Exécutions de pipeline
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2019
Cet article explique la séquence d’activités dans les exécutions de pipeline Azure Pipelines. Il s’agit d’une exécution d’un pipeline. Les pipelines d’intégration continue (CI) et de livraison continue (CD) sont constitués d’exécutions. Pendant une exécution, Azure Pipelines traite le pipeline et les agents traitent un ou plusieurs travaux, étapes et tâches.
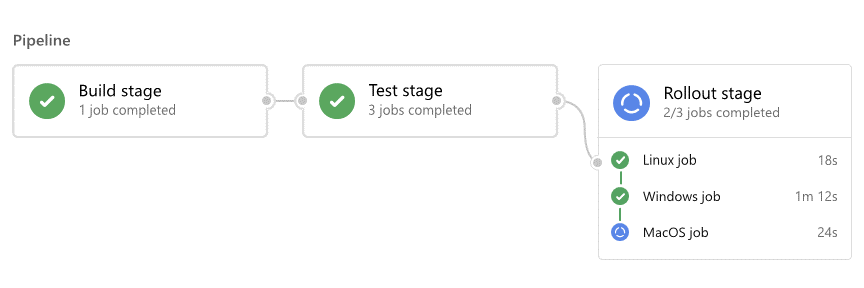
Pour chaque exécution, Azure Pipelines :
- Traite le pipeline.
- Demande à un ou plusieurs agents d’exécuter des travaux.
- Remet les travaux aux agents et collecte les résultats.
Pour chaque travail, un agent :
- Prépare le travail.
- Exécute chaque étape du travail.
- Il crée des rapports contenant les résultats.
Les travaux peuvent réussir, échouer, être annulés ou non terminés. Comprendre ces résultats peut vous aider à résoudre les problèmes.
Les sections suivantes décrivent le processus d’exécution du pipeline en détail.
Traitement du pipeline
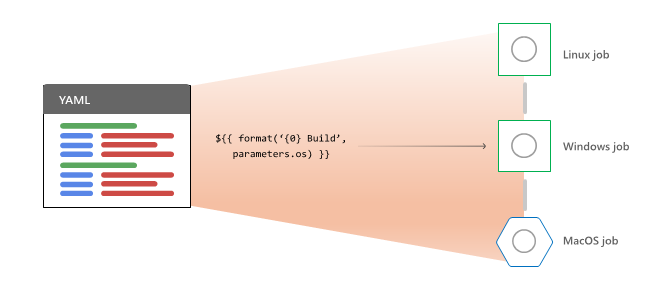
Pour traiter un pipeline pour une exécution, Azure Pipelines commence par :
- Développe des modèles et évalue les expressions de modèle.
- Évalue les dépendances au niveau de l’étape pour choisir la première étape à exécuter.
Pour chaque étape qu’elle sélectionne pour s’exécuter, Azure Pipelines :
- Collecte et valide toutes les ressources de travail pour l’autorisation d’exécution.
- Évalue les dépendances au niveau du travail pour choisir le premier travail à exécuter.
Azure Pipelines effectue les activités suivantes pour chaque travail qu’il sélectionne pour s’exécuter :
- Développe YAML
strategy: matrixoustrategy: parallelplusieurs configurations dans plusieurs travaux d’exécution. - Évalue les conditions pour déterminer si le travail est éligible à l’exécution.
- Demande à un agent pour chaque travail éligible.
À mesure que les travaux d’exécution se terminent, Azure Pipelines vérifie s’il existe de nouveaux travaux éligibles à l’exécution. De même, à mesure que les étapes se terminent, Azure Pipelines vérifie s’il existe d’autres étapes.
Variables
La compréhension de l’ordre de traitement précise pourquoi vous ne pouvez pas utiliser certaines variables dans les paramètres du modèle. La première étape d’extension de modèle fonctionne uniquement sur le texte du fichier YAML. Les variables d’exécution n’existent pas encore pendant cette étape. Après cette étape, les paramètres de modèle sont déjà résolus.
Vous ne pouvez pas également utiliser de variables pour résoudre les noms de connexion de service ou d’environnement, car le pipeline autorise les ressources avant qu’une étape puisse commencer à s’exécuter. Les variables intermédiaires et de niveau travail ne sont pas encore disponibles. Les groupes de variables sont eux-mêmes une ressource soumise à l’autorisation, de sorte que leurs données ne sont pas disponibles lors de la vérification de l’autorisation de ressource.
Vous pouvez utiliser des variables au niveau du pipeline qui sont explicitement incluses dans la définition de ressource de pipeline. Pour plus d’informations, consultez Métadonnées de ressources de pipeline en tant que variables prédéfinies.
Agents
Quand Azure Pipelines doit exécuter un travail, il demande à un agent du pool. Le processus fonctionne différemment pour les pools d’agents hébergés par Microsoft et auto-hébergés .
Remarque
Les travaux serveur n’utilisent pas de pool, car ils s’exécutent sur le serveur Azure Pipelines lui-même.
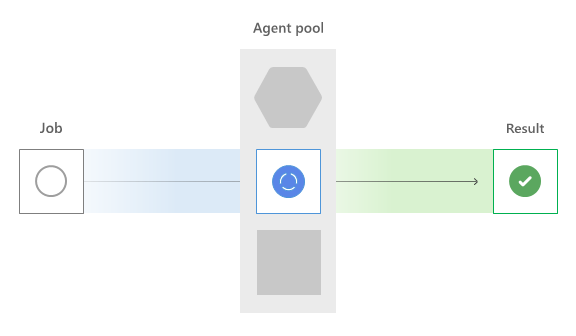
Travaux parallèles
Tout d’abord, Azure Pipelines vérifie les travaux parallèles de votre organisation. Le service ajoute tous les travaux en cours d’exécution sur tous les agents et compare le nombre de travaux parallèles accordés ou achetés.
S’il n’y a pas d’emplacements parallèles disponibles, le travail doit attendre sur un emplacement pour se libérer. Une fois qu’un emplacement parallèle est disponible, le travail est acheminé vers le type d’agent approprié.
Agents hébergés par Microsoft
Conceptuellement, le pool hébergé par Microsoft est un pool global de machines, même s’il s’agit physiquement de nombreux pools différents divisés par type de géographie et de système d’exploitation. En fonction du nom du pool d’éditeurs YAML vmImage ou Classique demandé, Azure Pipelines sélectionne un agent.
Tous les agents du pool Microsoft sont nouveaux, de nouvelles machines virtuelles qui n’ont jamais exécuté de pipelines. Une fois la tâche terminée, la machine virtuelle de l’agent est ignorée.
Agents auto-hébergés
Une fois qu’un emplacement parallèle est disponible, Azure Pipelines examine le pool auto-hébergé pour un agent compatible. Les agents auto-hébergés offrent des fonctionnalités, ce qui indique que certains logiciels sont installés ou configurés. Le pipeline a des exigences, qui sont les fonctionnalités requises pour exécuter le travail.
Si Azure Pipelines ne trouve pas d’agent gratuit dont les fonctionnalités correspondent aux demandes du pipeline, le travail continue d’attendre. S’il n’existe aucun agent dans le pool dont les fonctionnalités correspondent aux demandes, le travail échoue.
Les agents auto-hébergés sont généralement réutilisés d’une exécution à l’autre. Pour les agents auto-hébergés, un travail de pipeline peut avoir des effets secondaires, tels que le réchauffement des caches ou la plupart des validations déjà disponibles dans le référentiel local.
Préparation du travail
Une fois qu’un agent accepte un travail, il effectue le travail de préparation suivant :
- Télécharge toutes les tâches nécessaires pour exécuter le travail et les met en cache pour une utilisation ultérieure.
- Crée un espace de travail sur le disque pour contenir le code source, les artefacts et les sorties utilisés dans l’exécution.
Exécution de l’étape
L’agent exécute les étapes séquentiellement dans l’ordre. Avant de commencer une étape, toutes les étapes précédentes doivent être terminées ou ignorées.
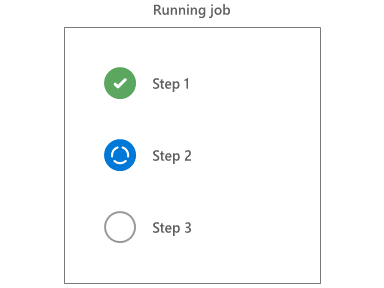
Les étapes sont implémentées par des tâches, qui peuvent être Node.js, PowerShell ou d’autres scripts. Le système de tâche achemine les entrées et les sorties vers les scripts de stockage. Les tâches fournissent également des services courants tels que la modification du chemin du système et la création de variables de pipeline.
Chaque étape s’exécute dans son propre processus, isolant son environnement des étapes précédentes. En raison de ce modèle de processus par étape, les variables d’environnement ne sont pas conservées entre les étapes. Toutefois, les tâches et les scripts peuvent utiliser un mécanisme appelé commandes de journalisation pour communiquer avec l’agent. Lorsqu’une tâche ou un script écrit une commande de journalisation dans une sortie standard, l’agent effectue toute action que la commande demande.
Vous pouvez utiliser une commande de journalisation pour créer de nouvelles variables de pipeline. Les variables de pipeline sont automatiquement converties en variables d’environnement à l’étape suivante. Un script peut définir une nouvelle variable myVar avec la valeur suivante myValue :
echo '##vso[task.setVariable variable=myVar]myValue'
Write-Host "##vso[task.setVariable variable=myVar]myValue"
Création de rapports et regroupements de résultats
Chaque étape peut signaler des avertissements, des erreurs et des échecs. L’étape signale des erreurs et des avertissements sur la page récapitulative du pipeline en marquant les tâches comme ayant réussi avec des problèmes ou signale des échecs en marquant la tâche comme ayant échoué. Une étape échoue si elle signale explicitement l’échec à l’aide d’une ##vso commande ou met fin au script avec un code de sortie différent de zéro.
À mesure que les étapes s’exécutent, l’agent envoie constamment des lignes de sortie à Azure Pipelines, ce qui vous permet de voir un flux en direct de la console. À la fin de chaque étape, la sortie entière de l’étape est chargée en tant que fichier journal. Vous pouvez télécharger le journal une fois le pipeline terminé.
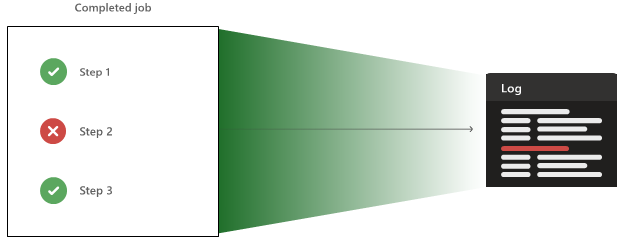
L’agent peut également charger des artefacts et des résultats de test, qui sont également disponibles une fois le pipeline terminé.
État et conditions
L’agent effectue le suivi de la réussite ou de l’échec de chaque étape. À mesure que les étapes réussissent avec des problèmes ou échouent, l’état du travail est mis à jour. Le travail reflète toujours le pire résultat de chacune de ses étapes. En cas d’échec d’une étape, le travail échoue également.
Avant que l’agent exécute une étape, elle vérifie la condition de cette étape pour déterminer si l’étape doit s’exécuter. Par défaut, une étape s’exécute uniquement lorsque l’état du travail est réussi ou réussi avec des problèmes, mais vous pouvez définir d’autres conditions.
De nombreux travaux ont des étapes de nettoyage qui doivent s’exécuter peu importe ce qui se passe, afin qu’ils puissent spécifier une condition de always(). Le nettoyage ou d’autres étapes peuvent également être définis pour s’exécuter uniquement lors de l’annulation.
Une étape de nettoyage réussie ne peut pas enregistrer le travail d’échec. Les travaux ne peuvent jamais revenir au succès après l’échec de l’entrée.
