Déployer un conteneur Azure SQL Edge dans Kubernetes
Important
Azure SQL Edge ne prend plus en charge la plateforme ARM64.
Azure SQL Edge peut être déployé sur un cluster Kubernetes à la fois en tant que module IoT Edge par le biais d’une instance d’Azure IoT Edge exécutée sur Kubernetes, ou en tant que pod conteneur autonome. Dans la suite de cet article, nous nous concentrerons sur le déploiement d’un conteneur autonome sur un cluster Kubernetes. Pour plus d’informations sur le déploiement d’Azure IoT Edge sur Kubernetes, consultez Azure IoT Edge sur Kubernetes (préversion).
Ce tutoriel explique comment configurer une instance d’Azure SQL Edge à haut niveau de disponibilité dans un conteneur sur un cluster Kubernetes.
- Créer un mot de passe AS
- Créer un stockage
- Créer le déploiement
- Se connecter à SQL Server Management Studio (SSMS)
- Vérifier la défaillance et la récupération
Kubernetes 1.6 et versions ultérieures prend en charge les classes de stockage, les revendications de volume persistant et le type de volume de disque Azure. Vous pouvez créer et gérer vos instances d'Azure SQL Edge en mode natif dans Kubernetes. L’exemple de cet article indique comment créer un déploiement pour obtenir une configuration de haute disponibilité similaire à une instance de cluster de basculement de disque partagé. Dans cette configuration, Kubernetes joue le rôle de l’orchestrateur de cluster. En cas de défaillance d'une instance d'Azure SQL Edge dans un conteneur, l'orchestrateur démarre une autre instance du conteneur qui se joint au même stockage persistant.
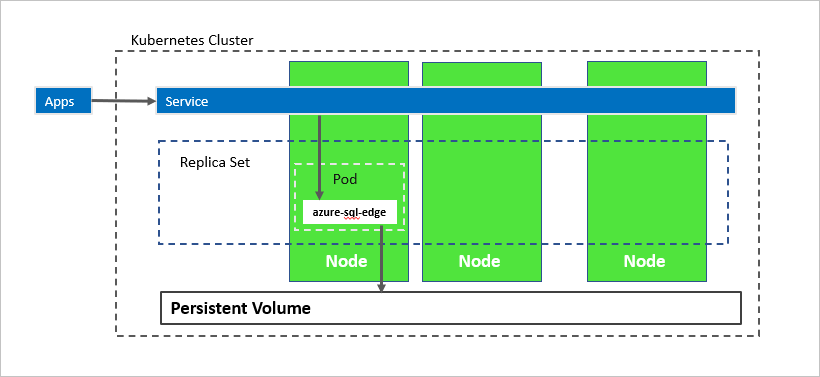
Dans le diagramme précédent, azure-sql-edge est un conteneur dans un Pod. Kubernetes orchestre les ressources dans le cluster. Un jeu de réplicas garantit que le pod est automatiquement récupéré après une défaillance de nœud. Les applications se connectent au service. Dans ce cas, le service représente un équilibreur de charge qui héberge une adresse IP restant la même après la défaillance de azure-sql-edge.
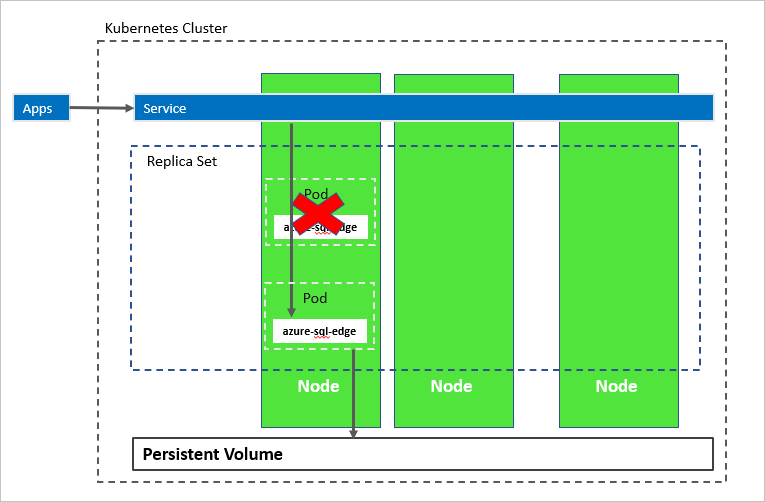
Dans le diagramme suivant, le conteneur azure-sql-edge a échoué. En tant qu’orchestrateur, Kubernetes garantit le nombre correct d’instances saines dans le jeu de réplicas et démarre un nouveau conteneur en fonction de la configuration. L’orchestrateur démarre un nouveau pod sur le même nœud et azure-sql-edge se reconnecte au même stockage persistant. Le service se connecte à azure-sql-edge recréé.
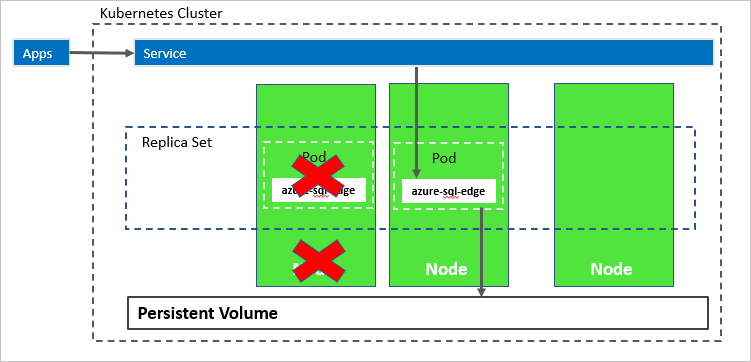
Dans le diagramme suivant, le nœud hébergeant le conteneur azure-sql-edge a échoué. L’orchestrateur démarre un nouveau pod sur un nœud différent et azure-sql-edge se reconnecte au même stockage persistant. Le service se connecte à azure-sql-edge recréé.
Prérequis
Cluster Kubernetes
Ce didacticiel requiert un cluster Kubernetes. Les étapes utilisent kubectl pour gérer le cluster.
Pour les besoins de ce tutoriel, nous utilisons Azure Kubernetes Service pour déployer Azure SQL Edge. Consultez Déployer un cluster Azure Kubernetes Service (AKS) pour créer et se connecter à un cluster Kubernetes à nœud unique dans AKS avec
kubectl.
Notes
Pour une protection contre les défaillances de nœuds, un cluster Kubernetes requiert plusieurs nœuds.
Azure CLI
- Les instructions de ce tutoriel ont été validées avec Azure CLI 2.10.1.
Créer un espace de noms Kubernetes pour le déploiement de SQL Edge
Créez un espace de noms dans le cluster Kubernetes. Cet espace de noms est utilisé pour déployer SQL Edge et tous les artefacts requis. Pour plus d’informations sur les espaces de noms Kubernetes, consultez Espaces de noms.
kubectl create namespace <namespace name>
Créer un mot de passe AS
Créez un mot de passe AS dans le cluster Kubernetes. Kubernetes peut gérer des informations de configuration sensibles, comme des mots de passe en tant que secrets.
La commande suivante crée un mot de passe pour le compte AS :
kubectl create secret generic mssql --from-literal=SA_PASSWORD="MyC0m9l&xP@ssw0rd" -n <namespace name>
Remplacez MyC0m9l&xP@ssw0rd par un mot de passe complexe.
Créer un stockage
Configurez un volume persistant et une revendication de volume persistant dans le cluster Kubernetes. Suivez les étapes ci-dessous :
Créez un manifeste pour définir la classe de stockage et la revendication de volume persistant. Le manifeste spécifie le fournisseur de stockage, les paramètres et la stratégie de récupération. Le cluster Kubernetes utilise ce manifeste pour créer le stockage persistant.
L’exemple de YAML suivant définit une classe de stockage et une revendication de volume persistant. Le fournisseur de classe de stockage est
azure-disk, car ce cluster Kubernetes est dans Azure. Le type de compte de stockage estStandard_LRS. La revendication de volume persistant est nomméemssql-data. Les métadonnées de revendication de volume persistant incluent une annotation qui les reconnecte à la classe de stockage.kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: azure-disk provisioner: kubernetes.io/azure-disk parameters: storageaccounttype: Standard_LRS kind: managed --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: mssql-data annotations: volume.beta.kubernetes.io/storage-class: azure-disk spec: accessModes: - ReadWriteOnce resources: requests: storage: 8GiEnregistrez le fichier (par exemple, pvc.yaml).
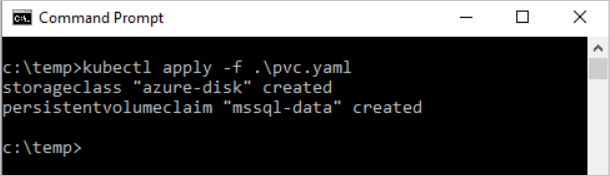
Créez la revendication de volume persistant dans Kubernetes.
kubectl apply -f <Path to pvc.yaml file> -n <namespace name><Path to pvc.yaml file>est l’emplacement où vous avez enregistré le fichier.Le volume persistant est automatiquement créé en tant que compte de stockage Azure et lié à la revendication de volume persistant.
Vérifiez la revendication de volume persistant.
kubectl describe pvc <PersistentVolumeClaim> -n <name of the namespace><PersistentVolumeClaim>est le nom de la revendication de volume persistant.Dans l’étape précédente, la revendication de volume persistant est nommée
mssql-data. Pour afficher les métadonnées relatives à la revendication de volume persistant, exécutez la commande suivante :kubectl describe pvc mssql-data -n <namespace name>Les métadonnées retournées incluent une valeur appelée
Volume. Cette valeur correspond au nom du blob.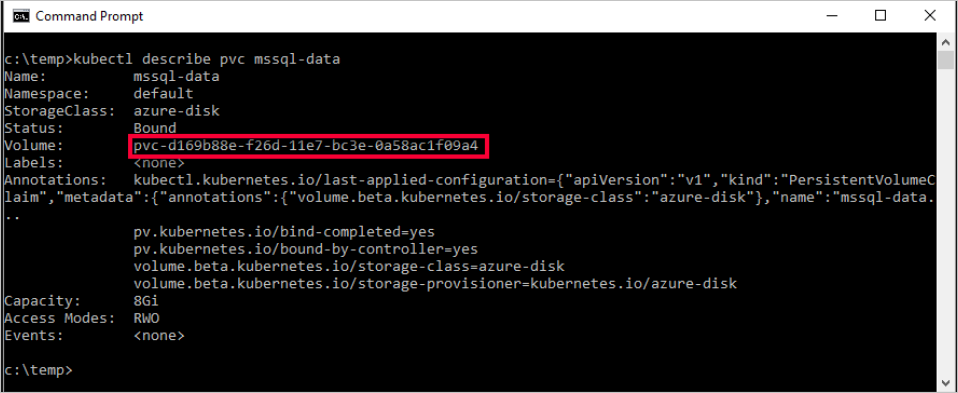
Vérifiez le volume persistant.
kubectl describe pv -n <namespace name>kubectlretourne les métadonnées relatives au volume persistant automatiquement créé et lié à la revendication de volume persistant.
Créer le déploiement
Dans cet exemple, le conteneur qui héberge l'instance d'Azure SQL Edge est décrit comme un objet de déploiement Kubernetes. Le déploiement crée un jeu de réplicas. Le jeu de réplicas crée le pod.
Dans cette étape, créez un manifeste pour décrire le conteneur en fonction de l'image Docker d'Azure SQL Edge. Le manifeste fait référence à la revendication de volume persistant mssql-data et au secret mssql que vous avez déjà appliqué au cluster Kubernetes. Le manifeste décrit également un service. Ce service est un équilibreur de charge. L'équilibreur de charge garantit la persistance de l'adresse IP après la récupération de l'instance d'Azure SQL Edge.
Créez un manifeste (fichier YAML) pour décrire le déploiement. L'exemple suivant décrit un déploiement, avec un conteneur basé sur l'image de conteneur Azure SQL Edge.
apiVersion: apps/v1 kind: Deployment metadata: name: sqledge-deployment spec: replicas: 1 selector: matchLabels: app: sqledge template: metadata: labels: app: sqledge spec: volumes: - name: sqldata persistentVolumeClaim: claimName: mssql-data containers: - name: azuresqledge image: mcr.microsoft.com/azure-sql-edge:latest ports: - containerPort: 1433 volumeMounts: - name: sqldata mountPath: /var/opt/mssql env: - name: MSSQL_PID value: "Developer" - name: ACCEPT_EULA value: "Y" - name: SA_PASSWORD valueFrom: secretKeyRef: name: mssql key: SA_PASSWORD - name: MSSQL_AGENT_ENABLED value: "TRUE" - name: MSSQL_COLLATION value: "SQL_Latin1_General_CP1_CI_AS" - name: MSSQL_LCID value: "1033" terminationGracePeriodSeconds: 30 securityContext: fsGroup: 10001 --- apiVersion: v1 kind: Service metadata: name: sqledge-deployment spec: selector: app: sqledge ports: - protocol: TCP port: 1433 targetPort: 1433 name: sql type: LoadBalancerCopiez le code précédent dans un nouveau fichier, nommé
sqldeployment.yaml. Utilisez les valeurs suivantes :MSSQL_PID
value: "Developer": Définit le conteneur pour qu'il exécute Azure SQL Edge Developer Edition. L’édition Développeur n’est pas concédée sous licence pour les données de production. Si le déploiement est destiné à une utilisation en production, définissez l'édition surPremium.Notes
Pour plus d'informations, consultez Comment obtenir une licence Azure SQL Edge.
persistentVolumeClaim: Cette valeur requiert une entrée pourclaimName:qui correspond au nom utilisé pour la revendication de volume persistant. Ce didacticiel utilisemssql-data.name: SA_PASSWORD: Configure l’image de conteneur pour définir le mot de passe AS, comme défini dans cette section.valueFrom: secretKeyRef: name: mssql key: SA_PASSWORDQuand Kubernetes déploie le conteneur, il fait référence au secret nommé
mssqlpour obtenir la valeur du mot de passe.
Notes
En utilisant le type de service
LoadBalancer, l'instance d'Azure SQL Edge est accessible à distance (via Internet) sur le port 1433.Enregistrez le fichier (par exemple,
sqledgedeploy.yaml).Créez le déploiement.
kubectl apply -f <Path to sqledgedeploy.yaml file> -n <namespace name><Path to sqldeployment.yaml file>est l’emplacement où vous avez enregistré le fichier.
Le déploiement et le service sont créés. L'instance d'Azure SQL Edge se trouve dans un conteneur connecté au stockage persistant.
Pour afficher l'état du pod, saisissez
kubectl get pod -n <namespace name>.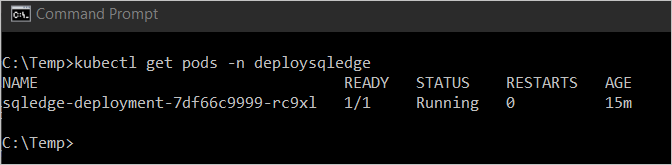
Dans l’image précédente, le pod présente l’état
Running. Cet état indique que le conteneur est prêt. Cette opération peut prendre plusieurs minutes.Notes
Une fois le déploiement créé, plusieurs minutes peuvent être nécessaires avant que le pod ne soit visible. Le retard est dû au fait que le cluster extrait l'image du conteneur Azure SQL Edge du hub Docker. Une fois l’image extraite pour la première fois, les déploiements ultérieurs peuvent être plus rapides si le déploiement se fait sur un nœud sur lequel l’image est déjà mise en cache.
Vérifiez que les services sont en cours d'exécution. Exécutez la commande suivante :
kubectl get services -n <namespace name>Cette commande retourne des services en cours d’exécution, ainsi que les adresses IP internes et externes des services. Notez l’adresse IP externe pour le service
mssql-deployment. Utilisez cette adresse IP pour vous connecter à Azure SQL Edge.
Pour plus d’informations sur l’état des objets dans le cluster Kubernetes, exécutez :
az aks browse --resource-group <MyResourceGroup> --name <MyKubernetesClustername>
Se connecter à l'instance d'Azure SQL Edge
Si vous avez configuré le conteneur comme décrit, vous pouvez vous connecter à une application à partir de l’extérieur du réseau virtuel Azure. Utilisez le compte sa et l’adresse IP externe pour le service. Utilisez le mot de passe que vous avez configuré en tant que secret Kubernetes. Pour plus d’informations sur la connexion à une instance d’Azure SQL Edge, consultez Se connecter à Azure SQL Edge.
Vérifier la défaillance et la récupération
Pour vérifier l’échec et la récupération, vous pouvez supprimer le pod. Procédez comme suit :
Répertoriez le pod qui exécute Azure SQL Edge.
kubectl get pods -n <namespace name>Notez le nom du pod qui exécute Azure SQL Edge.
Supprimer le pod.
kubectl delete pod sqledge-deployment-7df66c9999-rc9xlsqledge-deployment-7df66c9999-rc9xlest la valeur retournée de l’étape précédente pour le nom du pod.
Kubernetes recrée automatiquement le pod pour récupérer une instance d’Azure SQL Edge et se connecter au stockage persistant. Utilisez kubectl get pods pour vérifier qu’un nouveau pod est déployé. Utilisez kubectl get services pour vérifier que l’adresse IP du nouveau conteneur est la même.
Résumé
Dans ce tutoriel, vous avez appris à déployer des conteneurs Azure SQL Edge sur un cluster Kubernetes à des fins de haute disponibilité.
- Créer un mot de passe AS
- Créer un stockage
- Créer le déploiement
- Se connecter à Azure SQL Edge Management Studios (SSMS)
- Vérifier la défaillance et la récupération