Gérer l’indexation dans Azure Cosmos DB for MongoDB
S’APPLIQUE À : ![]() MongoDB
MongoDB
Azure Cosmos DB for MongoDB tire parti des fonctionnalités de base de gestion des index d’Azure Cosmos DB. Cet article décrit comment ajouter des index à l’aide d’Azure Cosmos DB for MongoDB. Les index sont des structures de données spécialisées qui permettent l’interrogation de vos données dans un ordre de grandeur approximatif plus rapide.
Indexation pour le serveur MongoDB versions 3.6 et ultérieures
Le serveur Azure Cosmos DB for MongoDB (versions 3.6 et ultérieures) indexe automatiquement le champ _id et la clé de partition (uniquement dans les collections partitionnées). L’API applique automatiquement l’unicité du champ _id par clé de partition.
L’API pour MongoDB se comporte différemment de celle d’Azure Cosmos DB for NoSQL, qui indexe tous les champs par défaut.
Modification de la stratégie d’indexation
Nous vous recommandons de modifier votre stratégie d’indexation dans Explorateur de données au sein du portail Azure. Vous pouvez ajouter des index à champ unique et génériques à partir de l’éditeur de stratégie d’indexation dans Explorateur de données :

Notes
Vous ne pouvez pas créer d’index composés à l’aide de l’éditeur de stratégie d’indexation dans Explorateur de données.
Types d’index
Champ unique
Vous pouvez créer des index sur n’importe quel champ unique. L’ordre de tri d’un index monochamp n’a pas d’importance. La commande suivante crée un index sur le champ name :
db.coll.createIndex({name:1})
Vous pouvez créer le même index à champ unique sur name dans le portail Azure :
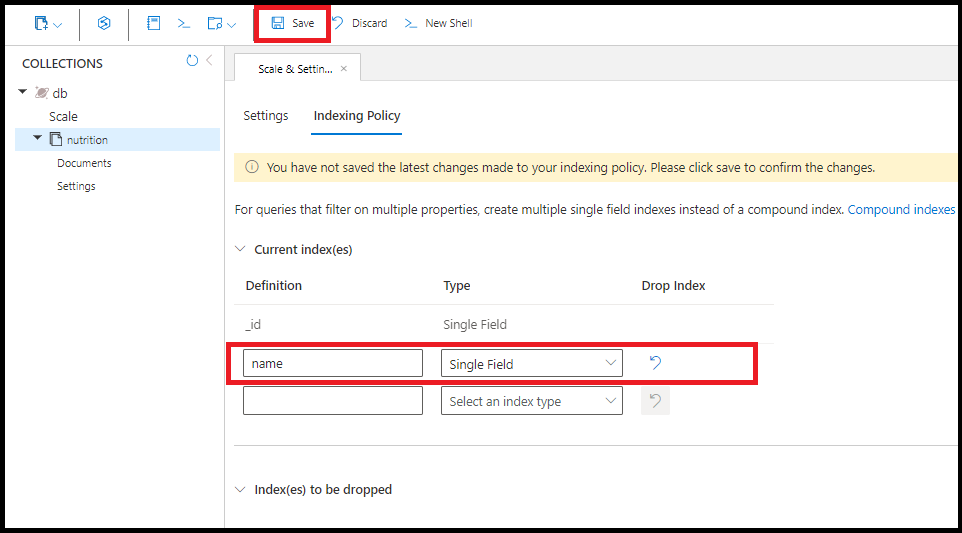
Une requête utilise plusieurs index monochamps, le cas échéant. Vous pouvez créer jusqu’à 500 index monochamp par collection.
Index composés (serveur MongoDB versions 3.6 et ultérieures)
Dans l’API pour MongoDB, les index composés sont requis si votre requête a besoin d’un tri sur plusieurs champs à la fois. Pour les requêtes comportant plusieurs filtres qui n’ont pas besoin de tri, créez plusieurs index monochamp au lieu d’un index composé afin de réduire les coûts d’indexation.
Un index composé ou des index monochamp pour chaque champ de l’index composé entraînent les mêmes performances en matière de filtrage dans les requêtes.
Les index composés sur des champs imbriqués ne sont pas pris en charge par défaut en raison de limitations liées aux tableaux. Si votre champ imbriqué ne contient pas de tableau, l’index fonctionne comme prévu. Si votre champ imbriqué contient un tableau (n’importe où sur le chemin), cette valeur est ignorée dans l’index.
Par exemple, un index composé contenant people.dylan.age fonctionne dans ce cas, car il n’y a pas de tableau sur le chemin :
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Ce même index composé ne fonctionne pas dans ce cas, car il existe un tableau dans le chemin d’accès :
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Vous pouvez activer cette fonctionnalité pour votre compte de base de données en activant la fonctionnalité « EnableUniqueCompoundNestedDocs ».
Notes
Vous ne pouvez pas créer d’index composés sur des tableaux.
La commande suivante crée un index composé sur les champs name et age :
db.coll.createIndex({name:1,age:1})
Vous pouvez utiliser des index composés pour effectuer un tri efficace sur plusieurs champs à la fois, comme illustré dans l’exemple suivant :
db.coll.find().sort({name:1,age:1})
L’index composé précédent peut également être utilisé pour un tri efficace sur une requête avec l’ordre de tri inverse sur tous les champs. Voici un exemple :
db.coll.find().sort({name:-1,age:-1})
Toutefois, la séquence des chemins dans l’index composé doit correspondre exactement à la requête. Voici un exemple de requête nécessitant un index composé supplémentaire :
db.coll.find().sort({age:1,name:1})
Index multiclés
Azure Cosmos DB crée des index multiclés pour indexer le contenu stocké dans des tableaux. Si vous indexez un champ avec une valeur de tableau, Azure Cosmos DB indexe automatiquement chaque élément du tableau.
Index géospatiaux
De nombreux opérateurs géospatiaux tirent parti des index géospatiaux. Actuellement, Azure Cosmos DB for MongoDB prend en charge les index 2dsphere. L’API ne prend pas encore en charge les index 2d.
Voici un exemple de création d’index géospatial sur le champ location :
db.coll.createIndex({ location : "2dsphere" })
Index de texte
Actuellement, Azure Cosmos DB for MongoDB ne prend pas en charge les index de texte. Pour les requêtes de recherche de texte sur les chaînes, vous devez utiliser l’intégration de la recherche Azure AI avec Azure Cosmos DB.
Index génériques
Vous pouvez utiliser des index génériques pour prendre en charge des requêtes sur des champs inconnus. Supposons que vous disposiez d’une collection contenant des données sur des familles.
Voici un exemple de document dans cette collection :
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Voici un autre exemple, cette fois avec un ensemble de propriétés légèrement différent dans children :
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
Dans cette collection, les documents peuvent avoir de nombreuses propriétés possibles. Si vous souhaitez indexer toutes les données dans le tableau children, vous avez deux options : créer des index distincts pour chaque propriété individuelle ou créer un seul index générique pour l’ensemble du tableau children.
Créer un index générique
La commande suivante crée un index générique sur toutes les propriétés dans children :
db.coll.createIndex({"children.$**" : 1})
Contrairement à MongoDB, les index génériques peuvent prendre en charge plusieurs champs dans les prédicats de requête. Il n’y aura pas de différence dans les performances de requête si vous utilisez un seul index générique au lieu de créer un index distinct pour chaque propriété.
Vous pouvez créer les types d’index suivants à l’aide de la syntaxe des caractères génériques :
- Champ unique
- Géospatial
Indexation de toutes les propriétés
Voici comment vous pouvez créer un index de caractères génériques sur tous les champs :
db.coll.createIndex( { "$**" : 1 } )
Vous pouvez également créer des index génériques à l’aide d’Explorateur de données dans le portail Azure :

Notes
Si vous commencez à développer, nous vous recommandons fortement de commencer avec un index générique sur tous les champs. Cela peut simplifier le développement et faciliter l’optimisation des requêtes.
Les documents contenant de nombreux champs peuvent avoir un coût d’unités de requête (RU) élevé pour les écritures et les mises à jour. Par conséquent, si vous avez une charge de travail avec d’importantes opérations d’écriture, vous devez opter pour des chemins d’index individuels au lieu d’utiliser des index génériques.
Notes
La prise en charge d’un index unique sur des collections existantes avec des données est disponible en préversion. Vous pouvez activer cette fonctionnalité pour votre compte de base de données en activant la fonctionnalité « EnableUniqueIndexReIndex ».
Limites
Les index génériques ne prennent pas en charge les types ou propriétés d’index suivants :
- Composé
- TTL
- Unique
Contrairement à MongoDB, dans Azure Cosmos DB for MongoDB, vous ne pouvez pas utiliser des index génériques pour les opérations suivantes :
Création d’un index générique incluant plusieurs champs spécifiques
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Création d’un index générique excluant plusieurs champs spécifiques
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
Vous pouvez également créer plusieurs index génériques.
Propriétés d’index
Les opérations suivantes sont communes pour les comptes utilisant la version 4.0 du protocole Wire et les comptes utilisant des versions antérieures. Vous pouvez obtenir plus d’informations sur les index pris en charge et les propriétés indexées.
Index uniques
Les index uniques sont utiles pour s’assurer que deux documents ou plus ne contiennent pas la même valeur pour les champs indexés.
La commande suivante crée un index unique sur le champ student_id :
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
Pour les collections partitionnées, la création d’un index unique nécessite la clé de partition. En d’autres termes, tous les index uniques d’une collection partitionnée représentent des index composés dont l’un des champs constitue la clé de partition. Le premier champ dans l’ordre doit correspondre à la clé de partition.
Les commandes suivantes créent une collection partitionnée coll (la clé de partition est university) avec un index unique sur les champs student_id et university :
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
Dans l’exemple précédent, l’omission de la clause "university":1 renvoie une erreur avec le message suivant :
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Limites
Les index uniques doivent être créés pendant que la collection est vide.
Les index uniques sur des champs imbriqués ne sont pas pris en charge par défaut en raison des limitations liées aux tableaux. Si votre champ imbriqué ne contient pas de tableau, l’index fonctionnera comme prévu. Si votre champ imbriqué contient un tableau (n’importe où sur le chemin), cette valeur est ignorée dans l’index unique et l’unicité n’est pas conservée pour cette valeur.
Par exemple, un index unique sur people.tom.age fonctionnera dans ce cas, car il n’y a pas de tableau sur le chemin :
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
mais il ne fonctionne pas dans ce cas, car il y a un tableau dans le chemin :
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Vous pouvez activer cette fonctionnalité pour votre compte de base de données en activant la fonctionnalité « EnableUniqueCompoundNestedDocs ».
Index TTL
Pour activer l’expiration des documents dans une collection particulière, vous devez créer un index de durée de vie (TTL, Time-to-Live). Un index TTL est un index sur le champ _ts avec une valeur expireAfterSeconds.
Exemple :
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
La commande précédente supprime tous les documents de la collection db.coll qui n’ont pas été modifiés au cours des 10 dernières secondes.
Notes
Le champ _ts est spécifique à Azure Cosmos DB et n’est pas accessible à partir des clients MongoDB. Il s’agit d’une propriété (système) réservée qui contient le timestamp de la dernière modification du document.
Suivre la progression de l’index
Les versions 3.6 et ultérieures d’Azure Cosmos DB for MongoDB prennent en charge la commande currentOp(), laquelle permet de suivre la progression de l’index sur une instance de base de données. Cette commande retourne un document qui contient des informations sur les opérations en cours sur une instance de base de données. Vous utilisez la commande currentOp pour effectuer le suivi de toutes les opérations en cours dans MongoDB en mode natif. Dans Azure Cosmos DB for MongoDB, cette commande ne prend en charge que le suivi de l’opération d’index.
Voici quelques exemples qui montrent comment utiliser la commande currentOp pour suivre la progression de l’index :
Obtenir la progression de l’index pour une collection :
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Obtenir la progression de l’index pour toutes les collections d’une base de données :
db.currentOp({"command.$db": <databaseName>})Obtenir la progression de l’index pour toutes les bases de données et collections d’un compte Azure Cosmos DB :
db.currentOp({"command.createIndexes": { $exists : true } })
Exemples de sortie de la progression d’index
Les détails de la progression de l’index affichent le pourcentage de progression pour l’opération d’index active. Voici un exemple qui montre le format du document de sortie pour les différentes étapes de la progression de l’index :
Pour une progression en pourcentage de l’opération d’index sur une collection « foo » et une base de données « bar » est de 60 %, le document de sortie suivant est généré. Le champ
Inprog[0].progress.totalaffiche 100 comme pourcentage d’achèvement cible.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Si une opération d’index vient de démarrer sur une collection « foo » et une base de données « bar », le document de sortie peut indiquer une progression de 0 pour cent tant qu’un niveau mesurable n’est pas atteint.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }Une fois l’opération d’index en cours terminée, le document de sortie indique des opérations
inprogvides.{ "inprog" : [], "ok" : 1 }
Mises à jour d’index en arrière-plan
Quelle que soit la valeur spécifiée pour la propriété d’index En arrière-plan, les mises à jour d’index sont toujours effectuées en arrière-plan. Étant donné que les mises à jour d’index consomment des unités de requête (RU) à une priorité inférieure à celle des autres opérations de base de données, les modifications d’index n’entraînent aucun temps d’arrêt pour les écritures, les mises à jour ou les suppressions.
Il n’y a aucun impact sur la disponibilité de lecture lors de l’ajout d’un nouvel index. Les requêtes utilisent uniquement les nouveaux index une fois la transformation d’index terminée. Pendant la transformation d’index, le moteur de requête continue d’utiliser les index existants, ce qui vous permet d’observer des performances de lecture similaires pendant la transformation d’indexation à ce que vous aviez observé avant de lancer la modification de l’indexation. Lors de l’ajout de nouveaux index, il n’y a pas non plus de risque de résultats de requête incomplets ou incohérents.
Lorsque vous supprimez des index et que vous exécutez immédiatement des requêtes, il y a des filtres sur les index supprimés, les résultats peuvent être incohérents et incomplets jusqu’à la fin de la transformation d’index. Si vous supprimez des index, le moteur de requête ne fournit pas de résultats cohérents ou complets lorsque les requêtes appliquent des filtres sur ces index récemment supprimés. La plupart des développeurs ne suppriment pas les index, puis essaient immédiatement de les interroger. Or, en pratique, cette situation est peu probable.
Notes
Vous pouvez suivre la progression de l’index.
Commande ReIndex
La commande reIndex recrée tous les index d’une collection. Dans certains cas rares, l’exécution de la commande reIndex peut résoudre des problèmes de performances des requêtes ou d’autres problèmes d’index dans votre collection. Si vous rencontrez des problèmes d’indexation, il est recommandé de recréer les index à l’aide de la commande reIndex.
Vous pouvez exécuter la commande reIndex à l’aide de la syntaxe suivante :
db.runCommand({ reIndex: <collection> })
Vous pouvez utiliser la syntaxe ci-dessous pour vérifier si l’exécution de la commande reIndex améliore les performances des requêtes dans votre collection :
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Exemple de sortie :
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
Si reIndex permet d’améliorer les performances des requêtes, requiresReIndex a la valeur true. Si reIndex n’améliore pas les performances des requêtes, cette propriété est omise.
Migrer des collections avec des index
Actuellement, vous pouvez uniquement créer des index uniques lorsque la collection ne contient aucun document. Les outils de migration MongoDB populaires tentent de créer des index uniques après l’importation des données. Pour contourner ce problème, vous pouvez créer manuellement les collections et les index uniques correspondants au lieu d’autoriser l’outil de migration à essayer. (Vous pouvez obtenir ce comportement pour mongorestore à l’aide de l’indicateur --noIndexRestore dans la ligne de commande.)
Indexation pour MongoDB version 3.2
Les fonctionnalités d’indexation disponibles et les valeurs par défaut sont différentes pour les comptes Azure Cosmos DB compatibles avec la version 3.2 du protocole filaire MongoDB. Vous pouvez vérifier la version de votre compte et mettre à niveau vers la version 3.6.
Si vous utilisez la version 3.2, cette section décrit les principales différences avec les versions 3.6 et ultérieures.
Suppression des index par défaut (version 3.2)
Contrairement aux versions 3.6 et ultérieures d’Azure Cosmos DB for MongoDB, la version 3.2 indexe chaque propriété par défaut. Vous pouvez utiliser la commande suivante pour supprimer ces index par défaut pour une collection (coll) :
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
Après la suppression des index par défaut, vous pouvez ajouter d’autres index comme vous le feriez dans les versions 3.6 et ultérieures.
Index composés (version 3.2)
Les index composés comportent des références à plusieurs champs d’un document. Si vous souhaitez créer un index composé, effectuez une mise à niveau vers la version 3.6 ou 4.0.
Index génériques (version 3.2)
Si vous souhaitez créer un index générique, effectuez une mise à niveau vers la version 4.0 ou 3.6.
Étapes suivantes
- Indexation dans Azure Cosmos DB
- Faire expirer automatiquement des données avec la durée de vie dans Azure Cosmos DB
- Pour en savoir plus sur la relation entre le partitionnement et l’indexation, consultez l’article Interroger un conteneur Azure Cosmos DB.
- Vous tentez d’effectuer une planification de la capacité pour une migration vers Azure Cosmos DB ? Vous pouvez utiliser les informations sur votre cluster de bases de données existant pour la planification de la capacité.
- Si vous ne connaissez que le nombre de vCore et de serveurs présents dans votre cluster de bases de données existant, lisez Estimation des unités de requête à l’aide de vCore ou de processeurs virtuels.
- Si vous connaissez les taux de requêtes typiques de votre charge de travail de base de données actuelle, lisez la section concernant l’estimation des unités de requête à l’aide du planificateur de capacité Azure Cosmos DB