Déplacement des données vers le cluster vFXT - ingestion parallèle des données
Une fois que vous avez créé un cluster vFXT, votre première tâche peut être de déplacer des données vers un nouveau volume de stockage dans Azure. Toutefois, si votre méthode habituelle de déplacement des données consiste à émettre une simple commande de copie à partir d’un client, les performances seront probablement lentes. La copie monothread n’est pas une bonne option pour copier des données vers le stockage back-end du cluster Avere vFXT.
Comme le cluster Avere vFXT est un cache multiclient scalable, le moyen le plus rapide et le plus efficace d’y copier des données est d’utiliser plusieurs clients. Cette technique parallélise l’ingestion des fichiers et des objets.
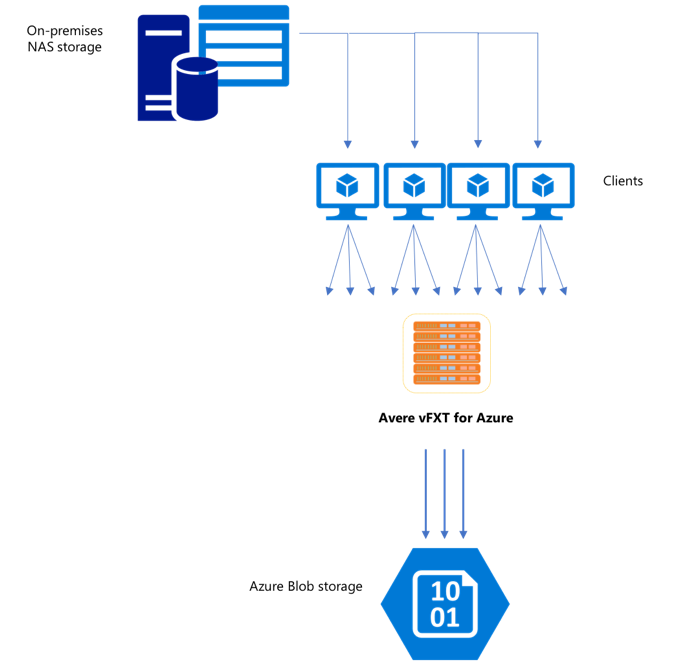
Les commandes cp ou copy couramment utilisées pour transférer des données d’un système de stockage vers un autre sont des processus monothread qui ne copient qu’un seul fichier à la fois. Cela signifie que le serveur de fichiers ne reçoit qu’un fichier à la fois, ce qui représente un gaspillage des ressources du cluster.
Cet article décrit des stratégies de création d’un système de copie de fichiers multiclient et multithread pour déplacer des données vers le cluster Avere vFXT. Il explique les concepts de transfert de fichiers et les points de décision qui peuvent être utilisés pour une copie efficace des données à l’aide de plusieurs clients et de simples commandes de copie.
Il décrit également quelques utilitaires qui peuvent être utiles. L’utilitaire msrsync peut servir à automatiser partiellement le processus de division d’un jeu de données en compartiments et d’utilisation des commandes rsync. Le script parallelcp est un autre utilitaire qui lit le répertoire source et émet automatiquement des commandes de copie. De plus, l’outil rsync peut être utilisé en deux phases pour fournir une copie plus rapide qui offre quand même une cohérence des données.
Cliquez sur le lien pour accéder à une section :
- Exemple de copie manuelle : explication approfondie à l’aide de commandes de copie
- Exemple de rsync en deux phases
- Exemple partiellement automatisé (msrsync)
- Exemple de copie parallèle
Modèle de machine virtuelle d’ingestion de données
Un modèle Resource Manager est disponible sur GitHub pour créer automatiquement une machine virtuelle avec les outils d’ingestion de données parallèle mentionnés dans cet article.
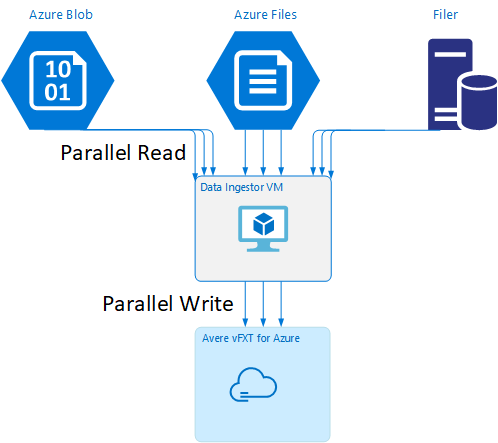
La machine virtuelle d’ingestion de données fait partie d’un tutoriel où la machine virtuelle nouvellement créée monte le cluster Avere vFXT et télécharge son script de démarrage à partir du cluster. Pour plus d’informations, consultez Démarrer une machine virtuelle d’ingestion de données.
Planification stratégique
Quand vous concevez une stratégie pour copier des données en parallèle, vous devez bien comprendre les compromis nécessaires en termes de taille de fichier, de nombre de fichiers et de profondeur des répertoires.
