Comment utiliser des modèles de base Open Source organisés par Azure Machine Learning
Dans cet article, vous découvrez comment affiner, évaluer et déployer des modèles de base dans le catalogue de modèles.
Vous pouvez tester rapidement tout type de modèle pré-entraîné en utilisant le formulaire Exemple d’inférence sur le modèle carte, en fournissant votre propre entrée d’exemple pour tester le résultat. En outre, la carte de chaque modèle comprend une brève description du modèle et des liens vers des échantillons pour l’inférence basée sur le code, l’ajustement et l’évaluation du modèle.
Comment évaluer des modèles de base à l’aide de vos propres données de test
Si vous souhaitez évaluer un modèle de base par rapport à votre jeu de données de test, il vous suffit d’utiliser le formulaire Évaluer d’interface utilisateur ou de tirer parti des exemples basés sur le code, liés à carte du modèle.
Évaluation à l’aide du studio
Vous pouvez appeler le formulaire Évaluer le modèle en cliquant sur le bouton Évaluer sur la carte de modèle de n’importe quel modèle de base.

Chaque modèle peut être évalué pour la tâche d’inférence spécifique pour laquelle il va être utilisé.
Données de test :
- Transmettez les données de test que vous souhaitez utiliser pour évaluer votre modèle. Vous pouvez choisir de charger un fichier local (au format JSONL) ou de sélectionner un jeu de données inscrit existant dans votre espace de travail.
- Une fois le jeu de données sélectionné, vous devez mapper les colonnes à partir de vos données d’entrée, en fonction du schéma nécessaire pour la tâche. Par exemple, mappez les noms de colonnes qui correspondent aux clés « phrase » et « étiquette » pour la classification de texte

Capacité de calcul :
Fournissez le cluster de capacité de calcul Azure Machine Learning que vous souhaitez utiliser pour ajuster le modèle. L’évaluation doit s’exécuter sur le calcul GPU. Assurez-vous de disposer d’un quota de calcul suffisant pour les références SKU de calcul que vous souhaitez utiliser.
Sélectionnez Terminer dans le formulaire Évaluer pour envoyer votre travail d’évaluation. Une fois le travail terminé, vous pouvez afficher les métriques d’évaluation du modèle. En fonction des métriques d’évaluation, vous pouvez décider si vous souhaitez ajuster le modèle à l’aide de vos propres données de formation. En outre, vous pouvez décider si vous souhaitez inscrire le modèle et le déployer sur un point de terminaison.
Évaluation à l’aide d’exemples basés sur le code
Pour permettre aux utilisateurs de se lancer dans l’évaluation de modèles, nous avons publié des exemples (à la fois des notebooks Python et des exemples CLI) dans les Exemples d’évaluation dans le référentiel git azureml-examples. Chaque carte de modèle renvoie également vers des exemples d’évaluation pour les tâches correspondantes
Comment ajuster des modèles de base à l’aide de vos propres données de formation
Pour améliorer les performances du modèle dans votre charge de travail, vous pouvez ajuster un modèle de base à l’aide de vos propres données de formation. Pour ajuster en toute facilité ces modèles de base, il vous suffit d’utiliser les paramètres dans le studio ou bien les échantillons basés sur le code liés à la carte du modèle.
Ajuster à l’aide du studio
Vous pouvez appeler l’Assistant Ajuster le formulaire de paramètres en sélectionnant le bouton Ajuster sur la carte de n’importe quel modèle de base.
Paramètres d’ajustement :

Ajustement du type de tâche
- Chaque modèle préformé du catalogue de modèles peut être ajusté pour un ensemble spécifique de tâches (par exemple : classification de textes, classification de jetons, réponses aux questions). Sélectionnez dans la liste déroulante la tâche que vous souhaitez utiliser.
Données de formation
Transmettez les données de formation que vous souhaitez utiliser pour ajuster votre modèle. Vous pouvez choisir de charger un fichier local (au format JSONL, CSV ou TSV) ou de sélectionner un jeu de données inscrit existant dans votre espace de travail.
Une fois que vous avez sélectionné le jeu de données, vous devez mapper les colonnes à partir de vos données d’entrée, en fonction du schéma nécessaire pour la tâche. Par exemple : mappez les noms de colonnes qui correspondent aux clés « phrase » et « étiquette » pour la classification de texte

- Données de validation : transmettez les données que vous souhaitez utiliser pour valider votre modèle. La sélection de Fractionnement automatique réserve un fractionnement automatique des données de formation pour validation. Vous pouvez également fournir un jeu de données de validation différent.
- Données de test : transmettez les données de test que vous souhaitez utiliser pour évaluer votre modèle ajusté. La sélection de Fractionnement automatique réserve un fractionnement automatique des données de formation pour le test.
- Capacité de calcul : fournissez le cluster de capacité de calcul Azure Machine Learning que vous souhaitez utiliser pour ajuster le modèle. L’ajustement doit s’exécuter sur le calcul GPU. Nous vous recommandons d’utiliser des références SKU de calcul avec des GPU A100/V100 lors de l’ajustement. Assurez-vous de disposer d’un quota de calcul suffisant pour les références SKU de calcul que vous souhaitez utiliser.
- Sélectionnez Terminer sur le formulaire d’ajustement pour envoyer votre travail d’ajustement. Une fois le travail terminé, vous pouvez afficher les métriques d’évaluation du modèle ajusté. Vous pouvez ensuite inscrire la sortie du modèle ajusté par le travail d’ajustement et déployer ce modèle sur un point de terminaison pour l’inférence.
Ajustement à l’aide d’exemples basés sur du code
Actuellement, Azure Machine Learning prend en charge les modèles d’ajustement pour les tâches de langage suivantes :
- Classification de texte
- Classification de jetons
- Réponses aux questions
- Résumé
- Traduction
Pour permettre aux utilisateurs de se lancer rapidement dans l’ajustement, nous avons publié des exemples (à la fois des notebooks Python et des exemples d’interface de ligne de commande) pour chaque tâche dans les exemples d’ajustement du référentiel git azureml-examples. Chaque carte de modèle renvoie également vers des exemples d’ajustement pour les tâches d’ajustement prises en charge.
Déploiement de modèles de base sur des points de terminaison pour l’inférence
Vous pouvez déployer des modèles de base (à la fois préformés à partir du catalogue de modèles et ajustés, ceci, une fois inscrits dans votre espace de travail) sur un terminal à utiliser ensuite en vue d’une inférence. Le déploiement vers des API sans serveur et vers le calcul géré est pris en charge. Vous pouvez déployer ces modèles à l’aide de l’Assistant Déploiement de l’interface utilisateur ou à l’aide des exemples basés sur le code renvoyés par la carte de modèle.
Déploiement utilisant le studio
Vous pouvez appeler le formulaire de déploiement de l'interface utilisateur en sélectionnant le bouton Déployer sur la fiche modèle pour n'importe quel modèle de base, puis en sélectionnant API sans serveur avec Azure AI Content Safety ou Managed Compute sans Azure AI Content Safety

Paramètres de déploiement
Étant donné que le script de scoring et l’environnement sont automatiquement inclus dans le modèle de base, il vous suffit de spécifier la référence SKU de machine virtuelle à utiliser, le nombre d’instances et le nom du point de terminaison à utiliser pour le déploiement.

Quota partagé
Si vous déployez un modèle Llama-2, Phi, Nemotron, Mistral, Dolly ou Deci-DeciLM à partir du catalogue de modèles, mais que vous n’avez pas suffisamment de quota disponible pour le déploiement, Azure Machine Learning vous permet d’utiliser le quota à partir d’un pool de quotas partagés pendant une durée limitée. Pour plus d’informations sur le quota partagé, veuillez consulter Quota partagé sur Azure Machine Apprentissage.

