Tutoriel : Synchroniser des données de SQL Edge sur le Stockage Blob Azure à l’aide d’Azure Data Factory
Important
Azure SQL Edge ne prend plus en charge la plateforme ARM64.
Ce tutoriel vous montre comment utiliser Azure Data Factory pour synchroniser de façon incrémentielle les données d’une table appartenant à une instance Azure SQL Edge avec le Stockage Blob Azure.
Avant de commencer
Si vous n’avez pas encore créé de base de données ou de table dans votre déploiement Azure SQL Edge, créez-en une à l’aide de l’une des méthodes suivantes :
Utilisez SQL Server Management Studio ou Azure Data Studio pour vous connecter à SQL Edge. Exécutez un script SQL pour créer la base de données et la table.
Créez une base de données et une table à l’aide de sqlcmd en vous connectant directement au module SQL Edge. Pour plus d’informations, consultez Se connecter au moteur de base de données avec sqlcmd.
Utilisez SQLPackage.exe pour déployer un fichier de package DAC sur le conteneur SQL Edge. Vous pouvez automatiser ce processus en spécifiant l’URI du fichier SqlPackage dans le cadre de la configuration des propriétés souhaitées du module. Vous pouvez également utiliser directement l’outil client SqlPackage.exe pour déployer un package DAC sur SQL Edge.
Pour plus d’informations sur le téléchargement de SqlPackage.exe, consultez Télécharger et installer sqlpackage. Voici quelques exemples de commandes pour SqlPackage.exe. Pour plus d’informations, consultez la documentation de SqlPackage.exe.
Créer un package DAC
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Appliquer un package DAC
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Créer une table et une procédure SQL pour stocker et mettre à jour les niveaux de filigrane
Une table de filigranes est utilisée pour stocker la date et l’heure auxquelles les données ont été synchronisées pour la dernière fois avec le stockage Azure. Une procédure stockée Transact-SQL (T-SQL) est utilisée pour mettre à jour la table de filigranes après chaque synchronisation.
Exécutez ces commandes sur l’instance SQL Edge :
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Créer un pipeline Data Factory
Dans cette section, vous allez créer un pipeline Azure Data Factory pour synchroniser des données d’une table dans Azure SQL Edge vers le Stockage Blob Azure.
Créer une fabrique de données avec l’interface utilisateur Data Factory
Créez une fabrique de données en suivant les instructions de ce tutoriel.
Créer un pipeline Data Factory
Dans la page Prise en main de l’interface utilisateur Data Factory, sélectionnez Créer un pipeline.

Dans la page Général de la fenêtre Propriétés du pipeline, entrez le nom PeriodicSync.
Ajoutez l’activité Recherche pour obtenir l’ancienne valeur de filigrane. Dans le volet Activités, développez Général et faites glisser l’activité Recherche vers la surface du concepteur de pipeline. Remplacez le nom de l’activité par OldWatermark.
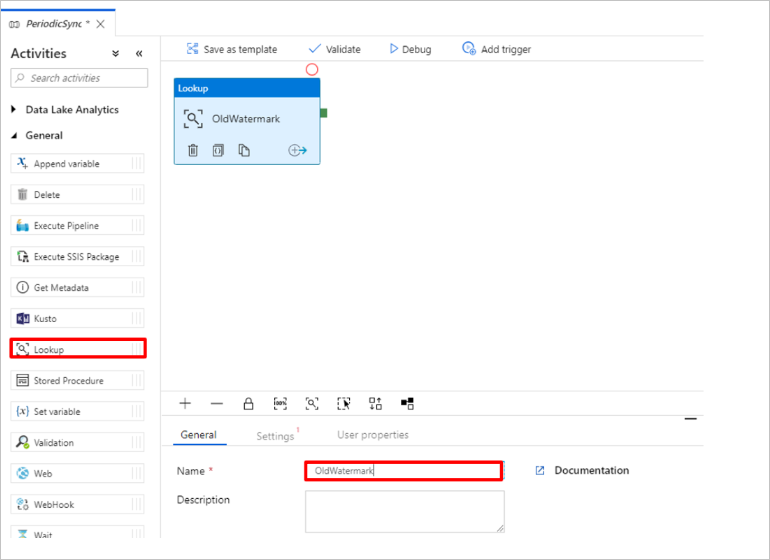
Basculez vers l’onglet Paramètres et sélectionnez Nouveau pour Jeu de données source. Vous créez maintenant un jeu de données pour représenter les données de la table de filigranes. Cette table contient l’ancien filigrane utilisé dans l’opération de copie précédente.
Dans la fenêtre Nouveau jeu de données, sélectionnez Azure SQL Server, puis Continuer.
Dans la fenêtre Définir les propriétés du jeu de données, sous Nom, entrez WatermarkDataset.
Pour Service lié, sélectionnez Nouveau, puis effectuez ces étapes :
Sous Nom, entrez SQLDBEdgeLinkedService.
Sous Nom du serveur, entrez les détails de votre serveur SQL Edge.
Sélectionnez le Nom de la base de données dans la liste déroulante.
Entrez votre nom d’utilisateur et votre mot de passe.
Pour tester la connexion à l’instance SQL Edge, sélectionnez Tester la connexion.
Cliquez sur Créer.
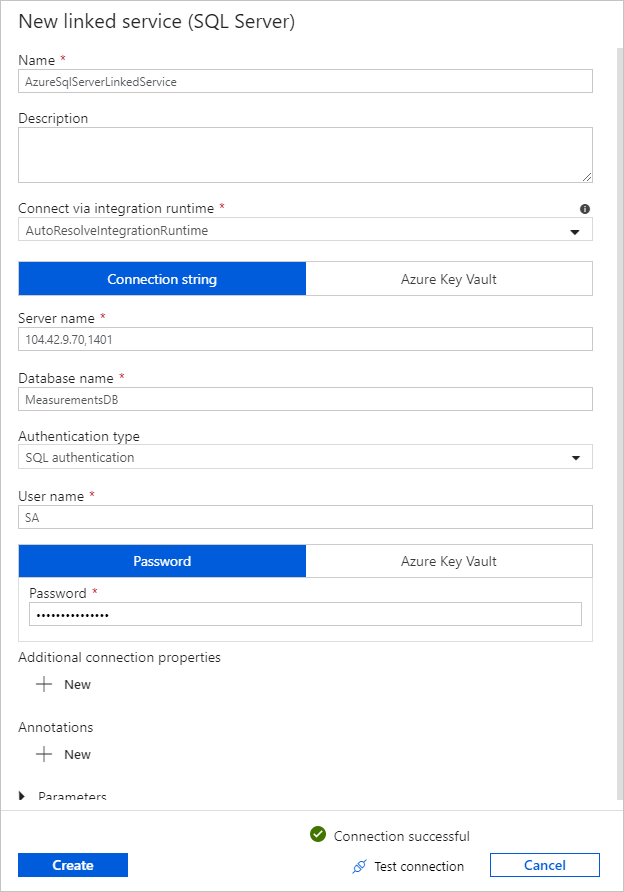
Cliquez sur OK.
Sous l’onglet Paramètres, sélectionnez Modifier.
Dans l’onglet Connexion, sélectionnez
[dbo].[watermarktable]pour Table. Si vous souhaitez voir un aperçu des données de la table, sélectionnez Aperçu des données.Basculez vers l’éditeur de pipeline en sélectionnant l’onglet Pipeline en haut ou en sélectionnant le nom du pipeline dans l’arborescence à gauche. Dans la fenêtre de propriétés de l’activité Recherche, vérifiez que WatermarkDataset est sélectionné dans la liste Jeu de données source.
Dans le volet Activités, développez Général et faites glisser une autre activité Recherche vers la surface du concepteur de pipeline. Définissez le nom sur NewWatermark sous l’onglet Général de la fenêtre de propriétés. Cette activité de recherche obtient la nouvelle valeur de filigrane dans la table qui contient les données sources pour la copier dans la destination.
Dans la fenêtre de propriétés de la deuxième activité Recherche, basculez vers l’onglet Paramètres et sélectionnez Nouveau pour créer un jeu de données qui pointe vers la table source contenant la nouvelle valeur de filigrane.
Dans la fenêtre Nouveau jeu de données, sélectionnez Instance SQL Edge, puis Continuer.
Dans la fenêtre Définir les propriétés, sous Nom, entrez SourceDataset. Sous Service lié, sélectionnez SQLDBEdgeLinkedService.
Sous Table, sélectionnez la table à synchroniser. Vous pouvez également spécifier une requête pour ce jeu de données, comme indiqué plus loin dans le tutoriel. La requête a la priorité sur la table spécifiée à cette étape.
Sélectionnez OK.
Basculez vers l’éditeur de pipeline en sélectionnant l’onglet Pipeline en haut ou en sélectionnant le nom du pipeline dans l’arborescence à gauche. Dans la fenêtre de propriétés de l’activité de recherche, vérifiez que SourceDataset est sélectionné dans la liste Jeu de données source.
Sélectionnez Requête sous Utiliser la requête. Mettez à jour le nom de la table dans la requête suivante, puis entrez la requête. Vous sélectionnez uniquement la valeur maximale de
timestampdans la table. Veillez à sélectionner Première ligne uniquement.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];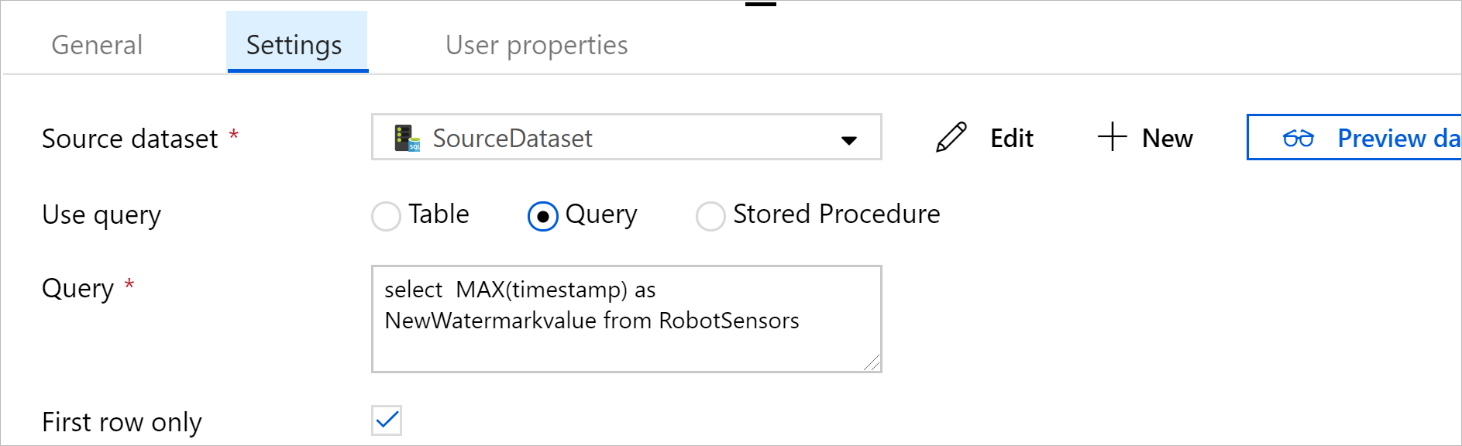
Dans le volet Activités, développez Déplacer et transformer, puis faites glisser l’activité Copie du volet Activités vers la surface du concepteur. Définissez le nom de l’activité sur IncrementalCopy.
Connectez les deux activités Recherche à l’activité Copie en faisant glisser le bouton vert attaché aux activités Recherche vers l’activité Copie. Relâchez le bouton de la souris lorsque la couleur de bordure de l’activité Copie passe au bleu.
Sélectionnez l’activité Copie et vérifiez que vous voyez les propriétés de l’activité dans la fenêtre Propriétés.
Basculez vers l’onglet Source dans la fenêtrePropriétés, et effectuez les étapes suivantes :
Dans la zone Jeu de données source, sélectionnez SourceDataset.
Sous Utiliser la requête, sélectionnez Requête.
Entrez la requête SQL dans la zone Requête. Voici un exemple de requête :
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';Sous l’onglet Récepteur, sélectionnez Nouveau sous Jeu de données récepteur.
Dans ce tutoriel, le magasin de données récepteur est un stockage Blob Azure. Sélectionnez Stockage Blob Azure, puis Continuer dans la fenêtre Nouveau jeu de données.
Dans la fenêtre Sélectionner le format, sélectionnez le format de vos données, puis Continuer.
Dans la fenêtre Définir les propriétés, sous Nom, entrez SinkDataset. Sous Service lié, sélectionnez Nouveau. Vous créez maintenant une connexion (un service lié) à votre stockage Blob Azure.
Dans la fenêtre Nouveau service lié (stockage Blob Azure) , effectuez ces étapes :
Dans la zone Nom, entrez AzureStorageLinkedService.
Sous Nom du compte de stockage, sélectionnez le compte de stockage Azure de votre abonnement Azure.
Testez la connexion, puis sélectionnez Terminer.
Dans la fenêtre Définir les propriétés, vérifiez que AzureStorageLinkedService est sélectionné sous Service lié. Sélectionnez Créer et OK.
Sous l’onglet Récepteur, sélectionnez Modifier.
Accédez à l’onglet Connexion de SinkDataset et effectuez ces étapes :
Sous Chemin d’accès au fichier, entrez
asdedatasync/incrementalcopy, oùasdedatasynccorrespond au nom du conteneur d’objets blob etincrementalcopyau nom du dossier. Créez le conteneur s’il n’existe pas ou utilisez le nom d’un conteneur existant. Azure Data Factory crée automatiquement le dossier de sortieincrementalcopys’il n’existe pas. Vous pouvez également utiliser le bouton Parcourir pour le chemin d’accès du fichier afin d’accéder à un dossier dans un conteneur d’objets blob.Pour la partie Fichier du chemin d’accès au fichier, sélectionnez Ajouter du contenu dynamique [Alt+P], puis entrez
@CONCAT('Incremental-', pipeline().RunId, '.txt')dans la fenêtre qui s’ouvre. Cliquez sur Terminer. Le nom de fichier est généré dynamiquement par l’expression. Chaque exécution de pipeline possède un ID unique. L’activité de copie utilise l’ID d’exécution pour générer le nom de fichier.
Basculez vers l’éditeur de pipeline en sélectionnant l’onglet Pipeline en haut ou en sélectionnant le nom du pipeline dans l’arborescence à gauche.
Dans le volet Activités, développez Général et faites glisser l’activité Procédure stockée du volet Activités vers la surface du concepteur de pipeline. Connectez le résultat vert (succès) de l’activité Copie à l’activité Procédure stockée.
Sélectionnez Activité de procédure stockée dans le concepteur de pipeline et remplacez son nom par
SPtoUpdateWatermarkActivity.Passez à l’onglet Compte SQL et sélectionnez *QLDBEdgeLinkedService sous Service lié.
Basculez vers l’onglet Procédure stockée et effectuez ces étapes :
Sous Nom de la procédure stockée, sélectionnez
[dbo].[usp_write_watermark].Pour spécifier les valeurs des paramètres de procédure stockée, sélectionnez Paramètre d’importation et entrez ces valeurs pour les paramètres :
Nom Type Valeur LastModifiedTime DateTime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}Pour valider les paramètres du pipeline, sélectionnez Valider dans la barre d’outils. Vérifiez qu’il n’y a aucune erreur de validation. Pour fermer la fenêtre Rapport de validation de pipeline, sélectionnez >>.
Publiez des entités (services liés, jeux de données et pipelines) sur le service Azure Data Factory en sélectionnant le bouton Tout publier. Attendez le message de confirmation de réussite de l’opération de publication.
Déclencher un pipeline en fonction d’une planification
Dans la barre d’outils du pipeline, sélectionnez Ajouter un déclencheur, sélectionnez Nouveau/Modifier, puis Nouveau.
Nommez votre déclencheur HourlySync. Sous Type, sélectionnez Planification. Définissez la périodicité sur Toutes les heures.
Sélectionnez OK.
Sélectionnez Publier tout.
Sélectionnez Déclencher maintenant.
Basculez vers l’onglet Surveiller sur la gauche. Vous pouvez voir l’état de l’exécution du pipeline déclenchée par le déclencheur manuel. Sélectionnez Actualiser pour actualiser la liste.
Étapes suivantes
- Dans ce tutoriel, le pipeline Azure Data Factory copie les données d’une table sur un instance SQL Edge vers un emplacement du Stockage Blob Azure toutes les heures. Pour plus d’informations sur l’utilisation de Data Factory dans d’autres scénarios, consultez ces tutoriels.