- Lorsque les fichiers sont petits, la métrique d’intérêt est fichiers par seconde.
- Lorsque les fichiers sont volumineux (10 MiBi ou plus), la métrique d’intérêt est octets par seconde.
Chaque processus de copie a un débit et un taux de transfert de fichiers qui peuvent être mesurés en minutant la longueur de la commande de copie et en tenant compte de la taille de fichier et du nombre de fichiers. Les explications sur la façon de mesurer les débits n’entrent pas dans le cadre de ce document, mais il est important de comprendre si vous allez traiter des petits ou des grands fichiers.
Exemple de copie manuelle
Vous pouvez créer manuellement une copie multithread sur un client en exécutant plusieurs commandes de copie à la fois en arrière-plan sur des ensembles de fichiers ou chemins prédéfinis.
La commande Linux/UNIX cp inclut l’argument -p afin de préserver la propriété et les métadonnées mtime. L’ajout de cet argument aux commandes ci-dessous est facultatif. (Il augmente le nombre d’appels de système de fichiers envoyés à partir du client au système de fichiers de destination pour la modification de métadonnées.)
Ce simple exemple copie deux fichiers en parallèle :
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Après avoir émis cette commande, la commande jobs indique que deux threads sont en cours d’exécution.
Structure de noms de fichier prévisibles
Si vos noms de fichier sont prévisibles, vous pouvez utiliser des expressions pour créer des threads de copie parallèle.
Par exemple, si votre répertoire contient 1 000 fichiers numérotés de manière séquentielle de 0001 à 1000, vous pouvez utiliser les expressions suivantes pour créer dix threads parallèles qui copient chacun 100 fichiers :
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Structure de noms de fichier inconnus
Si votre structure de nommage de fichiers n’est pas prévisible, vous pouvez regrouper les fichiers selon les noms de répertoire.
Cet exemple recueille des répertoires entiers à envoyer aux commandes cp pour les exécuter en tant que tâches en arrière-plan :
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Une fois que les fichiers sont collectés, vous pouvez exécuter des commandes de copie parallèle pour copier de manière récursive les sous-répertoires et tout leur contenu :
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Quand ajouter des points de montage
Une fois que vous avez suffisamment de threads parallèles transmis à un seul point de montage de système de fichiers de destination, il arrive un moment où l’ajout de threads supplémentaires ne produit pas davantage de débit. (Le débit est mesuré en fichiers/seconde ou octets/seconde, selon votre type de données.) Pire encore, un threading excessif peut parfois provoquer une dégradation du débit.
Dans ce cas, vous pouvez ajouter des points de montage côté client à d’autres adresses IP de cluster vFXT, en utilisant le même chemin de montage du système de fichiers distant :
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
L’ajout de points de montage côté client vous permet de dupliquer (fork) d’autres commandes de copie sur les points de montage /mnt/destination[1-3] supplémentaires et d’obtenir ainsi davantage de parallélisme.
Par exemple, si vos fichiers sont très volumineux, vous pouvez définir les commandes de copie de façon à utiliser des chemins de destination distincts pour envoyer plus de commandes en parallèle à partir du client à l’origine de la copie.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
Dans l’exemple ci-dessus, l’ensemble des trois points de montage de destination est ciblé par les processus de copie de fichiers clients.
Quand ajouter des clients
Enfin, quand vous avez atteint la limite des capacités des clients, l’ajout d’autres threads de copie ou de points de montage supplémentaires ne génère pas d’autre augmentation de la métrique fichiers/seconde ni octets/seconde. Dans ce cas, vous pouvez déployer un autre client avec le même ensemble de points de montage qui exécutera ses propres ensembles de processus de copie de fichiers.
Exemple :
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Créer des manifestes de fichiers
Une fois que vous avez compris les approches ci-dessus (plusieurs threads de copie par destination, plusieurs destinations par client, plusieurs clients par système de fichiers source accessible via le réseau), tenez compte de la recommandation suivante : générez des manifestes de fichiers, puis utilisez-les avec des commandes de copie sur plusieurs clients.
Ce scénario utilise la commande UNIX find pour créer des manifestes de fichiers ou répertoires :
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Redirigez ce résultat vers un fichier : find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Vous pouvez ensuite itérer au sein du manifeste, à l’aide de commandes BASH pour compter les fichiers et déterminer les tailles des sous-répertoires :
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Enfin, vous devez élaborer les commandes de copie de fichiers réelles pour les clients.
Si vous avez quatre clients, utilisez cette commande :
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Si vous avez cinq clients, utilisez quelque chose comme ceci :
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
Et pour six... Extrapolez en fonction des besoins.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Vous obtiendrez N fichiers résultants, un pour chacun de vos N clients qui contient les noms de chemin des répertoires de niveau quatre produits dans le cadre de la sortie de la commande find.
Chaque fichier permet de générer la commande de copie :
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
La méthode ci-dessus vous donnera N fichiers, chacun avec une commande de copie par ligne, qui peut être exécutée comme un script BASH sur le client.