Délais d’expiration et déconnexions
Chaque travail a un délai d’expiration. Si le travail ne se termine pas dans l’heure spécifiée, le serveur annule le travail. Le serveur tente de signaler à l’agent qu’il s’arrête et marque le travail comme annulé. Côté agent, l’annulation signifie annuler toutes les étapes restantes et charger les résultats restants.
Les travaux ont une période de grâce appelée délai d’expiration d’annulation dans lequel effectuer tout travail d’annulation. Vous pouvez également marquer les étapes à exécuter même lors de l’annulation. Après un délai d’expiration du travail plus un délai d’annulation, si l’agent ne signale pas que le travail est arrêté, le serveur marque le travail comme un échec.
Les ordinateurs de l’agent peuvent cesser de répondre au serveur si la machine hôte de l’agent perd de l’alimentation ou est désactivée, ou s’il y a une défaillance réseau. Pour faciliter la détection de ces conditions, l’agent envoie un message de pulsation une fois par minute pour informer le serveur qu’il fonctionne toujours.
Si le serveur ne reçoit pas de pulsation pendant cinq minutes consécutives, il suppose que l’agent ne revient pas. Le travail est marqué comme un échec, ce qui indique à l’utilisateur qu’il doit réessayer le pipeline.
Gérer les exécutions via Azure DevOps CLI
Vous pouvez gérer les exécutions de pipeline à l’aide d’az pipelines s’exécutant dans l’interface CLI Azure DevOps. Pour commencer, consultez Démarrage avec l’interface CLI Azure DevOps. Pour obtenir une référence de commande complète, consultez la référence de commande Azure DevOps CLI.
Les exemples suivants montrent comment utiliser Azure DevOps CLI pour répertorier les exécutions de pipeline dans votre projet, afficher des détails sur une exécution spécifique et gérer des balises pour les exécutions de pipeline.
Prérequis
- Azure CLI avec l’extension Azure DevOps CLI installée comme décrit dans Prise en main d’Azure DevOps CLI. Connectez-vous à Azure à l’aide de
az login. - L’organisation par défaut définie à l’aide
az devops configure --defaults organization=<YourOrganizationURL>de .
Répertorier les exécutions de pipeline
Répertoriez les exécutions de pipeline dans votre projet avec la commande az pipelines runs list .
La commande suivante répertorie les trois premières exécutions de pipeline qui ont un étatterminé et un résultat réussi, et retourne le résultat au format de tableau.
az pipelines runs list --status completed --result succeeded --top 3 --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- ------
125 20200124.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 18:56:10.067588 manual
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
122 20200123.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:48:05.574742 manual
Afficher les détails de l’exécution du pipeline
Affichez les détails d’une exécution de pipeline dans votre projet avec la commande az pipelines runs show .
La commande suivante affiche les détails de l’exécution du pipeline avec l’ID 123, retourne les résultats au format de tableau et ouvre votre navigateur web sur la page de résultats de build Azure Pipelines.
az pipelines runs show --id 122 --open --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- --------
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
Ajouter une étiquette à une exécution de pipeline
Ajoutez une balise à une exécution de pipeline dans votre projet avec la commande az pipelines runs tag add .
La commande suivante ajoute la balise YAML à l’exécution du pipeline avec l’ID 123 et retourne le résultat au format JSON.
az pipelines runs tag add --run-id 123 --tags YAML --output json
[
"YAML"
]
Répertorier les exécutions de pipeline
Répertoriez les balises d’une exécution de pipeline dans votre projet avec la commande az pipelines exécute la liste des balises. La commande suivante répertorie les balises de l’exécution du pipeline avec l’ID 123 et retourne les résultats au format de tableau.
az pipelines runs tag list --run-id 123 --output table
Tags
------
YAML
Supprimer une balise de l’exécution du pipeline
Ajoutez une balise à une exécution de pipeline dans votre projet avec la commande az pipelines runs tag add . La commande suivante supprime la balise YAML de l’exécution du pipeline avec l’ID 123.
az pipelines runs tag delete --run-id 123 --tag YAML
Contenu connexe
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour