Concepts d’ingestion de l’analyseur CSV
Un fichier CSV est un fichier texte délimité par des virgules qui permet d’enregistrer des données dans un format de tableau structuré.
Un graphe orienté acyclique (DAG) d’analyseur CSV permet à un client de charger des données dans l’instance Microsoft Azure Data Manager for Energy en fonction d’un schéma personnalisé, c’est-à-dire un schéma qui ne correspond pas au schéma WKS (Well Known Schema) d’ OSDU®. Les clients doivent créer et inscrire le schéma personnalisé à l’aide du service de schéma avant de charger les données.
Un DAG d’analyseur CSV implémente une approche ELT (Extraire, charger et transformer) pour le chargement des données. Autrement dit, les données sont d’abord extraites du système source dans un format CSV, puis chargées dans l’instance Azure Data Manager for Energy. Elles peuvent ensuite être transformées en schéma WKS OSDU® au moyen d’un service de mappage.
Que fait l’ingestion CSV ?
Un DAG d’analyseur CSV permet aux clients de charger les données CSV dans l’instance Microsoft Azure Data Manager for Energy. Il analyse chaque ligne d’un fichier CSV et crée un enregistrement de métadonnées de stockage. Il exécute schema validation pour garantir que les données CSV sont conformes au schéma personnalisé enregistré. Il exécute automatiquement type coercion sur les colonnes en fonction de la définition du type de données de schéma. Il exécute unique id pour chaque ligne de l’enregistrement CSV en combinant la source, le type d’entité et une chaîne encodée en Base64 formée par concaténation d’une ou plusieurs clés naturelles dans les données. Il exécute unit conversion en convertissant les informations relatives au cadre de référence déclaré en référence persistante appropriée à l’aide du service d’unités. Il exécute CRS conversion pour les colonnes sensibles sur le plan spatial en fonction des informations sur le cadre de référence (FoR) présentes dans le schéma. Il crée des métadonnées relationships, conformément à la déclaration dans le schéma source. Enfin, il rend persistant (persists) l’enregistrement de métadonnées à l’aide du service de stockage.
Composants d’ingestion de l’analyseur CSV
Le workflow du DAG d’analyseur CSV comprend les services suivants :
- Le service de fichiers facilite la gestion des fichiers dans l’instance Azure Data Manager for Energy. Il permet à l’utilisateur de charger, de découvrir et de télécharger des fichiers en toute sécurité à partir de la plateforme de données.
- Le service de schémas facilite la gestion des schémas dans l’instance Azure Data Manager for Energy. Il permet à l’utilisateur de créer, de récupérer et de rechercher des schémas dans la plateforme de données.
- Le service de stockage facilite le stockage des informations de métadonnées pour les entités de domaine ingérées dans la plateforme de données. Il déclenche également des événements de modification des enregistrements de stockage qui permettent aux services en aval d’effectuer des opérations sur les enregistrements de métadonnées ingérés.
- Le service d’unités facilite la gestion et la conversion des unités.
- Le service de workflows facilite la gestion des workflows dans l’instance Azure Data Manager for Energy. Il s’agit d’un service wrapper qui repose sur le moteur d’orchestration Airflow.
Diagramme des composants d’ingestion CSV
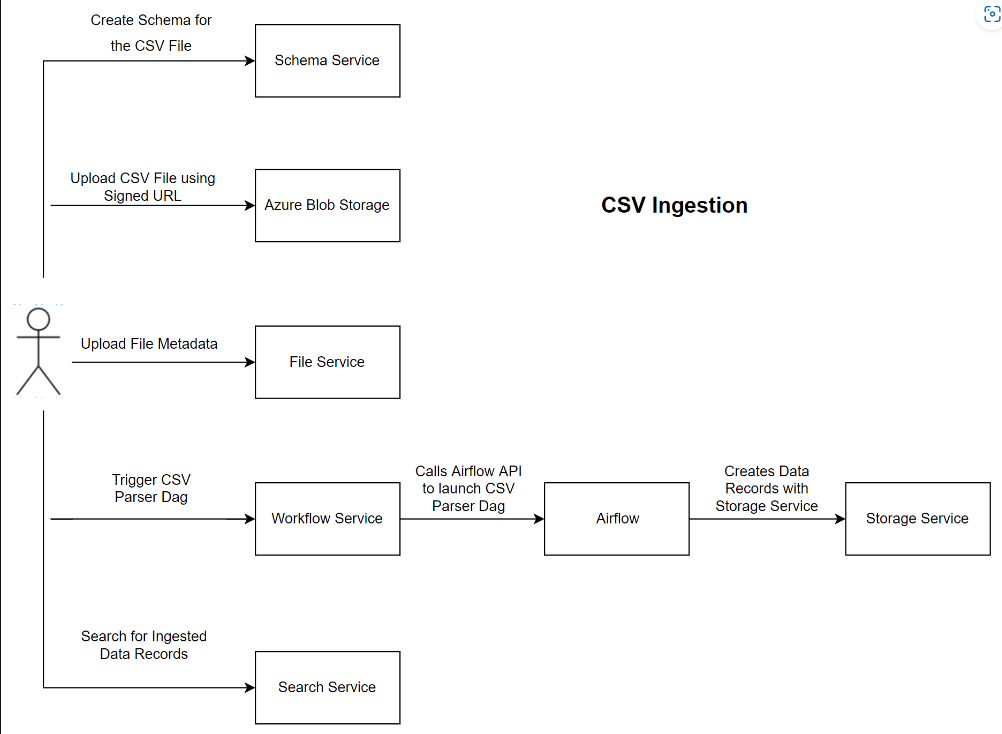
Workflow d’ingestion de l’analyseur CSV
Pour exécuter le workflow du DAG d’analyseur CSV, l’utilisateur doit avoir un jeton d’autorisation valide et disposer d’un accès approprié aux services suivants : recherche, stockage, schémas, service de fichiers, droits, juridique et workflows.
Le diagramme de workflow ci-dessous illustre le workflow du DAG d’analyseur CSV : 
Pour exécuter le workflow du DAG d’analyseur CSV, l’utilisateur doit d’abord créer et inscrire le schéma à l’aide du service de workflow. Une fois le schéma créé, l’utilisateur utilise le service de fichiers pour charger le fichier CSV sur les instances Microsoft Azure Data Manager for Energy, et crée également l’enregistrement de stockage pour le genre générique de fichier. Le service de fichiers fournit ensuite à l’utilisateur un ID de fichier qui est utilisé lors du déclenchement du workflow d’analyseur CSV à l’aide du service de workflows. Le service de workflows fournit un ID d’exécution que l’utilisateur peut utiliser pour suivre l’état de l’exécution du workflow de l’analyseur CSV.
OSDU® est une marque déposée de The Open Group.
Étapes suivantes
Passez au tutoriel de l’analyseur CSV et découvrez comment effectuer une ingestion de l’analyseur CSV