Bagottement dans la mise à l’échelle automatique
Cet article décrit le phénomène de bagottement (flapping) dans la mise à l’échelle automatique et comment l’éviter.
Le bagottement fait référence à une condition de boucle qui provoque une série d’événements de mise à l’échelle contraires. Un bagottement se produit quand un événement de mise à l’échelle déclenche l’événement de mise à l’échelle contraire.
La mise à l’échelle automatique évalue une action de scale-in en attente pour déterminer si cette action provoquerait un bagottement. Le cas échéant, la mise à l’échelle automatique peut ignorer l’action de mise à l’échelle et la réévaluer à l’exécution suivante, ou elle peut effectuer une mise à l’échelle d’un nombre d’instances de ressources inférieur à celui spécifié. Le processus d’évaluation de la mise à l’échelle automatique a lieu à chaque exécution du moteur de mise à l’échelle automatique, soit toutes les 30 à 60 secondes, selon le type des ressources.
Pour garantir des ressources adéquates, il n’y a pas d’évaluation du risque de bagottement pour les événements de scale-out. La mise à l’échelle automatique peut uniquement différer un événement de scale-in pour éviter un bagottement.
Par exemple, supposons les règles suivantes :
- Le scale-out augmente le nombre d’instances d’une (1) instance lorsque l’utilisation moyenne du processeur dépasse 50 %.
- Le scale-in diminue le nombre d’instances d’une (1) instance lorsque l’utilisation moyenne du processeur est inférieure à 30 %.
Dans le tableau ci-dessous, au moment T0 lorsque l’utilisation atteint 56 %, une action de scale-out est déclenchée, entraînant une utilisation du processeur de 56 % sur deux instances. Cela donne une moyenne d’utilisation de 28 % pour le groupe identique. Étant donné que 28 % est inférieur au seuil de scale-in, la mise à l’échelle automatique devrait refaire un scale-in. Après le scale-in, le groupe identique serait de nouveau à 56 % d’utilisation du processeur, ce qui déclencherait une nouvelle action de scale-out.
| Temps | Nombre d’instances | CPU% | CPU% par instance | Événement de mise à l’échelle | Nombre d’instances obtenu |
|---|---|---|---|---|---|
| T0 | 1 | 56 % | 56 % | Scale-out | 2 |
| T1 | 2 | 56 % | 28 % | Diminuer le nombre d’instances | 1 |
| T2 | 1 | 56 % | 56 % | Scale-out | 2 |
| T3 | 2 | 56 % | 28 % | Diminuer le nombre d’instances | 1 |
Sans contrôle, il y aurait une série continue d’événements de mise à l’échelle. Toutefois, dans ce cas, le moteur de mise à l’échelle automatique différera l’événement de scale-in au moment T1 et le réévaluera à la prochaine exécution de la mise à l’échelle automatique. Le scale-in se produira uniquement si l’utilisation moyenne du processeur passe en dessous de 30 %.
Le bagottement a souvent les causes suivantes :
- Marge faible ou nulle entre les seuils
- Scale-in ou scale-out de plusieurs instances
- Scale-in et scale-out effectués selon des métriques différentes
Marge faible ou nulle entre les seuils
Pour éviter le bagottement, conservez des marges adéquates entre les seuils de mise à l’échelle.
Par exemple, les règles suivantes où il n’y a aucune marge entre les seuils provoquent un bagottement.
- Effectuer un scale-out quand le nombre de threads est >= 600
- Effectuer un scale-in quand le nombre de threads est < 600
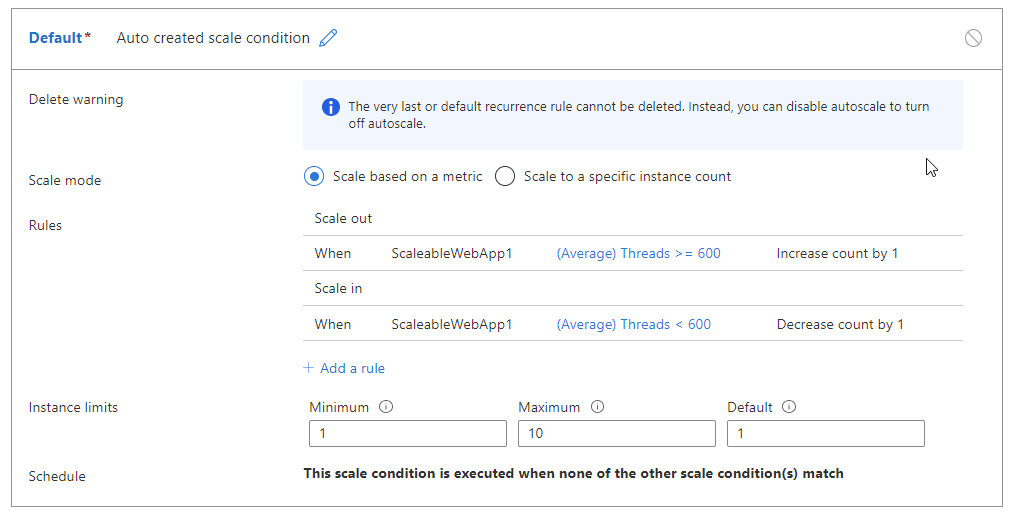
Le tableau ci-dessous présente un résultat possible de ces règles de mise à l’échelle automatique :
| Temps | Nombre d’instances | Nombre de threads | Nombre de threads par instance | Événement de mise à l’échelle | Nombre d’instances obtenu |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Scale-out | 3 |
| T1 | 3 | 1250 | 417 | Diminuer le nombre d’instances | 2 |
- Au moment T0, il y a deux instances qui gèrent 1 250 threads, soit 625 treads par instance. La mise à l’échelle automatique effectue un scale-out vers trois instances.
- Après le scale-out, au moment T1, nous avons les mêmes 1 250 threads, mais avec trois instances, soit seulement 417 threads par instance. Un événement de scale-in est déclenché.
- Avant d’effectuer le scale-in, la mise à l’échelle automatique évalue ce qui se passerait si l’événement de scale-in se produisait. Dans cet exemple, 1250 / 2 = 625, c’est-à-dire 625 threads par instance. La mise à l’échelle automatique devrait alors faire un scale-out immédiatement après le scale-in. Si elle refaisait un scale-out, le processus entier se répéterait, et on aurait une boucle de bagottement.
- Pour éviter cette situation, la mise à l’échelle automatique n’effectue pas le scale-in. La mise à l’échelle automatique ignore l’événement de mise à l’échelle actuel et réévaluera la règle au prochain cycle d’exécution.
Dans ce cas, la mise à l’échelle automatique semble ne pas fonctionner, car aucun événement de mise à l’échelle n’a lieu. Accédez à l’onglet Historique des exécutions dans la page des paramètres de la mise à l’échelle automatique pour voir s’il y a un problème de bagottement.

La définition d’une marge adéquate entre les seuils évite le scénario ci-dessus. Par exemple,
- Effectuer un scale-out quand le nombre de threads est >= 600
- Effectuer un scale-in quand nombre de threads < 400

Si le nombre de threads pour le scale-in est égal à 400, le nombre total de threads devrait passer en dessous de 1 200 pour déclencher un événement de mise à l’échelle. Consultez le tableau ci-dessous.
| Temps | Nombre d’instances | Nombre de threads | Nombre de threads par instance | Événement de mise à l’échelle | Nombre d’instances obtenu |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Scale-out | 3 |
| T1 | 3 | 1250 | 417 | aucun événement de mise à l’échelle | 3 |
| T2 | 3 | 1180 | 394 | scale-in | 2 |
| T3 | 3 | 1180 | 590 | aucun événement de mise à l’échelle | 2 |
Scale-in ou scale-out de plusieurs instances
Pour éviter le bagottement lors d’un scale-in ou scale-out de plusieurs instances, la mise à l’échelle automatique peut effectuer une mise à l’échelle d’un nombre d’instances inférieur à celui spécifié dans la règle.
Par exemple, les règles suivantes peuvent entraîner un bagottement :
- Effectuer un scale-out de 20 quand le nombre de requêtes est >= 200 par instance.
- OU lorsque l’utilisation du processeur est > 70 % par instance.
- Effectuer un scale-in de 10 quand le nombre de requêtes est <= 50 par instance.
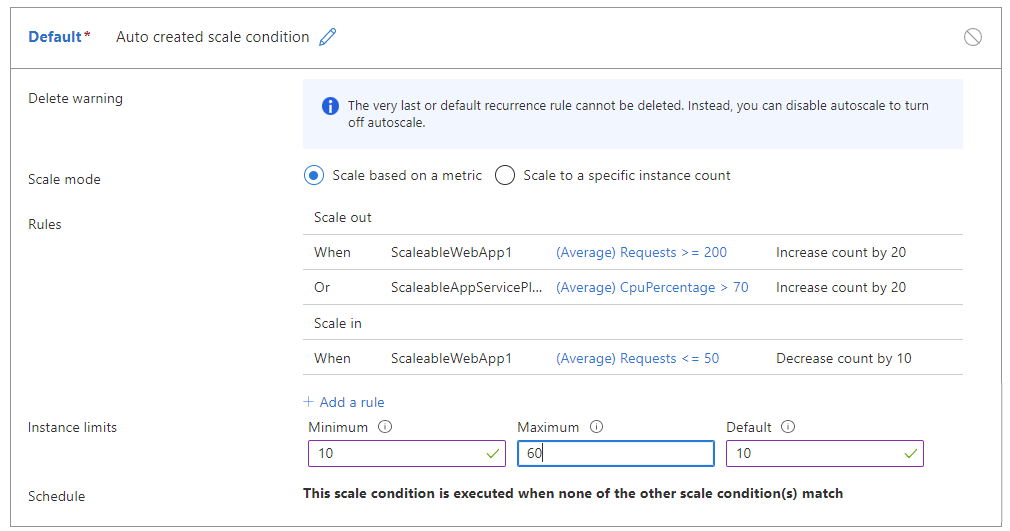
Le tableau ci-dessous présente un résultat possible de ces règles de mise à l’échelle automatique :
| Temps | Nombre d’instances | UC | Nombre de demandes | Événement de mise à l’échelle | Instances obtenues | Commentaires |
|---|---|---|---|---|---|---|
| T0 | 30 | 65 % | 3 000, ou 100 par instance. | Aucun événement de mise à l’échelle | 30 | |
| T1 | 30 | 65 | 1500 | Scale-in de trois instances | 27 | Un scale-in de 10 entraînerait une augmentation estimée du processeur supérieure à 70 %, ce qui déclencherait un événement de scale-out. |
Au moment T0, l’application s’exécute avec 30 instances, un nombre total de requêtes de 3 000 et une utilisation du processeur de 65 % par instance.
Au moment T1, lorsque le nombre de requêtes passe à 1 500, soit 50 requêtes par instance, la mise à l’échelle automatique tente d’effectuer un scale-in de 10 instances pour obtenir 20 instances. Toutefois, la mise à l’échelle automatique estime que la charge du processeur pour 20 instances serait supérieure à 70 %, ce qui déclencherait un événement de scale-out.
Pour éviter le bagottement, le moteur de mise à l’échelle automatique estime l’utilisation du processeur pour un nombre d'instances supérieur à 20, jusqu’à ce qu’il trouve un nombre d’instances où toutes les métriques sont conformes aux seuils définis :
- Maintenir l’utilisation du processeur en dessous de 70 %.
- Maintenir le nombre de requêtes par instance à plus de 50.
- Réduire le nombre d’instances à moins de 30.
Dans ce cas, la mise à l’échelle automatique peut effectuer un scale-in de trois instances, passant ainsi de 30 instances à 27 pour satisfaire aux règles, même si la règle spécifie une diminution de 10. Un message de journal est écrit dans le journal d’activité, avec une description indiquant qu’un scale-down va être effectué avec le nombre d’instances mis à jour pour éviter le bagottement
Si la mise à l’échelle automatique ne trouve pas de nombre d’instances approprié, elle ignore l’événement de scale-in et le réévaluera au prochain cycle d’exécution.
Notes
Si le moteur de mise à l’échelle automatique détecte un risque de bagottement après mise à l’échelle vers le nombre cible d’instances, il essaie également d’effectuer une mise à l’échelle vers un nombre inférieur d’instances compris entre le nombre actuel et le nombre cible. Si le bagottement ne se produit pas dans cette plage, la mise à l’échelle automatique continue l’opération de mise à l’échelle avec la nouvelle cible.
Fichiers journaux
Recherchez les événements de bagottement (flapping) dans le journal d’activité avec la requête suivante :
// Activity log, CategoryValue: Autoscale
// Lists latest Autoscale operations from the activity log, with OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action
AzureActivity
|where CategoryValue =="Autoscale" and OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action"
|sort by TimeGenerated desc
Voici un exemple d’enregistrement de journal d’activité pour le bagottement :

{
"eventCategory": "Autoscale",
"eventName": "FlappingOccurred",
"operationId": "1111bbbb-22cc-dddd-ee33-ffffff444444",
"eventProperties":
"{"Description":"Scale down will occur with updated instance count to avoid flapping.
Resource: '/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan'.
Current instance count: '6',
Intended new instance count: '1'.
Actual new instance count: '4'",
"ResourceName":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan",
"OldInstancesCount":6,
"NewInstancesCount":4,
"ActiveAutoscaleProfile":{"Name":"Auto created scale condition",
"Capacity":{"Minimum":"1","Maximum":"30","Default":"1"},
"Rules":[{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Average","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"GreaterThanOrEqual","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Increase","Type":"ChangeCount","Value":"10","Cooldown":"PT1M"}},{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Max","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"LessThan","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Decrease","Type":"ChangeCount","Value":"5","Cooldown":"PT1M"}}]}}",
"eventDataId": "dddd3333-ee44-5555-66ff-777777aaaaaa",
"eventSubmissionTimestamp": "2022-09-13T07:20:41.1589076Z",
"resource": "scaleableappserviceplan",
"resourceGroup": "RG-001",
"resourceProviderValue": "MICROSOFT.WEB",
"subscriptionId": "aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e",
"activityStatusValue": "Succeeded"
}
Étapes suivantes
Pour en savoir plus sur la mise à l’échelle automatique, consultez les ressources suivants :