Déclencher des pipelines de Machine Learning
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Dans cet article, vous allez apprendre à planifier un pipeline de manière programmatique pour qu’il s’exécute sur Azure. Vous pouvez créer une planification basée sur la durée calendaire ou sur les modifications du système de fichiers. Les calendriers basés sur la durée peuvent être utilisés pour prendre en charge des tâches de routine, telles que la surveillance de la dérive des données. Les planifications basées sur les modifications peuvent être utilisées pour réagir à des modifications irrégulières ou imprévisibles, telles que de nouvelles données téléchargées ou d’anciennes données modifiées. Après avoir appris à créer des planifications, vous apprendrez comment les récupérer et les désactiver. Enfin, vous apprendrez à utiliser d’autres services Azure, Azure Logic App et Azure Data Factory, pour exécuter des pipelines. Une application logique Azure permet d’obtenir un comportement ou une logique de déclenchement plus complexe. Les pipelines Azure Data Factory vous permettent d’appeler un pipeline Machine Learning dans le cadre d’un pipeline d’orchestration de données plus volumineux.
Prérequis
Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit.
Environnement Python dans lequel le kit de développement logiciel (SDK) Azure Machine Learning pour Python est installé. Pour plus d’informations, consultez Créez et gérez des environnements réutilisables pour la formation et le déploiement avec Azure Machine Learning.
Un espace de travail Machine Learning avec un pipeline publié. Vous pouvez utiliser l’option intégrée Créer et exécuter des pipelines Machine Learning avec le kit de développement logiciel (SDK) Azure Machine Learning.
Déclencher des pipelines avec le Kit de développement logiciel (SDK) Azure Machine Learning pour Python
Pour planifier un pipeline, vous avez besoin d’une référence à votre espace de travail, de l’identificateur de votre pipeline publié et du nom de l’expérience dans laquelle vous souhaitez créer la planification. Vous pouvez obtenir ces valeurs avec le code suivant :
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Créer une planification
Pour exécuter un pipeline de manière récurrente, vous allez créer une planification. Une Scheduleassocie un pipeline, une expérience et un déclencheur. Le déclencheur peut être unScheduleRecurrence qui décrit l’attente entre les tâches ou un chemin d’accès au magasin de données qui spécifie un répertoire dont surveiller les modifications. Dans les deux cas, vous avez besoin de l’identificateur du pipeline et du nom de l’expérience dans laquelle créer la planification.
En haut de votre fichier Python, importez les classes Schedule et ScheduleRecurrence :
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Créer une planification basée sur la durée
Le constructeur ScheduleRecurrence a un argument frequency obligatoire qui doit correspondre à l’une des chaînes suivantes : « Minute », « Heure », « Jour », « Semaine » ou « Mois ». Il exige également un argument interval entier spécifiant le nombre d’unités frequency qui doivent s’écouler entre chaque début de planification. Les arguments facultatifs vous permettent d’être plus précis sur les heures de démarrage, comme détaillé dans les documents du kit de développement logiciel (SDK) ScheduleRecurrence.
Créer un Schedule qui commence une tâche toutes les 15 minutes :
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Créer une planification basée sur les modifications
Les pipelines qui sont déclenchés par les modifications de fichiers peuvent être plus efficaces que les planifications basées sur la durée. Si vous souhaitez effectuer une opération avant la modification d’un fichier ou lors de l’ajout d’un fichier à un répertoire de données, vous pouvez prétraiter ce fichier. Vous pouvez surveiller les modifications apportées à un magasin de donnée ou à des modifications dans un répertoire spécifique au sein du magasin de données. Si vous analysez un répertoire spécifique, les modifications au sein des sous-répertoires de ce répertoire ne déclencheront pas de tâche.
Notes
Les planifications basées sur les modifications prennent uniquement en charge la surveillance du stockage Blob Azure.
Pour créer une Schedule réactive aux fichiers, vous devez définir le paramètre datastore dans l’appel à Schedule.create. Pour surveiller un dossier, définissez l’argument path_on_datastore.
L’argument polling_interval vous permet de spécifier, en minutes, la fréquence de vérification des modifications dans le magasin de données.
Si le pipeline a été construit avec un DataPath PipelineParameter, vous pouvez définir cette variable en fonction du nom du fichier modifié en définissant l’argument data_path_parameter_name.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Arguments facultatifs lors de la création d’une planification
En plus des arguments susmentionnés, vous pouvez définir l’argument status sur "Disabled" pour créer une planification inactive. Enfin, continue_on_step_failure vous permet de transmettre une valeur booléenne qui remplacera le comportement d’échec par défaut du pipeline.
Afficher vos tâches planifiées
Dans votre navigateur web, accédez à Azure Machine Learning. Dans la section Points de terminaison du panneau de navigation, choisissez Points de terminaison de pipeline. Vous obtenez une liste des pipelines publiés dans l’espace de travail.
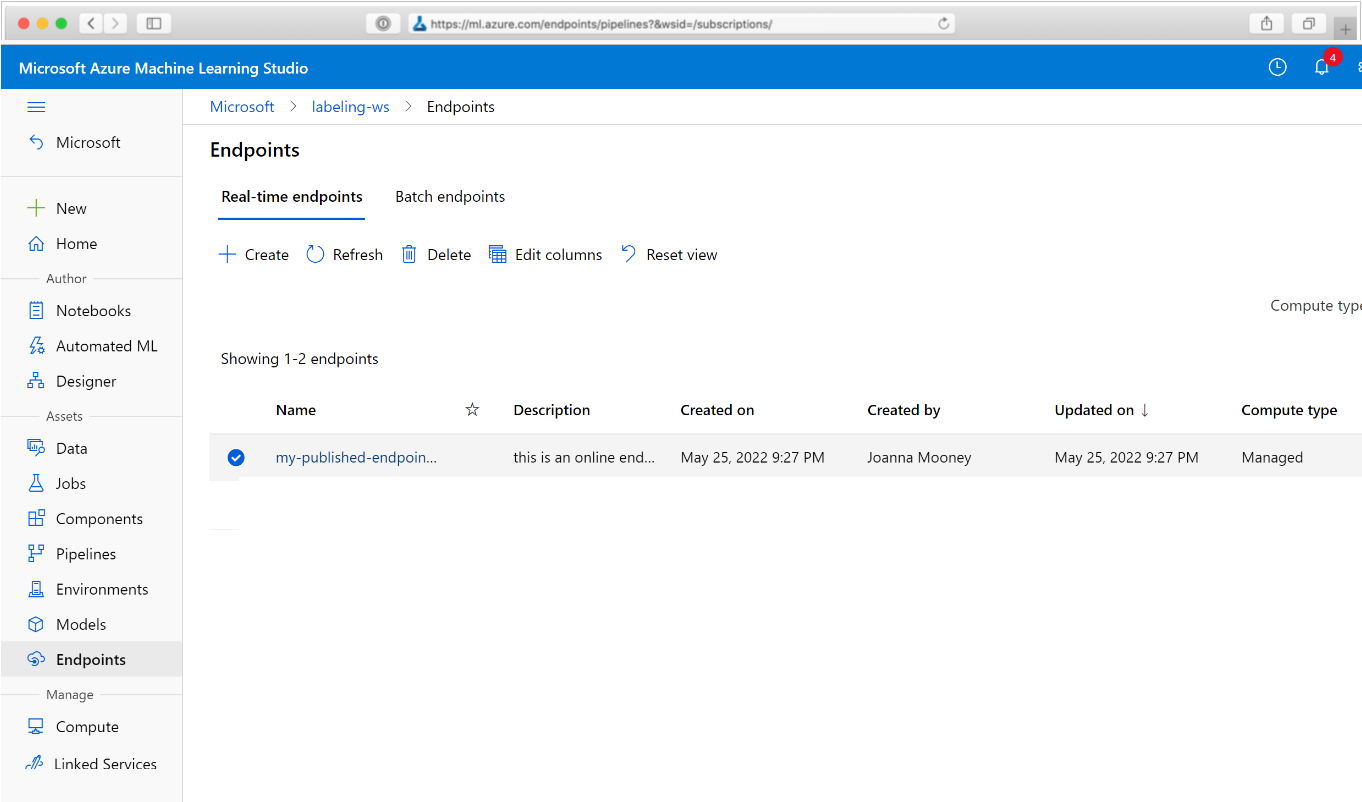
Dans cette page, vous pouvez consulter des informations de résumé sur tous les pipelines dans l’espace de travail : noms, descriptions, état, etc. Découvrez-en plus en cliquant sur votre pipeline. Dans la page affichée, découvrez plus de détails sur votre pipeline et descendez dans la hiérarchie des tâches individuelles.
Désactiver le pipeline
Si vous votre Pipeline est publié mais non planifié, vous pouvez le désactiver avec les éléments suivants :
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Si le pipeline est planifié, vous devez d’abord annuler la planification. Récupérez l’identificateur de la planification sur le portail ou en exécutant :
ss = Schedule.list(ws)
for s in ss:
print(s)
Une fois que vous avez trouvé le schedule_id à désactiver, exécutez :
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Si vous réexécutez ensuite Schedule.list(ws), vous devez obtenir une liste vide.
Utiliser Azure Logic Apps pour des déclencheurs complexes
Vous pouvez créer un comportement ou des règles de déclencheur plus complexes à l’aide d’une application logique Azure.
Pour utiliser une application logique Azure afin de déclencher un pipeline de Machine Learning, vous avez besoin du point de terminaison REST pour un pipeline de Machine Learning publié. Créez et publiez votre pipeline. Ensuite, recherchez le point de terminaison REST de votre PublishedPipeline à l’aide de l’ID de pipeline :
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Créez une Application logique dans Azure
Créez maintenant une instance Azure Logic Apps. Une fois votre application logique approvisionnée, procédez comme suit pour configurer un déclencheur pour votre pipeline :
Créez une identité managée affectée par le système pour permettre à l’application d’accéder à votre espace de travail Azure Machine Learning.
Accédez à la vue Concepteur d’application logique, puis sélectionnez le modèle Application logique vide.
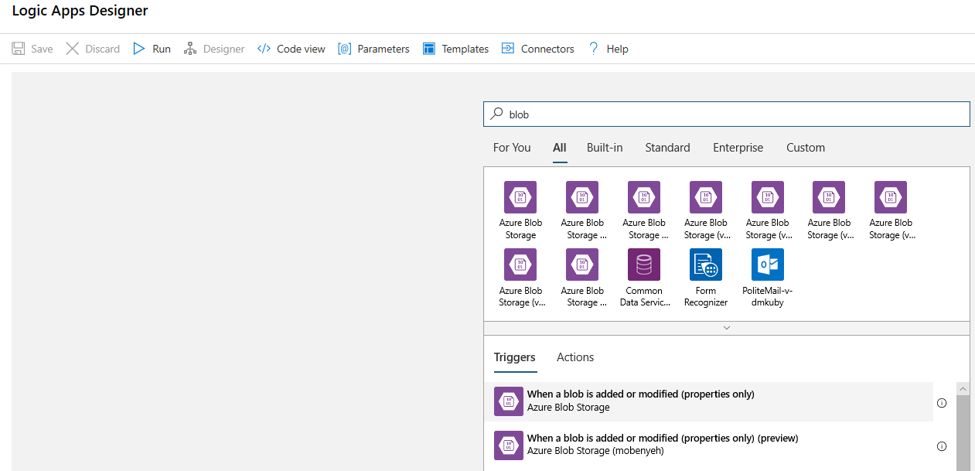
Dans le concepteur, recherchez blob. Sélectionnez le déclencheur Quand un blob est ajouté ou modifié (propriétés uniquement) , puis ajoutez ce déclencheur à votre application logique.
Renseignez les informations de connexion pour le compte de stockage Blob que vous voulez superviser pour les ajouts ou modifications d’objets blob. Sélectionnez le conteneur à superviser.
Choisissez l’Intervalle et la Fréquence pour interroger les mises à jour qui vous conviennent.
Notes
Ce déclencheur supervisera le conteneur sélectionné, mais pas les sous-dossiers.
Ajoutez une action HTTP qui s’exécutera quand un objet blob nouveau ou modifié est détecté. Sélectionnez + Nouvelle étape, puis recherchez et sélectionnez l’action HTTP.
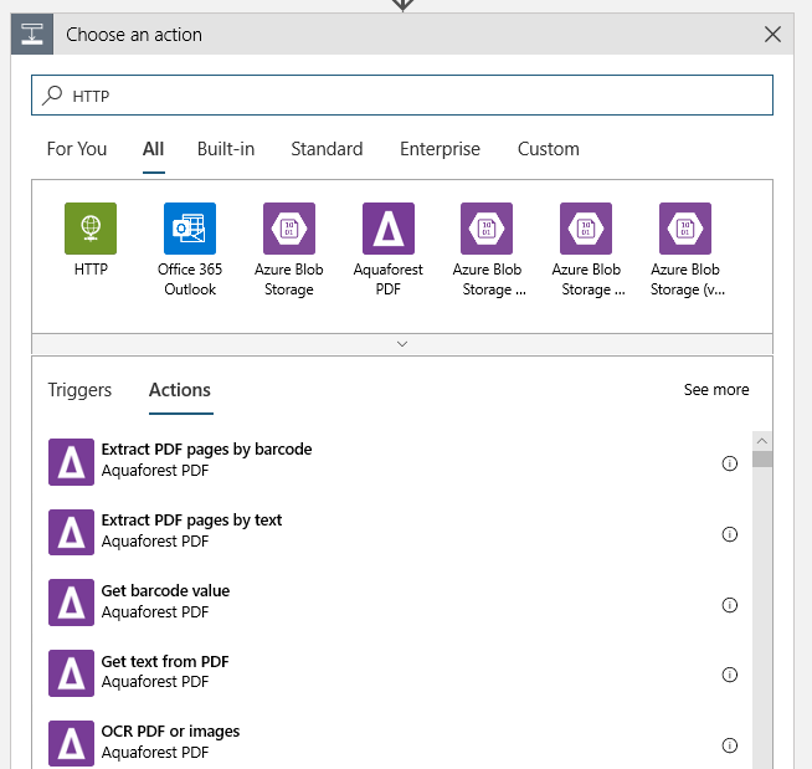
Utilisez les paramètres suivants pour configurer votre action :
| Paramètre | Valeur |
|---|---|
| Action HTTP | POST |
| URI | Le point de terminaison du pipeline publié que vous avez trouvé comme condition préalable |
| Mode d'authentification | Identité managée |
Configurez votre planification pour définir la valeur de tout DataPath PipelineParameters que vous pourriez avoir :
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Utilisez le
DataStoreNameque vous avez ajouté à votre espace de travail en tant que condition préalable.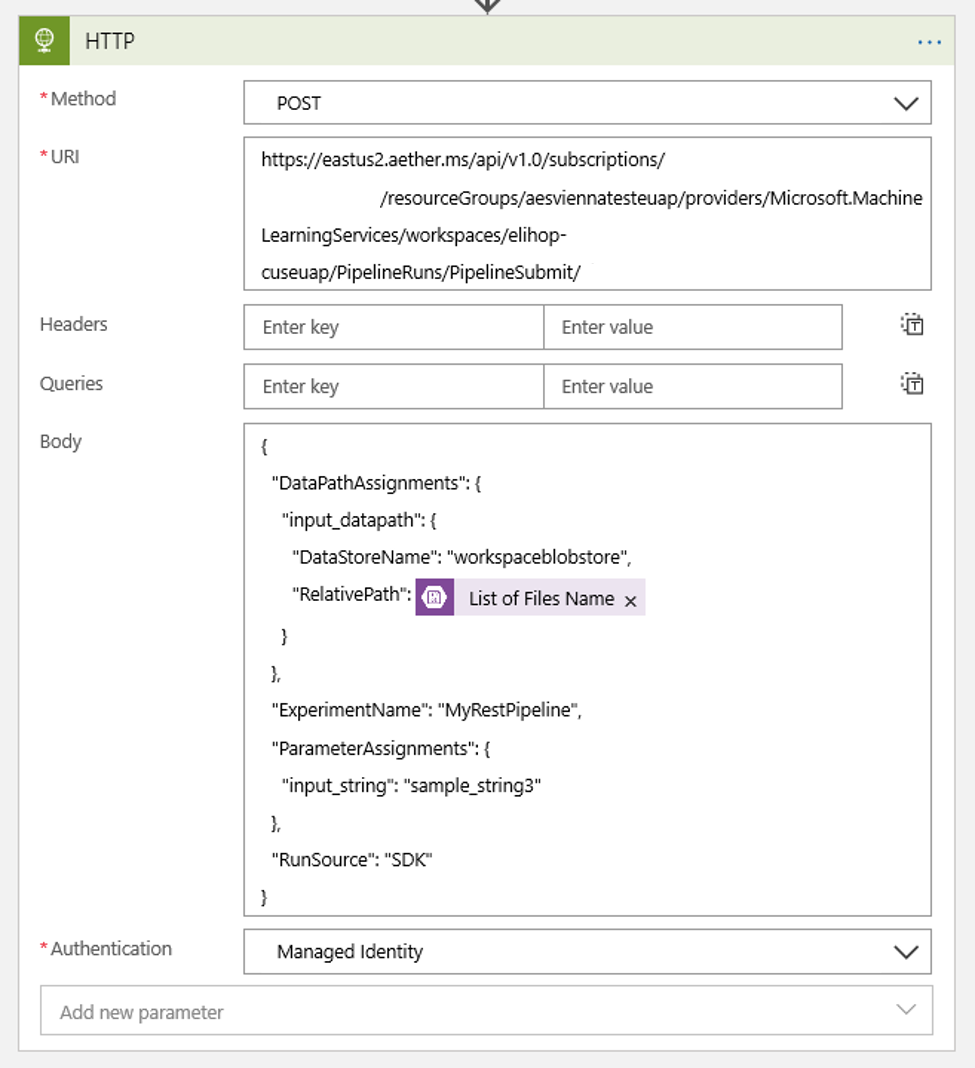
Sélectionnez Enregistrer. Votre planification est maintenant prête.
Important
Si vous utilisez le contrôle d’accès en fonction du rôle Azure (RBAC Azure) pour gérer l’accès à votre pipeline, définissez les autorisations de votre scénario de pipeline (entraînement ou scoring).
Appeler des pipelines Machine Learning à partir de pipelines Azure Data Factory
Dans un pipeline Azure Data Factory, l’activité Execute Pipeline de Machine Learning exécute un pipeline Azure Machine Learning. Vous trouverez cette activité sur la page de création de Data Factory sous la catégorie Machine Learning :
Étapes suivantes
Dans cet article, vous avez utilisé le kit de développement logiciel (SDK) Azure Machine Learning pour Python pour planifier un pipeline de deux façons différentes. Une planification est récurrente en fonction de la durée écoulée. Les autres tâches planifiées si un fichier est modifié sur un Datastore spécifié ou dans un répertoire de ce magasin. Vous avez vu comment utiliser le portail pour examiner le pipeline et les tâches individuelles. Vous avez appris à désactiver une planification afin que le pipeline cesse de s’exécuter. Enfin, vous avez créé une application logique Azure pour déclencher un pipeline.
Pour plus d'informations, consultez les pages suivantes :
- En savoir plus sur les pipelines
- En savoir plus sur l’exploration d’Azure Machine Learning avec Jupyter