L’objectif est d’exécuter plusieurs threads de ces scripts simultanément par client en parallèle sur plusieurs clients.
Utiliser un processus rsync en deux phases
L’utilitaire rsync standard ne fonctionne pas bien pour alimenter le stockage cloud via le système Avere vFXT pour Azure, car il génère un grand nombre d’opérations de création et de renommage de fichiers pour garantir l’intégrité des données. Toutefois, vous pouvez utiliser sans problème l’option --inplace avec rsync pour ignorer la procédure de copie plus complète si vous effectuez en suivant une deuxième exécution qui vérifie l’intégrité des fichiers.
Une opération de copie rsync standard crée un fichier temporaire et le remplit avec des données. Si le transfert de données se termine correctement, le fichier temporaire est renommé avec le nom de fichier d’origine. Cette méthode garantit la cohérence même si vous accédez aux fichiers pendant la copie. Par contre, elle génère plus d’opérations d’écriture, ce qui ralentit le déplacement des fichiers dans le cache.
L’option --inplace écrit le nouveau fichier directement dans son emplacement final. La cohérence des fichiers n’est pas garantie pendant le transfert, mais ce n’est pas important si vous préparez un système de stockage à utiliser plus tard.
La seconde opération rsync sert à vérifier la cohérence suite à la première opération. Étant donné que les fichiers ont déjà été copiés, la seconde phase est une analyse rapide pour s’assurer que les fichiers de la destination correspondent aux fichiers de la source. Si des fichiers ne correspondent pas, ils sont recopiés.
Vous pouvez procéder aux deux phases dans une même commande :
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Cette méthode est simple et efficace pour les jeux de données du nombre de fichiers que le gestionnaire de répertoire interne peut gérer. (Ce nombre s’élève généralement à 200 millions de fichiers pour un cluster à 3 nœuds, à 500 millions de fichiers pour un cluster à six nœuds, etc.)
Utiliser l’utilitaire msrsync
L’outil msrsync peut également être utilisé pour déplacer des données vers un système de stockage back-end pour le cluster Avere. Cet outil est conçu pour optimiser l’utilisation de la bande passante en exécutant plusieurs processus rsync parallèles. Il est disponible à partir de GitHub sur https://github.com/jbd/msrsync.
msrsync divise le répertoire source en « compartiments » distincts, puis exécute des processus rsync individuels sur chaque compartiment.
Des tests préliminaires à l’aide d’une machine virtuelle à quatre cœurs ont montré plus d’efficacité lors de l’utilisation de 64 processus. Utilisez l’option msrsync-p pour définir le nombre de processus sur 64.
Vous pouvez aussi utiliser l’argument --inplace avec les commandes msrsync. Si vous utilisez cette option, pensez à exécuter une deuxième commande (comme avec rsync, décrit ci-dessus) pour garantir l’intégrité des données.
msrsync peut uniquement écrire vers et depuis des volumes locaux. La source et la destination doivent être accessibles en tant que montages locaux dans le réseau virtuel du cluster.
Pour utiliser msrsync en vue de remplir un volume cloud Azure avec un cluster Avere, suivez ces instructions :
Installez
msrsyncet ses prérequis (rsync et Python 2.6 ou ultérieur)Déterminez le nombre total de fichiers et répertoires à copier.
Par exemple, utilisez l’utilitaire Avere
prime.pyavec les argumentsprime.py --directory /path/to/some/directory(disponibles en téléchargeant l’URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Si vous n’utilisez pas
prime.py, vous pouvez calculer le nombre d’éléments avec l’outil GNUfindde la façon suivante :find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Divisez le nombre d’éléments par 64 pour déterminer le nombre d’éléments par processus. Utilisez ce nombre avec l’option
-fpour définir la taille des compartiments quand vous exécutez la commande.Émettez la commande
msrsyncpour copier les fichiers :msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Si vous utilisez
--inplace, ajoutez une deuxième exécution sans l’option pour vérifier que les données sont correctement copiées :msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Par exemple, cette commande est conçue pour déplacer 11 000 fichiers dans 64 processus à partir de /test/source-repository vers /mnt/vfxt/repository :
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Utiliser le script de copie parallèle
Le script parallelcp peut également être utile pour le déplacement de données vers le stockage back-end de votre cluster vFXT.
Le script ci-dessous ajoute le fichier exécutable parallelcp. (Ce script est conçu pour Ubuntu ; si vous utilisez une autre distribution, vous devez installer parallel séparément.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Exemple de copie parallèle
Cet exemple utilise le script de copie parallèle pour compiler glibc à l’aide de fichiers sources à partir du cluster Avere.
Les fichiers sources sont stockés sur le point de montage de cluster Avere, et les fichiers objets sont stockés sur le disque dur local.
Ce script utilise le script de copie parallèle ci-dessus. L’option -j est utilisée avec parallelcp et make pour obtenir la parallélisation.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour