns, en espagnol ou en français. Ils peuvent ajouter des énoncés tels que :
- « Définir une réunion avec Matt et Kevindemain à 12h00. » (français)
- « Répondre comme tentativea à la réunion des mises à jour hebdomadaires. » (français)
- « Cancelar mi próxima reunión. » (Espagnol)
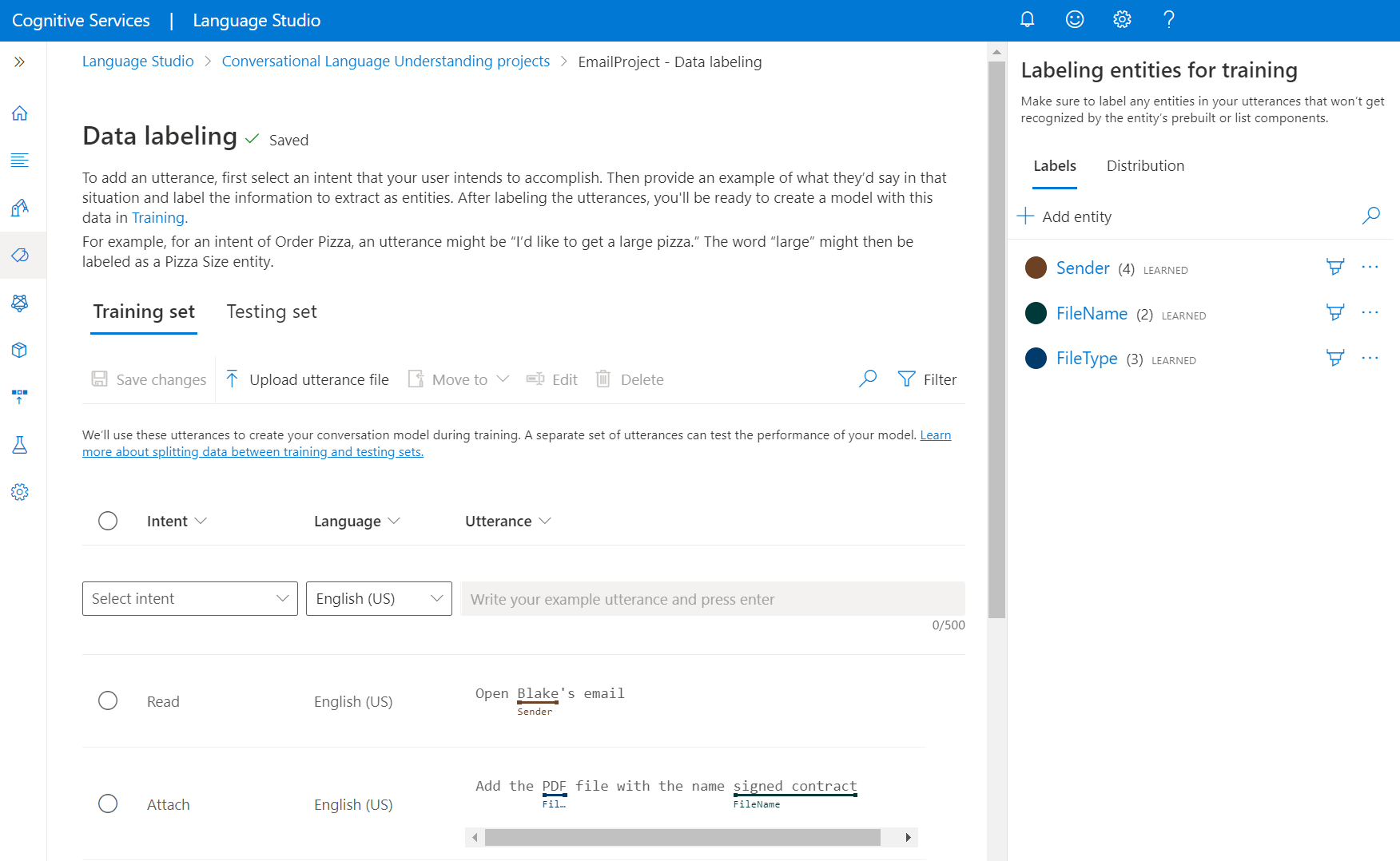
Comment étiqueter vos énoncés
Pour étiqueter vos énoncés, effectuez les étapes suivantes :
Accédez à la page de votre projet dans Langage Studio.
Dans le menu de gauche, sélectionnez Étiquetage des données. Dans cette page, vous pouvez commencer à ajouter vos énoncés et à les étiqueter. Vous pouvez aussi charger vos énoncés directement en cliquant sur Charger un fichier d’énoncé dans le menu supérieur. Veillez à ce qu’il soit conforme au format accepté.
À partir des pivots supérieurs, vous pouvez modifier l’affichage pour qu’il s’agisse d’un ensemble d’apprentissage ou d’un ensemble de tests. En savoir plus sur les ensembles d’apprentissage et de tests et sur leur utilisation pour l’apprentissage et l’évaluation des modèles.
Conseil
Si vous envisagez d’utiliser Fractionner automatiquement l’ensemble de tests à partir du fractionnement des données d’apprentissage, ajoutez tous vos énoncés à l’ensemble d’apprentissage.
Dans le menu déroulant Sélectionner une intention, sélectionnez l’une des intentions, la langue de l’énoncé (pour les projets multilingues) et l’énoncé lui-même. Appuyez sur la touche Entrée dans la zone de texte de l'énoncé pour ajouter l'énoncé.
Vous avez le choix entre deux options pour étiqueter les entités d’un énoncé :
Option Description Étiqueter à l’aide d’un pinceau Sélectionnez l’icône de pinceau en regard d’une entité dans le volet de droite, puis mettez en surbrillance le texte dans l’énoncé que vous voulez étiqueter. Étiqueter à l’aide du menu inclus Mettez en surbrillance le mot que vous souhaitez étiqueter en tant qu’entité, et un menu s’affiche. Sélectionnez l’entité avec laquelle vous souhaitez étiqueter ces mots. Dans le volet de droite, sous le sélecteur de vue Étiquettes, vous pouvez trouver tous les types d’entités de votre projet et le nombre d’instances étiquetées pour chacun d’eux.
Sous le pivot Distribution, vous pouvez afficher la distribution entre les ensembles d’entraînement et de test. Vous disposez de deux options pour l’affichage :
- Nombre total par entité étiquetée, où vous pouvez voir le nombre de toutes les instances étiquetées d’un type d’entité spécifique.
- Énoncés uniques par entité étiquetée, où chaque énoncé est comptabilisé s’il contient au moins une instance étiquetée de cette entité.
- Énoncés par intention, où vous pouvez voir le nombre d’énoncés par intention.


Notes
Les composants de liste et prédéfinis ne figurent pas dans la page d’étiquetage des données, et toutes les étiquettes ici s’appliquent uniquement au composant appris.
Pour supprimer une étiquette :
- À partir de votre énoncé, sélectionnez l’entité dans laquelle vous voulez supprimer une étiquette.
- Faites défiler le menu qui s’affiche, puis sélectionnez Supprimer l’étiquette.
Pour supprimer une entité :
- Sélectionnez l’entité que vous souhaitez modifier dans le volet de droite.
- Sélectionnez les trois points en regard de l’entité, puis sélectionnez l’option souhaitée dans le menu déroulant.
Suggérer des énoncés avec Azure OpenAI
Dans CLU, utilisez Azure OpenAI pour suggérer des énoncés à ajouter à votre projet à l’aide de modèles GPT. Vous devez d’abord obtenir l’accès et créer une ressource dans Azure OpenAI. Vous devez ensuite créer un déploiement pour les modèles GPT. Effectuez les étapes préalables ici.
Avant de commencer, la fonctionnalité des énoncés suggérés n’est disponible que si votre ressource Langue se trouve dans les régions suivantes :
- USA Est
- États-Unis - partie centrale méridionale
- Europe Ouest
Dans la page Étiquetage des données :
- Cliquez sur le bouton Suggérer des énoncés. Dans le volet qui s’ouvre côté droit, vous êtes invité à sélectionner votre ressource Azure OpenAI et votre déploiement.
- Une fois la ressource Azure OpenAI sélectionnée, cliquez sur Se connecter pour permettre à votre ressource Language d’accéder directement à votre ressource Azure OpenAI. Votre ressource Language actuelle se voit attribuer le rôle
Cognitive Services Userauprès de votre ressource Azure OpenAI, ce qui permet à votre ressource Language actuelle d’avoir accès au service d’Azure OpenAI. Si la connexion échoue, suivez les étapes ci-dessous pour ajouter manuellement le rôle approprié à votre ressource Azure OpenAI. - Une fois la ressource connectée, sélectionnez le déploiement. Le modèle recommandé pour le déploiement Azure OpenAI est
text-davinci-002. - Sélectionnez l’intention pour laquelle vous souhaitez obtenir des suggestions. Vérifiez que l’intention que vous avez sélectionnée compte au moins 5 énoncés enregistrés à activer pour les suggestions d’énoncé. Les suggestions fournies par Azure OpenAI sont basées sur les énoncés les plus récents que vous avez ajoutés pour cette intention.
- Sélectionnez Générer des énoncés. Une fois l’opération terminée, les énoncés suggérés apparaissent, entourés d’une ligne en pointillés et accompagnés de la mention Généré par l’IA. Vous devez accepter ou rejeter ces suggestions. Une suggestion acceptée est simplement ajoutée à votre projet, comme si vous l’aviez ajoutée vous-même. Une suggestion rejetée est supprimée entièrement. Seuls les énoncés acceptés font partie de votre projet et sont utilisés à des fins d’entraînement ou de test. Vous pouvez cliquer sur le bouton vert (coche) ou rouge (croix) en regard d’un énoncé pour l’accepter ou le rejeter. Vous pouvez également utiliser les boutons
Accept alletReject alldans la barre d’outils.

L’utilisation de cette fonctionnalité entraîne des frais pour votre ressource Azure OpenAI (nombre de jetons similaire aux énoncés suggérés générés). Vous trouverez des détails sur les tarifs d’Azure OpenAI ici.
Ajouter les configurations nécessaires à la ressource Azure OpenAI
Si la connexion de votre ressource Language à une ressource Azure OpenAI échoue, suivez ces étapes :
Activez la gestion des identités pour votre ressource Language à l’aide des options suivantes :
Votre ressource Language doit disposer de la gestion des identités. Pour l’activer à l’aide du Portail Azure :
- Accéder à votre ressource de langue
- Dans le menu de gauche, sous la section Gestion des ressources, sélectionnez Identité
- Sous l’onglet Attribuée par le système, veillez à définir État sur Activé
Après avoir activé l’identité managée, attribuez le rôle Cognitive Services User à votre ressource Azure OpenAI en utilisant l’identité managée de votre ressource Language.
- Connectez-vous au Portail Azure et accédez à votre ressource Azure OpenAI.
- Cliquez sur l’onglet Access Control (IAM) à gauche.
- Sélectionnez Ajouter > Ajouter une attribution de rôle.
- Sélectionnez « Rôles de fonction de tâche », puis cliquez sur Suivant.
- Sélectionnez
Cognitive Services Userdans la liste des rôles, puis cliquez sur Suivant. - Sélectionnez Attribuer l’accès à « Identité managée », puis sélectionnez « Sélectionner des membres ».
- Sous « Identité managée », sélectionnez « Langue ».
- Recherchez votre ressource et sélectionnez-la. Sélectionnez ensuite sur le bouton Sélectionner ci-dessous et Suivant pour terminer le processus.
- Passez en revue les détails, puis sélectionnez Vérifier + attribuer.

Après quelques minutes, actualisez Language Studio pour vous connecter à Azure OpenAI.