Exécuter des modèles Azure Machine Learning à partir de Fabric en utilisant des points de terminaison par lots (préversion)
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Cet article vous montre comment utiliser des déploiements par lots Azure Machine Learning dans Microsoft Fabric. Le workflow utilise des modèles déployés sur des points de terminaison par lots, mais il prend également en charge l’utilisation de déploiements de pipelines par lots à partir de Fabric.
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Prérequis
- Obtenir un abonnement Microsoft Fabric. Ou inscrivez-vous pour obtenir gratuitement un essai de Microsoft Fabric.
- Connectez-vous à Microsoft Fabric.
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
- Un espace de travail Azure Machine Learning. Si vous n’en avez pas, suivez les étapes décrites dans Gérer les espaces de travail pour en créer un.
- Vérifiez que vous disposez des autorisations suivantes dans l’espace de travail :
- Créer et gérer des points de terminaison par lots et des déploiements : utilisez le rôle Propriétaire, Contributeur ou un rôle personnalisé autorisant
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*. - Créer des déploiements ARM dans le groupe de ressources de l’espace de travail : utilisez le rôle Propriétaire, Contributeur ou un rôle personnalisé autorisant
Microsoft.Resources/deployments/writedans le groupe de ressources où l’espace de travail est déployé.
- Créer et gérer des points de terminaison par lots et des déploiements : utilisez le rôle Propriétaire, Contributeur ou un rôle personnalisé autorisant
- Vérifiez que vous disposez des autorisations suivantes dans l’espace de travail :
- Modèle déployé sur un point de terminaison par lots. Si vous n’en avez pas, suivez les étapes décrites dans Déployer des modèles pour le scoring dans des points de terminaison par lots pour en créer un.
- Téléchargez l’exemple de jeu de données heart-unlabeled.csv à utiliser pour le scoring.
Architecture
Azure Machine Learning ne peut pas accéder directement aux données placées dans le stockage OneLake de Fabric. Toutefois, vous pouvez utiliser la fonctionnalité de OneLake pour créer des raccourcis dans un Lakehouse permettant de lire et d’écrire les données stockées dans Azure Data Lake Gen2. Étant donné qu’Azure Machine Learning prend en charge le stockage dans Azure Data Lake Gen2, cette configuration vous permet d’utiliser Fabric et Azure Machine Learning ensemble. L’architecture des données est la suivante :

Configurer l’accès aux données
Pour permettre à Fabric et à Azure Machine Learning de lire et d’écrire les mêmes données sans avoir à les copier, vous pouvez utiliser des raccourcis OneLake et des magasins de données Azure Machine Learning. En utilisant un raccourci OneLake et un magasin de données qui pointent vers le même compte de stockage, vous garantissez que Fabric et Azure Machine Learning lisent et écrivent dans les mêmes données sous-jacentes.
Dans cette section, vous créez ou identifiez un compte de stockage à utiliser pour stocker les informations que le point de terminaison par lots consommera et que les utilisateurs de Fabric verront dans OneLake. Fabric prend uniquement en charge les comptes de stockage avec l’option des noms hiérarchiques activée, comme Azure Data Lake Gen2.
Créer un raccourci OneLake vers le compte de stockage
Ouvrez l’expérience Synapse Data Engineering dans Fabric.
Dans le panneau de gauche, sélectionnez l’espace de travail Fabric à ouvrir.
Ouvrez le lakehouse que vous allez utiliser pour configurer la connexion. Si vous n’avez pas encore de lakehouse, accédez à Data Engineering pour créer un lakehouse. Dans cet exemple, vous utilisez un lakehouse nommé trusted (approuvé).
Dans la barre de navigation de gauche, ouvrez Autres options pour Fichiers, puis sélectionnez Nouveau raccourci pour afficher l’Assistant.

Sélectionnez l’option Azure Data Lake Storage Gen2.

Dans la section Paramètres de connexion, collez l’URL associée au compte de stockage Azure Data Lake Gen2.
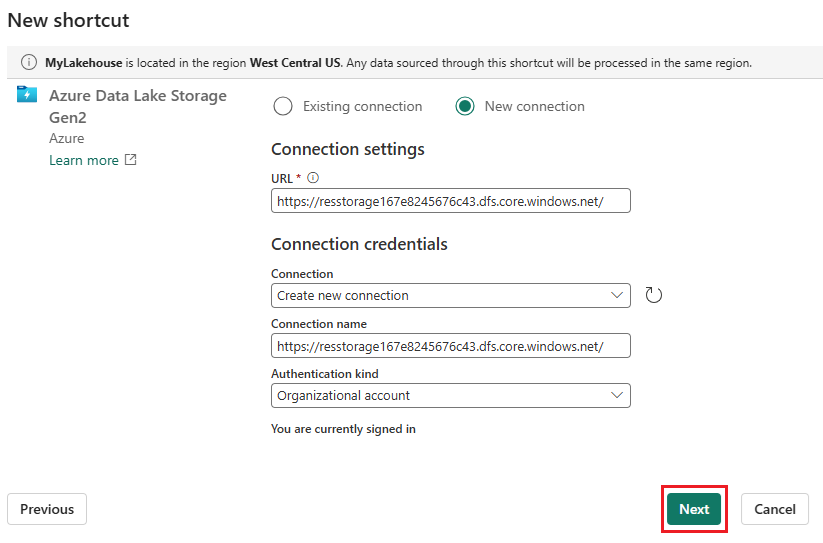
Dans la section Informations d’identification de connexion :
- Dans Connexion, sélectionnez Créer une connexion.
- Dans Nom de la connexion, conservez la valeur renseignée par défaut.
- Dans Type d’authentification, sélectionnez Compte professionnel pour utiliser les informations d’identification de l’utilisateur connecté via OAuth 2.0.
- Sélectionnez Connexion pour vous connecter.
Cliquez sur Suivant.
Configurez le chemin du raccourci, par rapport au compte de stockage, si nécessaire. Utilisez ce paramètre pour configurer le dossier vers lequel le raccourci doit pointer.
Définissez le nom du raccourci. Ce nom sera un chemin au sein du lakehouse. Dans cet exemple, nommez le raccourci datasets (jeux de données).
Enregistrez les modifications.



Créer un magasin de données qui pointe vers le compte de stockage
Ouvrez Azure Machine Learning studio.
Accédez à votre espace de travail Azure Machine Learning.
Accédez à l’onglet Données.
Sélectionnez l’onglet Magasins de données.
Cliquez sur Créer.
Configurez le magasin de données comme ceci :
Dans Nom du magasin de données, entrez trusted_blob (blob_approuvé).
Dans Type de magasin de données, sélectionnez Stockage Blob Azure.
Conseil
Pourquoi devez-vous configurer Stockage Blob Azure et pas Azure Data Lake Gen2 ? Les points de terminaison par lots peuvent uniquement écrire des prédictions dans des comptes Stockage Blob. Toutefois, comme chaque compte de stockage Azure Data Lake Gen2 est également un compte de stockage d’objets blob, les deux types de comptes peuvent être utilisés indifféremment.
Sélectionnez le compte de stockage dans l’Assistant, d’après les valeurs ID d’abonnement, Compte de stockage et Conteneur d’objets blob (système de fichiers).
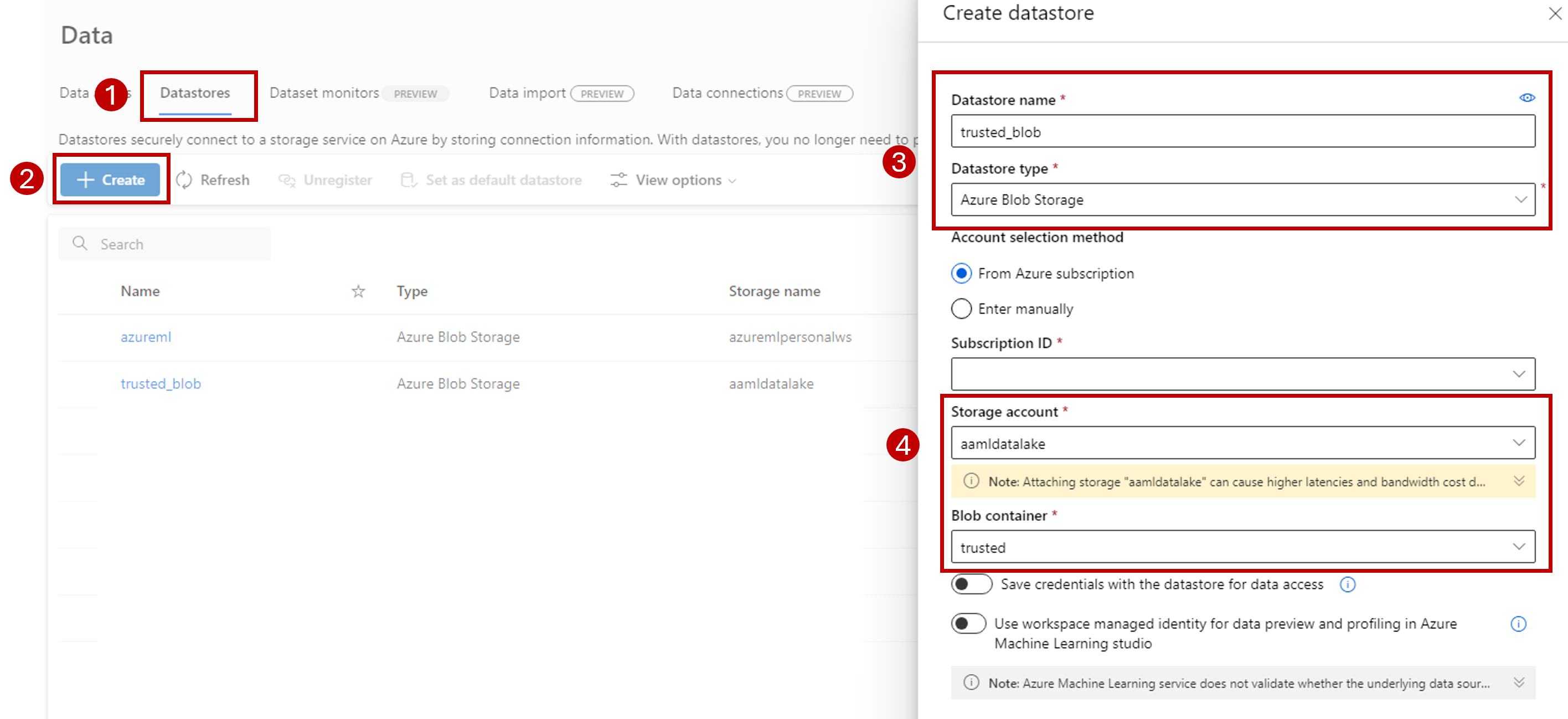
Sélectionnez Créer.
Vérifiez que le calcul sur lequel le point de terminaison par lots s’exécute dispose des autorisations nécessaires pour monter les données dans ce compte de stockage. Bien que l’accès soit toujours accordé par l’identité qui appelle le point de terminaison, le calcul où s’exécute le point de terminaison par lots doit avoir l’autorisation de monter le compte de stockage que vous fournissez. Pour plus d’informations, consultez Accès aux services de stockage.
Charger l’exemple de jeu de données
Chargez quelques exemples de données pour le point de terminaison à utiliser comme entrées :
Accédez à votre espace de travail Fabric.
Sélectionnez le lakehouse où vous avez créé le raccourci.
Accédez au raccourci datasets.
Créez un dossier pour y stocker l’exemple de jeu de données dont vous souhaitez faire le scoring. Nommez le dossier uci-heart-unlabeled.
Utilisez l’option Obtenir des données et sélectionnez Charger des fichiers pour charger l’exemple de jeu de données heart-unlabeled.csv.
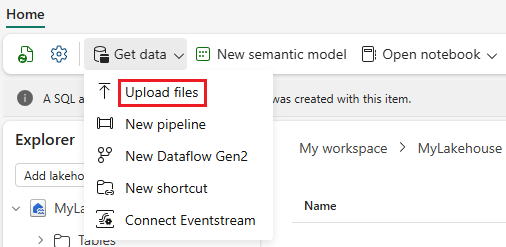
Chargez l’exemple de jeu de données.

L’exemple de fichier est prêt à être utilisé. Notez le chemin de l’emplacement où vous l’avez enregistré.


Créer un pipeline d’inférence par lots avec Fabric
Dans cette section, vous créez un pipeline d’inférence par lots avec Fabric dans votre espace de travail Fabric existant et vous appelez des points de terminaison par lots.
Revenez dans l’expérience Data Engineering (si vous l’aviez quittée) en utilisant l’icône du sélecteur d’expérience dans le coin inférieur gauche de la page d’accueil.
Ouvrez votre espace de travail Fabric.
Dans la section Nouveau de la page d’accueil, sélectionnez Pipeline de données.
Nommez le pipeline et sélectionnez Créer.
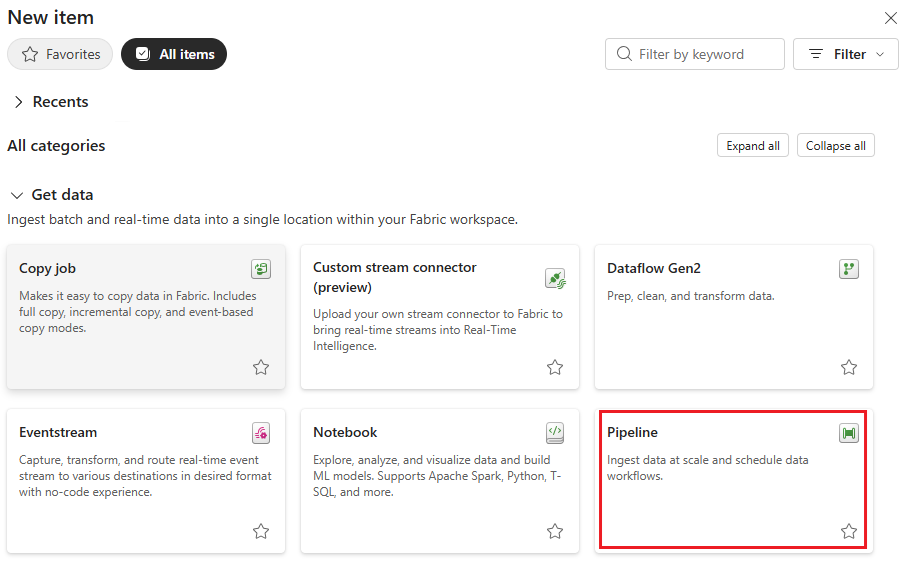
Sélectionnez l’onglet Activités dans la barre d’outils du canevas du concepteur.
Sélectionnez Autres options en bas de l’onglet, puis sélectionnez Azure Machine Learning.
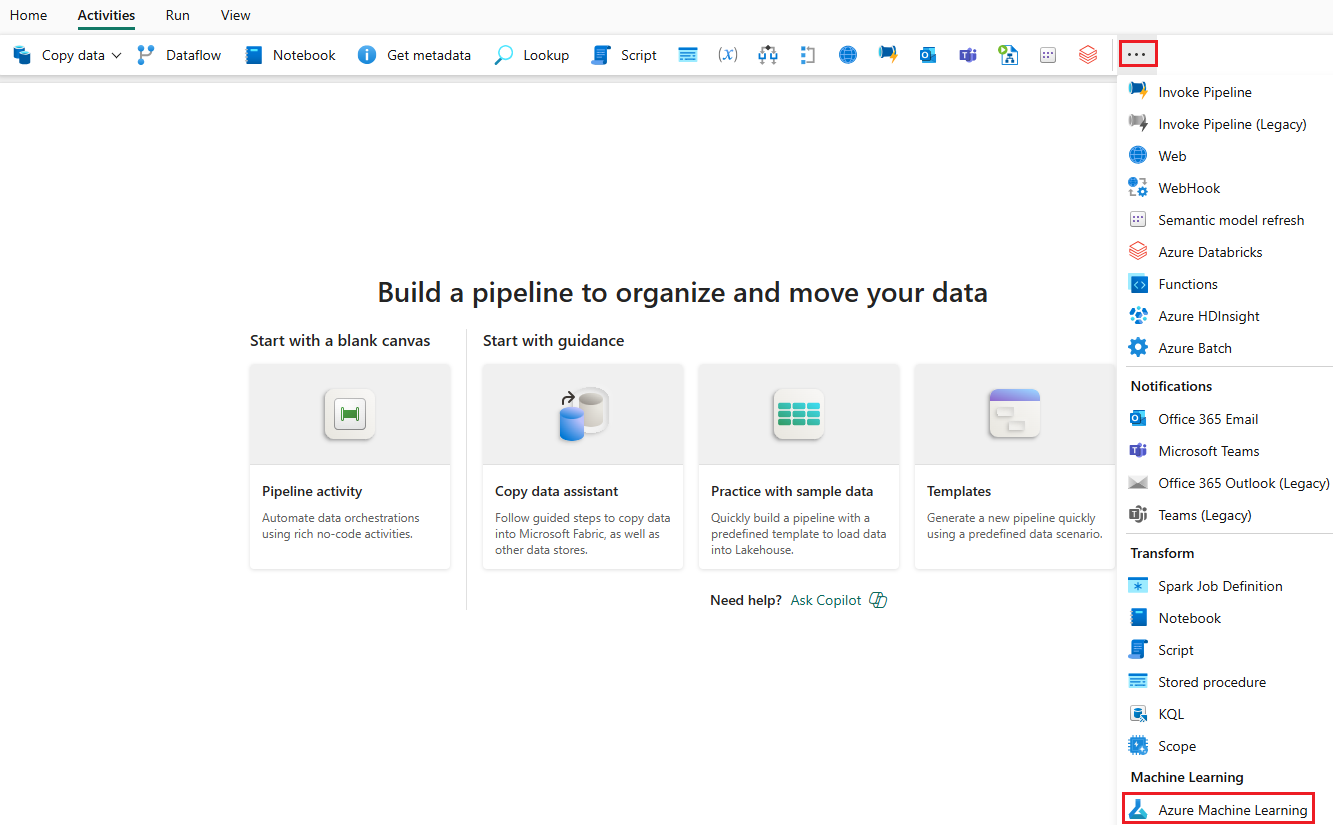
Accédez à l’onglet Paramètres et configurez l’activité comme suit :
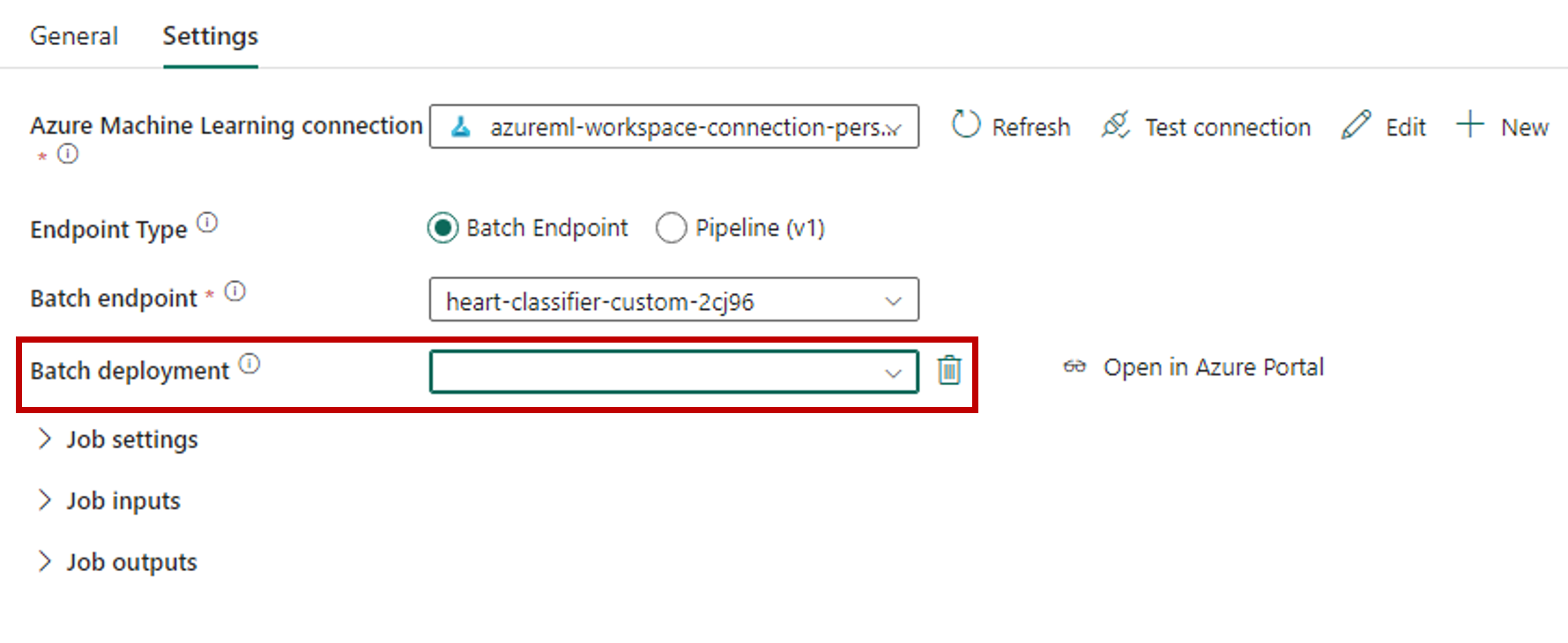
Sélectionnez Nouvelle en regard de Connexion Azure Machine Learning pour créer une connexion à l’espace de travail Azure Machine Learning qui contient votre déploiement.
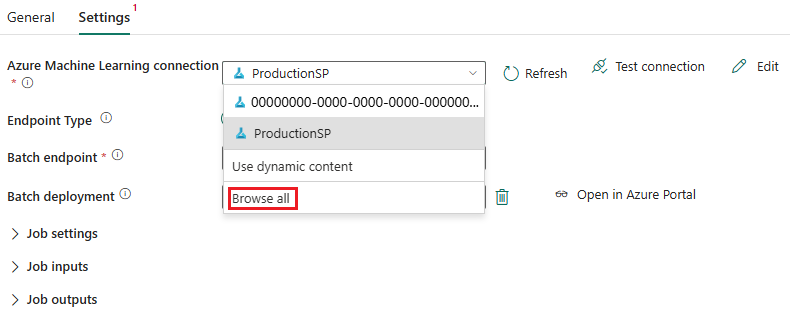
Dans la section Paramètres de connexion de l’Assistant de création, spécifiez les valeurs ID d’abonnement, Nom du groupe de ressources et Nom de l’espace de travail pour indiquer l’emplacement où votre point de terminaison est déployé.
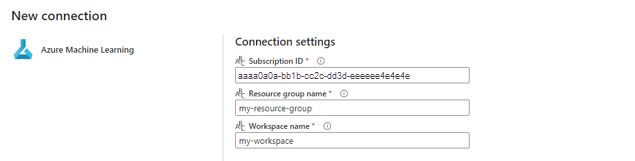
Dans la section Informations d’identification de connexion, sélectionnez Compte professionnel comme Type d’authentification pour votre connexion. Le compte professionnel utilise les informations d’identification de l’utilisateur connecté. Vous pouvez également utiliser un principal de service. Dans les paramètres de production, nous vous recommandons d’utiliser un principal de service. Quel que soit le type d’authentification choisi, vérifiez que l’identité associée à la connexion a les droits d’appeler le point de terminaison par lots que vous avez déployé.

Enregistrez la connexion. Une fois la connexion sélectionnée, Fabric renseigne automatiquement les points de terminaison par lots disponibles dans l’espace de travail sélectionné.
Dans Point de terminaison par lots, sélectionnez le point de terminaison par lots que vous souhaitez appeler. Dans cet exemple, sélectionnez heart-classifier-....
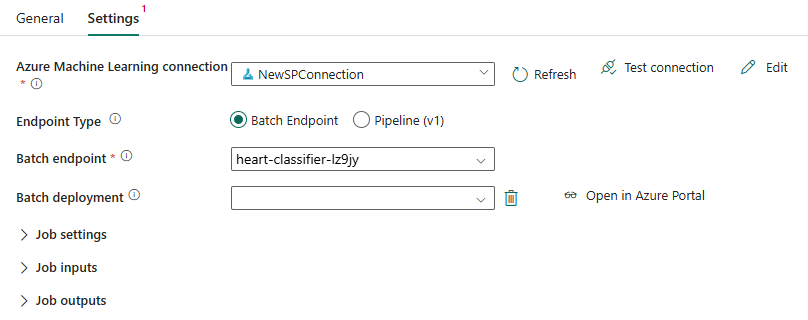
La section Déploiement par lots renseigne automatiquement les déploiements disponibles sous le point de terminaison.
Dans Déploiement par lots, sélectionnez un déploiement spécifique dans la liste, s’il y a lieu. Si vous ne sélectionnez pas de déploiement particulier, Fabric appelle le déploiement par défaut sous le point de terminaison, et le créateur du point de terminaison par lots peut ainsi choisir quel déploiement est appelé. Dans la plupart des scénarios, vous conserverez ce comportement par défaut.







Configurer des entrées et des sorties pour le point de terminaison par lots
Dans cette section, vous configurez des entrées et des sorties à partir du point de terminaison par lots. Les entrées aux points de terminaison par lots fournissent les données et paramètres nécessaires à l’exécution du processus. Le pipeline de traitement par lots Azure Machine Learning dans Fabric prend en charge les déploiements de modèles ainsi que les déploiements de pipelines. Le nombre et le type d’entrées que vous fournissez dépendent du type du déploiement. Dans cet exemple, vous utilisez un déploiement de modèle qui nécessite exactement une entrée et génère une sortie.
Pour plus d’informations sur les entrées et sorties des points de terminaison par lots, consultez Présentation des entrées et des sorties dans les points de terminaison par lots.
Configurer la section des entrées
Configurez la section Entrées du travail comme ceci :
Développez la section Entrées du travail.
Sélectionnez Nouveau pour ajouter une nouvelle entrée à votre point de terminaison.
Nommez l’entrée
input_data. Comme vous utilisez un déploiement de modèle, vous pouvez choisir n’importe quel nom de votre choix. En revanche, pour les déploiements de pipelines, vous devez indiquer le nom exact de l’entrée attendue par votre modèle.Sélectionnez le menu déroulant à côté de l’entrée que vous venez d’ajouter pour ouvrir la propriété de l’entrée (champs Nom et Valeur).
Entrez
JobInputTypedans le champ Nom pour indiquer le type d’entrée que vous créez.Entrez
UriFolderdans le champ Valeur pour indiquer que l’entrée est un chemin de dossier. Les autres valeurs acceptées pour ce champ sont UriFile (chemin de fichier) ou Literal (valeur littérale telle qu’une chaîne ou un entier). Vous devez utiliser le type approprié qui est attendu par votre déploiement.Sélectionnez le signe plus à côté de la propriété afin d’ajouter une autre propriété pour cette entrée.
Entrez
Uridans le champ Nom pour indiquer le chemin des données.Entrez
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled, le chemin où se trouvent les données, dans le champ Valeur. Ici, vous utilisez un chemin vers le compte de stockage qui est lié à OneLake dans Fabric et à Azure Machine Learning. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled est le chemin des fichiers CSV avec les données d’entrée attendues pour le modèle déployé sur le point de terminaison par lots. Vous pouvez aussi utiliser un chemin direct vers le compte de stockage, commehttps://<storage-account>.dfs.azure.com.
Conseil
Si votre entrée est de type Literal, remplacez la propriété
Uripar « Value ».
Si votre point de terminaison nécessite davantage d’entrées, répétez les étapes précédentes pour chacune des entrées à ajouter. Dans cet exemple, les déploiements de modèles nécessitent exactement une entrée.
Configurer la section des sorties
Configurez la section Sorties du travail comme ceci :
Développez la section Sorties du travail.
Sélectionnez Nouvelle pour ajouter une nouvelle sortie à votre point de terminaison.
Nom de la sortie
output_data. Comme vous utilisez un déploiement de modèle, vous pouvez choisir n’importe quel nom de votre choix. En revanche, pour les déploiements de pipelines, vous devez indiquer le nom exact de la sortie générée par votre modèle.Sélectionnez le menu déroulant à côté de la sortie que vous venez d’ajouter pour ouvrir la propriété de la sortie (champs Nom et Valeur).
Entrez
JobOutputTypedans le champ Nom pour indiquer le type de sortie que vous créez.Entrez
UriFiledans le champ Valeur pour indiquer que la sortie est un chemin de fichier. L’autre valeur acceptée pour ce champ est UriFolder (chemin de dossier). Contrairement à la section des entrées de travail, la valeur Literal (valeur littérale telle qu’une chaîne ou un entier) n’est pas acceptée comme sortie.Sélectionnez le signe plus à côté de la propriété afin d’ajouter une autre propriété pour cette sortie.
Entrez
Uridans le champ Nom pour indiquer le chemin des données.Entrez
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')(chemin de l’emplacement de destination de la sortie) dans le champ Valeur. Les points de terminaison par lots Azure Machine Learning prennent uniquement en charge l’utilisation de chemins de magasins de données comme sorties. Du fait que les sorties doivent être uniques pour éviter les conflits, vous avez utilisé une expression dynamique,@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), pour configurer le chemin d’accès.
Si votre point de terminaison retourne davantage de sorties, répétez les étapes précédentes pour chacune des sorties. Dans cet exemple, les déploiements de modèles génèrent exactement une sortie.
(Facultatif) Configurer les paramètres du travail
Vous pouvez également configurer les Paramètres du travail en ajoutant les propriétés suivantes :
Pour les déploiements de modèles :
| Paramètre | Description |
|---|---|
MiniBatchSize |
Taille du lot. |
ComputeInstanceCount |
Nombre d’instances de calcul à obtenir du déploiement. |
Pour les déploiements de pipelines :
| Paramètre | Description |
|---|---|
ContinueOnStepFailure |
Indique si le pipeline doit arrêter le traitement des nœuds après un échec. |
DefaultDatastore |
Indique le magasin de données par défaut à utiliser pour les sorties. |
ForceRun |
Indique si le pipeline doit forcer l’exécution de tous les composants, même si la sortie peut être déduite d’une exécution précédente. |
Quand vous avez terminé la configuration, vous pouvez tester le pipeline.