Présentation d’Apache Kafka dans Azure HDInsight
Apache Kafka est une plateforme de diffusion en continu distribuée open source qui permet de générer des pipelines de données et des applications de diffusion en continu en temps réel. Kafka fournit également des fonctionnalités de courtier de messages semblables à une file d’attente, où vous pouvez publier et vous abonner aux flux de données nommés.
Voici les caractéristiques spécifiques de Kafka sur HDInsight :
Il s’agit d’un service managé qui propose un processus de configuration simplifié. En résulte une configuration testée et prise en charge par Microsoft.
Microsoft propose un contrat de niveau de service (SLA) à 99,9 % sur la durée de fonctionnement de Kafka. Pour plus d’informations, consultez le document Informations sur le contrat SLA de HDInsight.
Il utilise Azure Disques managés comme magasin de stockage pour Kafka. Les disques managés peuvent fournir jusqu’à 16 To de stockage par répartiteur Kafka. Pour plus d’informations sur la configuration des disques managés avec Kafka dans HDInsight, consultez Augmenter la scalabilité d’Apache Kafka dans HDInsight.
Pour plus d’informations sur les disques managés, consultez Azure Disques managés.
Kafka a été conçu avec une vision unidimensionnelle du rack. Azure sépare chaque rack en deux dimensions : les domaines de mise à jour et les domaines d’erreur. Microsoft fournit des outils permettant de rééquilibrer les partitions et les réplicas Kafka entre les domaines de mise à jour et les domaines d’erreur.
Pour plus d’informations, consultez Haute disponibilité avec Apache Kafka dans HDInsight.
HDInsight permet de modifier le nombre de nœuds de travail (qui hébergent le répartiteur Kafka) après la création du cluster. La mise à l’échelle vers le haut peut être effectuée depuis le Portail Azure, Azure PowerShell et d’autres interfaces de gestion Azure. Pour Kafka, vous devez rééquilibrer les réplicas de partition après les opérations de mise à l’échelle. Le rééquilibrage des partitions permet à Kafka de tirer parti du nouveau nombre de nœuds de travail.
HDInsight Kafka ne prend pas en charge la mise à l’échelle vers le bas ou la diminution du nombre de répartiteurs au sein d’un cluster. Si une tentative est effectuée pour réduire le nombre de nœuds, une erreur
InvalidKafkaScaleDownRequestErrorCodeest retournée.Pour plus d’informations, consultez Haute disponibilité avec Apache Kafka dans HDInsight.
Les journaux d’activité Azure Monitor peuvent servir à superviser Kafka sur HDInsight. En effet, ils révèlent des informations au niveau de la machine virtuelle, comme les métriques des disques et des cartes réseau, et les métriques JMX de Kafka.
Pour plus d’informations, consultez Analyser les journaux d’activité pour Apache Kafka dans HDInsight.
Architecture Apache Kafka dans HDInsight
Le diagramme suivant illustre une configuration Kafka type qui utilise des groupes de consommateurs, un partitionnement et une réplication afin d’offrir une lecture parallèle des événements avec tolérance de panne :
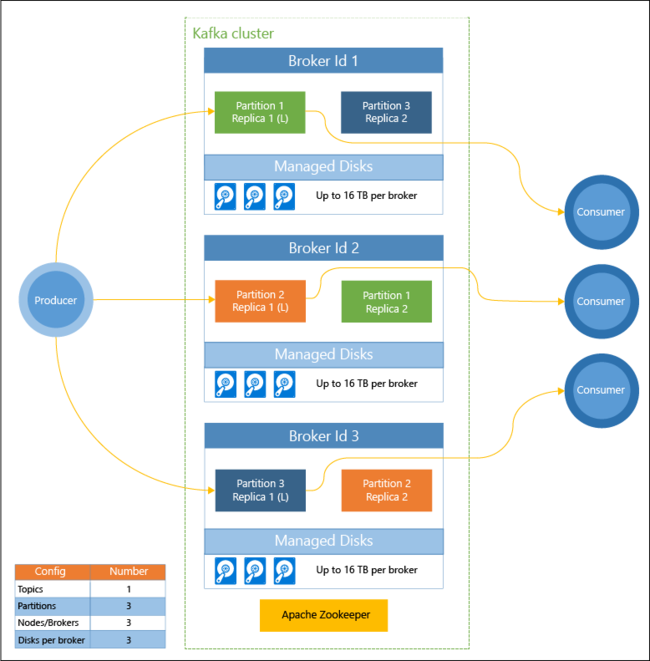
Apache ZooKeeper gère l’état du cluster Kafka. ZooKeeper est conçu pour des transactions simultanées, résilientes et à faible latence.
Kafka stocke les enregistrements (données) dans des rubriques. Les enregistrements sont produits par des producteurs et utilisés par des consommateurs. Les producteurs envoient les enregistrements aux répartiteurs Kafka. Chaque nœud Worker dans votre cluster HDInsight est un répartiteur Kafka.
Les rubriques partitionnent les enregistrements entre les répartiteurs. Au cours de l’utilisation des enregistrements, il est possible d’utiliser jusqu’à un consommateur par partition pour effectuer un traitement parallèle des données.
La réplication est employée pour dupliquer les partitions sur les nœuds, offrant ainsi une protection contre les pannes de nœud (répartiteur). La partition indiquée par un (L) dans le diagramme est la meneuse pour la partition considérée. Le trafic de producteur est acheminé vers le leader de chaque nœud, en utilisant l’état géré par ZooKeeper.
Pourquoi utiliser Apache Kafka dans HDInsight ?
Voici les tâches et les modèles courants réalisables avec Kafka sur HDInsight :
| Utilisez | Description |
|---|---|
| Réplication des données Apache Kafka | Kafka fournit l’utilitaire MirrorMaker, qui réplique les données entre les clusters Kafka. Pour obtenir des informations sur l’utilisation de MirrorMaker, consultez Répliquer des rubriques Apache Kafka avec Apache Kafka dans HDInsight. |
| Modèle de messagerie publication-abonnement | Kafka fournit une API de producteur pour la publication des enregistrements dans une rubrique Kafka. L’API de consommateur est utilisée lors de l’abonnement à un sujet. Pour plus d’informations, consultez Démarrer avec Apache Kafka dans HDInsight. |
| Traitement des flux de données | Kafka est souvent utilisé avec Spark pour le traitement des flux en temps réel. Kafka 2.1.1 et 2.4.1 (HDInsight version 4.0 et 5.0) prend en charge une API de streaming qui vous permet de créer des solutions de streaming sans avoir besoin de Spark. Pour plus d’informations, consultez Démarrer avec Apache Kafka dans HDInsight. |
| Mise à l’échelle horizontale | Kafka partitionne les flux de données entre les nœuds du cluster HDInsight. Les processus consommateur peuvent être associés à des partitions individuelles pour fournir un équilibrage de charge lors de l’utilisation des enregistrements. Pour plus d’informations, consultez Démarrer avec Apache Kafka dans HDInsight. |
| Livraison chronologique | Dans chaque partition, les enregistrements sont stockés dans le flux de données dans leur ordre de réception. En associant un processus consommateur par partition, vous pouvez garantir que les enregistrements sont traités dans l’ordre. Pour plus d’informations, consultez Démarrer avec Apache Kafka dans HDInsight. |
| Messagerie | Dans la mesure où Kafka prend en charge le modèle de messagerie de publication et d’abonnement, il est souvent utilisé comme courtier de messages. |
| Suivi des activités | Étant donné que Kafka assure la journalisation dans l’ordre des enregistrements, il peut être utilisé pour effectuer le suivi et recréer des activités. Par exemple, les actions de l’utilisateur sur un site web ou dans une application. |
| Agrégation | Avec le traitement de flux de données, vous pouvez agréger des informations à partir de différents flux afin de combiner et de centraliser les informations dans des données opérationnelles. |
| Transformation | Avec le traitement de flux de données, vous pouvez combiner et enrichir les données à partir de plusieurs rubriques d’entrée dans une ou plusieurs rubriques de sortie. |
Étapes suivantes
Cliquez sur les liens suivants pour apprendre à utiliser Apache Kafka sur HDInsight :