Qu’est-ce que le partitionnement dans le processeur de données ?
Important
Opérations Azure IoT (préversion) – activé parc Azure Arc est actuellement en PRÉVERSION. Vous ne devez pas utiliser ce logiciel en préversion dans des environnements de production.
Vous devrez déployer une nouvelle installation d’Azure IoT Operations lorsqu’une version en disponibilité générale est mise à disposition, vous ne pourrez pas mettre à niveau une installation en préversion.
Pour connaître les conditions juridiques qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou plus généralement non encore en disponibilité générale, consultez l’Avenant aux conditions d’utilisation des préversions de Microsoft Azure.
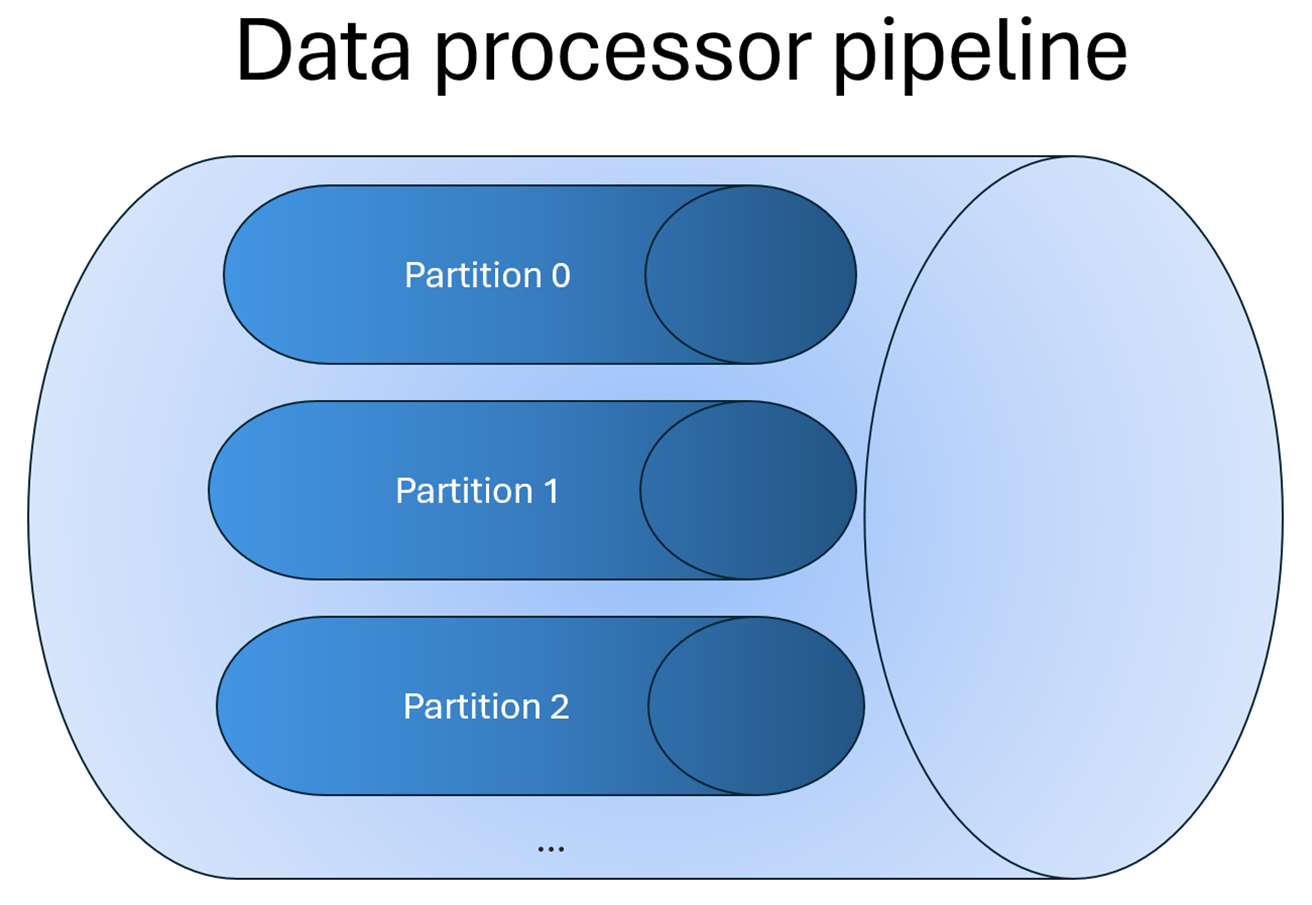
Dans un pipeline de processeur de données, le partitionnement divise les données entrantes en partitions distinctes pour activer le parallélisme des données. Le parallélisme des données améliore le débit et réduit la latence. Le partitionnement affecte également la façon dont les phases de pipeline, telles que la dernière valeur connue et les étapes d’agrégation, traitent les données.
Concepts de partitionnement
Le processeur de données utilise deux concepts de partitionnement :
- Partitions physiques qui correspondent aux flux de données réels au sein du système.
- Partitions logiques qui correspondent aux flux de données conceptuels qui sont traités ensemble.
Un pipeline de processeur de données expose les partitions sous forme de partitions logiques à l’utilisateur. Le système sous-jacent mappe ces partitions logiques sur des partitions physiques.
Pour spécifier une stratégie de partitionnement pour un pipeline, vous fournissez deux informations :
- Nombre de partitions physiques pour votre pipeline.
- Stratégie de partitionnement qui inclut le type de partitionnement et une expression pour calculer la partition logique pour chaque message entrant.
Il est important de choisir le nombre de partitions et les expressions de partition appropriées pour votre scénario. Le processeur de données conserve l’ordre des données au sein de la même partition logique, et les messages de la même partition logique peuvent être combinés dans des phases de pipeline telles que la dernière valeur connue et les étapes d’agrégation. Le nombre de partitions physiques ne peut pas être modifié et détermine les limites de mise à l’échelle du pipeline.
Configuration du partitionnement
Le partitionnement au sein d’un pipeline est configuré à l’étape d’entrée du pipeline. L’étape d’entrée calcule la clé de partitionnement à partir du message entrant. Toutefois, le partitionnement affecte d’autres étapes d’un pipeline.
La configuration du partitionnement comprend :
| Champ | Description | Obligatoire | Par défaut | Exemple |
|---|---|---|---|---|
| Nombre de partitions | Nombre de partitions dans un pipeline de processeur de données. | Oui | N/A | 3 |
| Type | Type de partitionnement logique à utiliser : Partition id ou Partition key. |
Oui | key |
key |
| Expression | L’expression jq à utiliser sur le message entrant pour calculer la Partition id ou la Partition key. |
Oui | N/A | .topic |
Vous fournissez une expression jq qui s’applique à l’intégralité du message qui arrive dans le pipeline du processeur de données pour générer la clé de partition ou l’ID de partition. La sortie de cette requête ne doit pas dépasser 128 caractères.
Type de partitionnement
Il existe deux types de partitionnement que vous pouvez configurer :
Clé de partition
Spécifiez une expression jq qui calcule dynamiquement une chaîne de clé de partition logique pour chaque message :
- Le gestionnaire de partitions affecte automatiquement des clés de partition à des partitions physiques par le gestionnaire de partitions.
- Toutes les données corrélées, telles que les dernières valeurs connues et les agrégats, sont limitées à une partition logique.
- L’ordre des données dans chaque partition logique est garanti.
Ce type de partitionnement est le plus utile lorsque vous avez des dizaines ou plus de regroupements logiques de données.
ID de partition
Spécifiez une expression jq qui calcule dynamiquement un ID de partition physique numérique pour chaque message, par exemple .topic.assetNumber % 8.
- Les messages sont placés dans la partition physique que vous spécifiez.
- Toutes les données corrélées sont limitées à une partition physique.
Ce type de partitionnement convient le mieux lorsque vous avez un petit nombre de regroupements logiques de données ou que vous souhaitez un contrôle précis sur la mise à l’échelle et la distribution de travail. Le nombre d’ID de partition générés doit être un entier et ne doit pas dépasser la valeur de 'partitionCount' – 1.
À propos de l’installation
Lorsque vous choisissez une stratégie de partitionnement pour votre pipeline :
- L’ordre des données est conservé dans une partition logique, car il est reçu des rubriques du répartiteur MQTT.
- Choisissez une stratégie de partitionnement basée sur la nature des données entrantes et des résultats souhaités. Par exemple, la dernière étape de valeur connue et l’étape d’agrégation effectuent des opérations sur chaque partition logique.
- Sélectionnez une clé de partition qui répartit uniformément les données sur toutes les partitions.
- L’augmentation du nombre de partitions peut améliorer les performances, mais consomme également davantage de ressources. Équilibrez ce compromis en fonction de vos exigences et contraintes.