Déploiement à l’aide d’exemples basés sur du code
Pour permettre aux utilisateurs de se lancer rapidement dans le déploiement et l’inférence, nous avons publié des exemples dans les exemples d’inférence du référentiel git azureml-examples. Les exemples publiés incluent des notebooks Python et des exemples d’interface de ligne de commande. Chaque carte de modèle renvoie également vers des exemples d’inférence pour l’inférence en temps réel et l’inférence par lots.
Modèles d’importation de base
Si vous souhaitez utiliser un modèle open source qui n’est pas inclus dans le catalogue de modèles, vous pouvez l’importer depuis Hugging Face dans votre espace de travail Azure Machine Learning. Hugging Face est une bibliothèque open source pour le traitement du langage naturel (NLP, Natural Language Processing) qui fournit des modèles préentraînés pour les tâches NLP populaires. L’importation de modèles prend actuellement en charge l’importation de modèles pour les tâches suivantes, tant que le modèle répond aux exigences répertoriées dans le notebook d’importation du modèle :
- fill-mask
- token-classification
- question-answering
- totalisation
- text-generation
- text-classification
- translation
- image-classification
- text-to-image
Notes
Les modèles de Hugging Face sont soumis aux termes du contrat de licence tiers disponibles sur sa page de détails. Il vous incombe de respecter les termes du contrat de licence du modèle.
Vous pouvez sélectionner le bouton Importer en haut à droite du catalogue de modèles pour utiliser le notebook d’importation de modèle.

Le notebook d’importation de modèle est également inclus dans le référentiel git azureml-examples ici.
Pour importer le modèle, vous devez transférer le MODEL_ID du modèle que vous souhaitez importer depuis Hugging Face. Parcourez les modèles dans le hub de Hugging Face et identifiez le modèle à importer. Vérifiez que le type de tâche du modèle fait partie des types de tâches pris en charge. Copiez l’ID du modèle, que vous pouvez trouver dans l’URI (Uniform Resource Identifier) de la page ou copier à l’aide de l’icône de copie en regard du nom du modèle. Attribuez-le à la variable « MODEL_ID » dans le notebook d’importation du modèle. Par exemple :
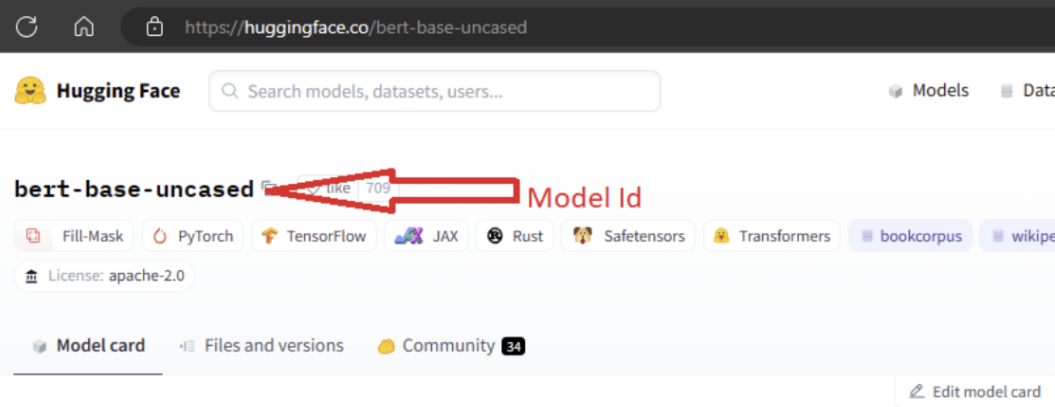
Vous devez fournir la capacité de calcul pour que l’importation de modèle s’exécute. En exécutant l’importation de modèle pour le modèle spécifié, celui-ci est importé depuis Hugging Face et inscrit dans votre espace de travail Azure Machine Learning. Vous pouvez ensuite ajuster ce modèle ou le déployer sur un point de terminaison pour l’inférence.
En savoir plus
- Explorez le catalogue de modèles dans Azure Machine Learning studio. Vous avez besoin d’un espace de travail Azure Machine Learning pour explorer le catalogue.
- Explorer les collections et le catalogue de modèles