Qu’est-ce que la contextualisation dans le processeur de données Azure IoT (préversion) ?
Important
Opérations Azure IoT (préversion) – activé parc Azure Arc est actuellement en PRÉVERSION. Vous ne devez pas utiliser ce logiciel en préversion dans des environnements de production.
Pour connaître les conditions juridiques qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou plus généralement non encore en disponibilité générale, consultez l’Avenant aux conditions d’utilisation des préversions de Microsoft Azure.
La contextualisation ajoute des informations aux messages dans un pipeline. La contextualisation peut :
- Améliorer la valeur, la signification et les insights dérivés des données qui transitent par le pipeline.
- Enrichir vos données sources pour les rendre plus compréhensibles et plus explicites.
- Faciliter l’interprétation de vos données et la prise de décision plus précise et efficace.
Par exemple, le capteur de température de votre usine envoie un point de données qui lit 120 °C. Sans contextualisation, il est difficile de dériver une signification de ces données. Toutefois, si vous ajoutez un contexte tel que « La température de la ressource four pendant le quart du matin était de 120 °C », la valeur des données augmente considérablement, car vous pouvez maintenant dériver des insights utiles à partir de celle-ci.
Les données contextualisées fournissent une image plus complète des opérations, ce qui vous aide à prendre des décisions plus éclairées. Les informations contextuelles enrichissent les données pour faciliter leur analyse. Elles vous aident à optimiser les processus, à améliorer l’efficacité et à réduire les temps d’arrêt.
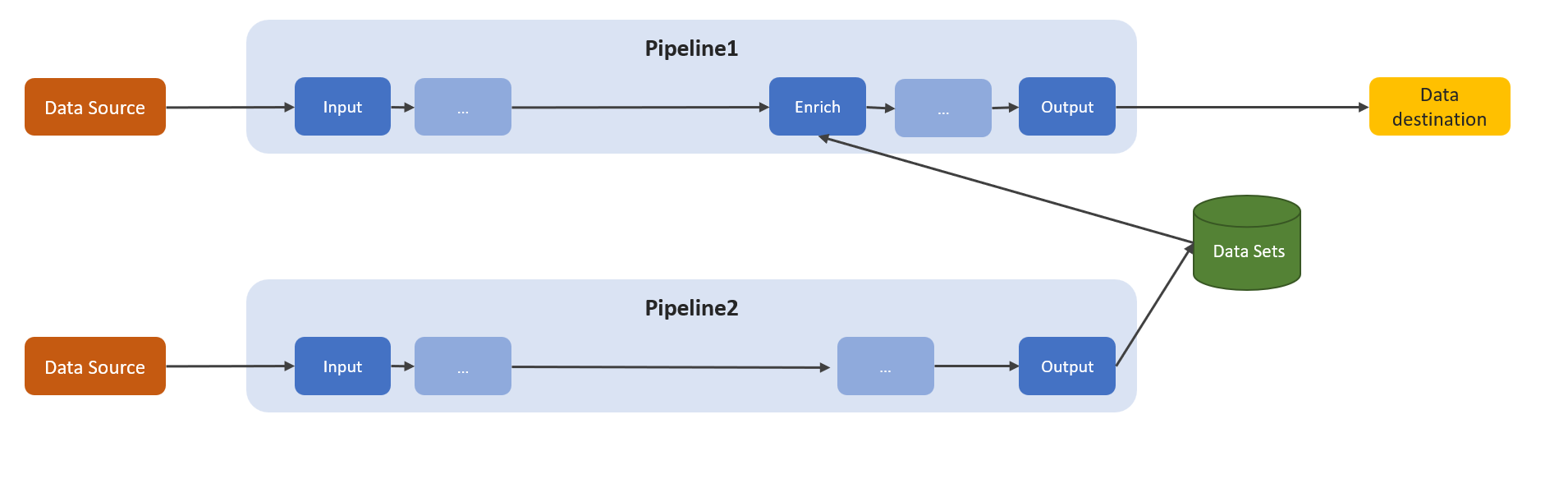
Enrichissement des messages
Un pipeline Azure IoT Data Processor (préversion) contextualise les données en enrichissant les messages qui transitent par le pipeline avec des données de référence précédemment stockées. La contextualisation utilise le magasin de données de référence intégré. Vous pouvez interrompre le processus d’utilisation du magasin de données de référence dans un pipeline en trois étapes :
Créer et configurer un jeu de données. Cette étape crée et configure vos jeux de données dans le magasin de données de référence. La configuration inclut les clés à utiliser pour les jointures et les stratégies d’expiration des données de référence.
Ingérer vos données de référence. Une fois les jeux de données configurés, l’étape suivante consiste à ingérer des données dans le magasin de données de référence. Utilisez l’index de sortie du pipeline de données de référence pour alimenter les données dans vos jeux de données.
Enrichir vos données. Dans un index d’enrichissement, utilisez les données stockées dans le magasin de données de référence pour enrichir les données transitant par le pipeline Data Processor. Ce processus améliore la valeur et la pertinence des données, ce qui vous fournit des insights plus riches et des fonctionnalités d’analyse des données améliorées.
Contenu connexe
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour