Microservices
Dans ce tutoriel, vous utilisez Azure Cosmos DB for PostgreSQL comme back-end de stockage pour plusieurs microservices afin d’illustrer l’installation et le fonctionnement de base d’un tel cluster. Découvrez comment :
- Créer un cluster
- Créer des rôles pour vos microservices
- Utiliser l’utilitaire psql pour créer des rôles et des schémas distribués
- Créer des tables pour les exemples de services
- Configurer les services
- Exécuter les services
- Explorer la base de données
S’APPLIQUE À : ![]() Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Prérequis
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Créer un cluster
Connectez-vous au portail Azure et procédez comme suit pour créer un cluster Azure Cosmos DB pour PostgreSQL :
Accédez à Créer un cluster Azure Cosmos DB pour PostgreSQL dans le portail Azure.
Sur le formulaire Créer un cluster Azure Cosmos DB pour PostgreSQL :
Renseignez l’onglet Informations de base.
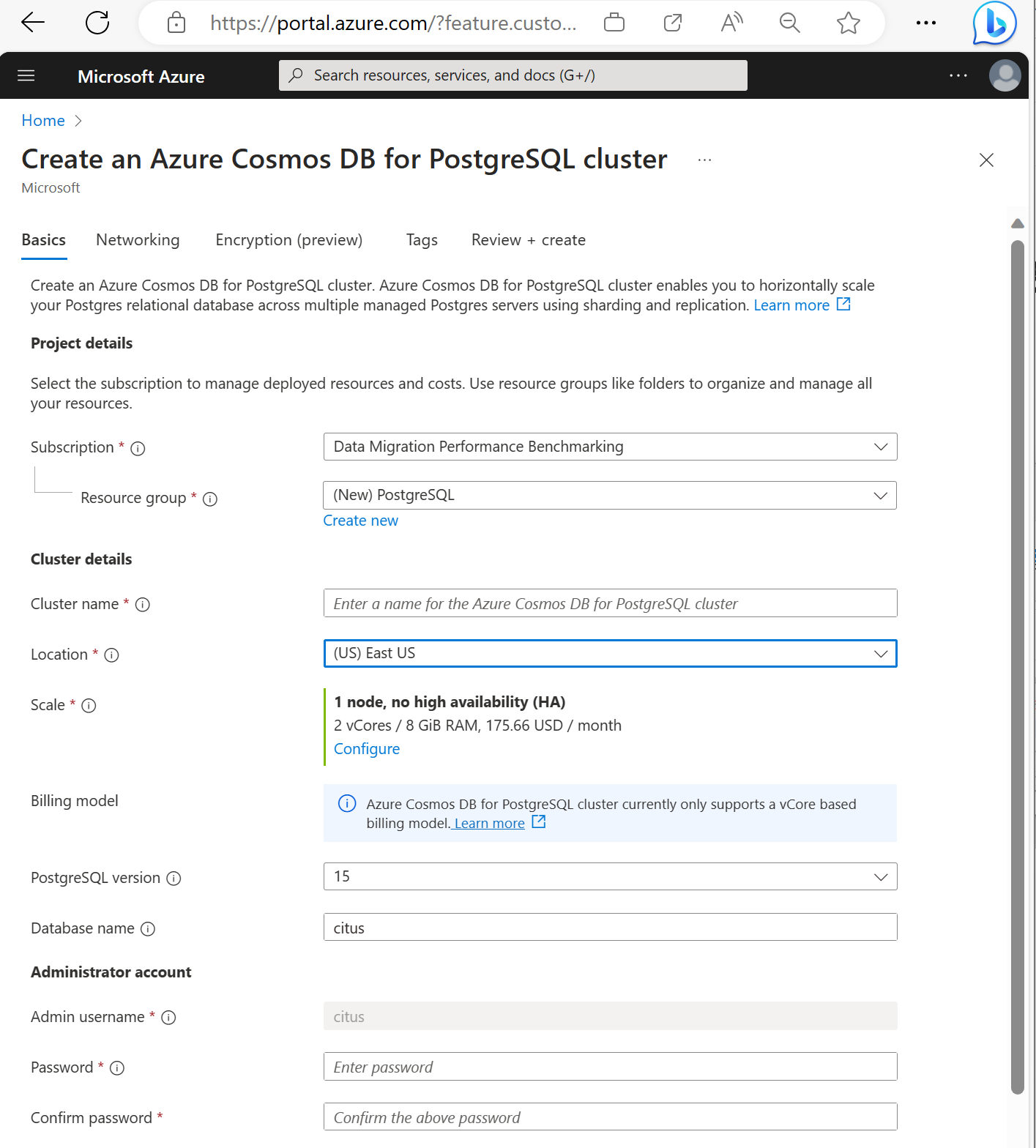
La plupart des options sont explicites, mais n’oubliez pas que :
- Le nom du cluster détermine le nom DNS que vos applications utilisent pour se connecter, au format
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Vous pouvez choisir une version principale de PostgreSQL, telle que la 15. Azure Cosmos DB for PostgreSQL prend toujours en charge la dernière version de Citus pour la principale version de Postgres sélectionnée.
- Le nom d’utilisateur de l’administrateur doit être
citus. - Vous pouvez laisser le nom de la base de données à sa valeur par défaut « citus » ou définir votre unique nom de base de données. Vous ne pouvez pas renommer une base de données après l’approvisionnement du cluster.
- Le nom du cluster détermine le nom DNS que vos applications utilisent pour se connecter, au format
Sélectionnez Suivant : Mise en réseau en bas de l’écran.
Sur l’écran Mise en réseau, sélectionnez Autoriser l’accès public à partir des ressources et services Azure dans Azure sur ce cluster.
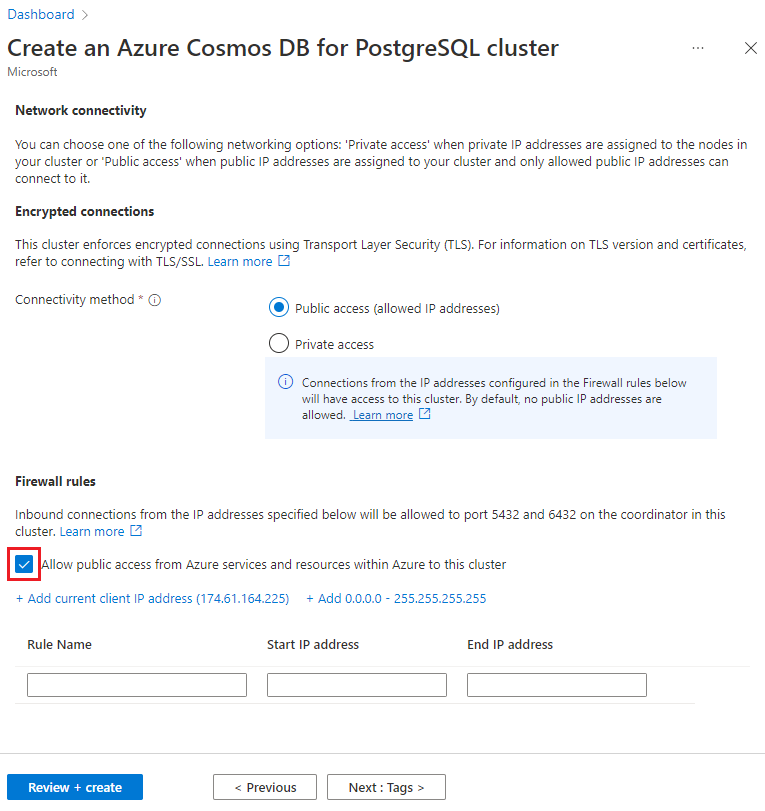
Sélectionnez Vérifier + créer puis, une fois la validation réussie, sélectionnez Créer pour créer le cluster.
Le provisionnement prend quelques minutes. La page redirige vers la supervision du déploiement. Quand l’état passe de Le déploiement est en cours à Votre déploiement est terminé, sélectionnez Accéder à la ressource.
Créer des rôles pour vos microservices
Les schémas distribués sont relocalisables au sein d’un cluster Azure Cosmos DB for PostgreSQL. Le système peut les rééquilibrer en une unité entière sur les nœuds disponibles, ce qui permet de partager efficacement des ressources sans allocation manuelle.
Par conception, les microservices sont propriétaires de leur couche de stockage ; nous n’émettons aucune hypothèse quant au type de tables et de données qu’ils créent et stockent. Nous fournissons un schéma pour chaque service et supposons qu’ils utilisent un RÔLE distinct pour se connecter à la base de données. Lorsqu’un utilisateur se connecte, son nom de rôle est placé au début du search_path. Par conséquent, si le rôle correspond au nom du schéma, aucune modification d’application n’est nécessaire pour définir le search_path correct.
Nous utilisons trois services dans notre exemple :
- utilisateur
- time
- ping
Suivez les étapes décrivant comment créer des rôles utilisateur et créez les rôles suivants pour chaque service :
userservicetimeservicepingservice
Utiliser l’utilitaire psql pour créer des schémas distribués
Une fois connecté à Azure Cosmos DB pour PostgreSQL à l’aide de psql, vous pouvez effectuer quelques tâches de base.
Il existe deux façons de distribuer un schéma dans Azure Cosmos DB for PostgreSQL :
Manuellement en appelant la fonction citus_schema_distribute(schema_name) :
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
Cette méthode vous permet également de convertir des schémas standard existants en schémas distribués.
Remarque
Vous ne pouvez distribuer que des schémas qui ne contiennent pas de tables distribuées ni de tables de référence.
Une autre approche consiste à activer la variable de configuration citus.enable_schema_based_sharding :
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
La variable peut être modifiée pour la session active ou de manière permanente dans les paramètres du nœud coordinateur. Avec le paramètre défini sur ON, tous les schémas créés sont distribués par défaut.
Vous pouvez lister les schémas actuellement distribués en exécutant :
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
Créer des tables pour les exemples de services
Vous devez maintenant vous connecter à Azure Cosmos DB for PostgreSQL pour chaque microservice. Vous pouvez utiliser la commande \c pour permuter l’utilisateur dans une instance psql existante.
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
Configurer les services
Dans ce tutoriel, nous utilisons un ensemble simple de services. Vous pouvez les obtenir en clonant ce dépôt public :
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
Toutefois, avant d’exécuter les services, modifiez les fichiers user/app.py, ping/app.py et time/app.py en fournissant la configuration de connexion pour votre cluster Azure Cosmos DB for PostgreSQL :
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.com',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
Après avoir apporté les modifications, enregistrez tous les fichiers modifiés et passez à l’étape suivante, l’exécution des services.
Exécuter les services
Accédez à chaque répertoire d’application et exécutez-les dans leur propre environnement Python.
cd user
pipenv install
pipenv shell
python app.py
Répétez les commandes pour le service de temps et le service ping, après quoi vous pouvez utiliser l’API.
Créez des utilisateurs :
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
Listez les utilisateurs créés :
curl http://localhost:5000/users
Obtenez l’heure actuelle :
Get current time:
Exécutez le test ping sur example.com :
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
Explorer la base de données
Maintenant que vous avez appelé certaines fonctions d’API, les données ont été stockées et vous pouvez vérifier si citus_schemas ce qui est attendu :
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
Lorsque vous avez créé les schémas, vous n’avez pas indiqué à Azure Cosmos DB for PostgreSQL sur quelles machines créer les schémas. Cela a été fait automatiquement. Vous pouvez voir où réside chaque schéma avec la requête suivante :
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
Pour des raisons de concision de l’exemple de sortie dans cette page, au lieu d’utiliser nodename comme indiqué dans Azure Cosmos DB for PostgreSQL, nous le remplaçons par localhost. Supposez que localhost:9701 est le Worker numéro un et que localhost:9702 est le Worker numéro deux. Les noms de nœuds sur le service managé sont plus longs et contiennent des éléments aléatoires.
Vous pouvez constater que le service de temps a atterri sur le nœud localhost:9701, tandis que le service utilisateur et le service ping partagent de l’espace sur le deuxième Worker localhost:9702. Les exemples d’applications sont simplistes, et les tailles des données ici sont négligeables, mais supposez que vous êtes agacé par l’utilisation inégale de l’espace de stockage entre les nœuds. Il serait plus judicieux que les deux petits services (temps et ping) résident sur une machine, et que le service utilisateur volumineux réside seul.
Vous pouvez facilement rééquilibrer le cluster par taille de disque :
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
Lorsque vous avez terminé, vous pouvez vérifier à quoi ressemble notre nouvelle disposition :
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
Conformément aux attentes, les schémas ont été déplacés et nous avons un cluster plus équilibré. Cette opération a été transparente pour les applications. Vous n’avez même pas besoin de les redémarrer ; elles continuent à traiter les requêtes.
Étapes suivantes
Dans ce tutoriel, vous avez appris à créer des schémas distribués et à exécuter des microservices les utilisant comme stockage. Vous avez également appris à explorer et à gérer une base de données Azure Cosmos DB for PostgreSQL avec partitionnement basé sur un schéma.
- En savoir plus sur les types de nœuds de cluster
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour