Suivre des modèles ML avec MLflow et Azure Machine Learning
S’APPLIQUE À : SDK Python azureml v1
SDK Python azureml v1
Cet article explique comment activer MLflow Tracking pour connecter Azure Machine Learning en tant que back-end de vos expériences MLflow.
MLFlow est une bibliothèque open source permettant de gérer le cycle de vie de vos expériences Machine Learning. MLFlow Tracking est un composant de MLflow qui journalise et suit vos artefacts de modèle et métriques d’exécution d’apprentissage, quel que soit l’environnement de votre expérience, localement sur votre ordinateur, sur une cible de calcul distante, sur une machine virtuelle ou sur un cluster Azure Databricks.
Pour toutes les fonctionnalités de MLflow et d’Azure Machine Learning prises en charge, dont la prise en charge de MLflow Project (préversion) et le déploiement de modèle, consultez MLflow et Azure Machine Learning.
Conseil
Si vous souhaitez suivre les expériences exécutées sur Azure Databricks ou Azure Synapse Analytics, consultez les articles dédiés Assurer le suivi des expériences de Machine Learning Azure Databricks avec MLflow et Azure Machine Learning et Assurer le suivi des expériences de Machine Learning Azure Synapse Analytics avec MLflow et Azure Machine Learning.
Notes
Les informations contenues dans ce document sont principalement destinées aux scientifiques des données et aux développeurs qui veulent superviser le processus d’entraînement du modèle. Si vous êtes administrateur et que vous vous intéressez à la surveillance de l’utilisation des ressources et des événements d’Azure Machine Learning, comme les quotas, les travaux d’apprentissage accomplis ou les déploiements de modèles effectués, consultez Supervision d’Azure Machine Learning.
Prérequis
Installez le package
mlflow.- Vous pouvez utiliser MLflow Skinny, un package MLflow léger sans dépendances de stockage SQL, de serveur, d’interface utilisateur ou de science des données. Ce client est recommandé pour les utilisateurs qui ont principalement besoin des fonctionnalités de suivi et de journalisation et qui ne souhaitent pas importer la suite complète des fonctionnalités MLflow qui comprend des déploiements.
Installez le package
azureml-mlflow.Installez et configurez l’interface CLI d’Azure Machine Learning (v1) en veillant à installer l’extension ml.
Important
Certaines des commandes Azure CLI de cet article utilisent l’extension
azure-cli-ml, ou v1, pour Azure Machine Learning. La prise en charge de l’extension v1 se termine le 30 septembre 2025. Vous pourrez installer et utiliser l’extension v1 jusqu’à cette date.Nous vous recommandons de passer à l’extension
ml, ou v2, avant le 30 septembre 2025. Pour plus d’informations sur l’extension v2, consultez Extension Azure ML CLI et le SDK Python v2.Installez et configurez le kit de développement logiciel (SDK) Azure Machine Learning pour Python.
Suivre les exécutions à partir de votre ordinateur local ou d’un environnement de calcul distant
Le suivi à l’aide de MLflow avec Azure Machine Learning vous permet de stocker les métriques consignées et les exécutions d’artefacts effectuées sur votre ordinateur local au sein de votre espace de travail Azure Machine Learning.
Configuration d’un environnement de suivi
Pour suivre une exécution en dehors de l’environnement de calcul Azure Machine Learning (appelé par la suite « environnement de calcul local »), vous devez pointer votre environnement de calcul local vers l’URI de suivi Azure Machine Learning MLflow.
Notes
Lors de l’exécution sur Azure Compute (Notebooks Azure, Jupyter Notebooks hébergés sur des instances Azure Compute ou des clusters de calcul), vous n’avez pas besoin de configurer l’URI de suivi. Il est automatiquement configuré pour vous.
- Utilisation du SDK Azure Machine Learning
- Utilisation d’une variable d’environnement
- Génération de l’URI de suivi MLflow
S’APPLIQUE À :SDK Python azureml v1
Vous pouvez obtenir l’URI de suivi Azure Machine Learning MLflow à l’aide du kit de développement logiciel (SDK) Azure Machine Learning v1 pour Python. Vérifiez que la bibliothèque azureml-sdk est installée dans le cluster que vous utilisez. L’exemple suivant obtient l’URI de suivi MLFLow unique associé à votre espace de travail. Ensuite, la méthode set_tracking_uri() pointe l’URI de MLflow Tracking vers cet URI.
Utilisation du fichier de configuration d’espace de travail :
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())Conseil
Vous pouvez télécharger le fichier de configuration de l’espace de travail en procédant comme suit :
- Accédez à Azure Machine Learning Studio
- Cliquez sur l’angle supérieur droit de la page -> téléchargez le fichier de configuration.
- Enregistrez le fichier
config.jsondans le même répertoire que celui dans lequel vous travaillez.
À l’aide de l’ID d’abonnement, du nom du groupe de ressources et du nom de l’espace de travail :
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Définir le nom de l’expérience
Toutes les exécutions de MLflow sont enregistrées dans l'expérience active. Par défaut, les exécutions sont consignées dans une expérience nommée Default qui est automatiquement créée pour vous. Pour configurer l’expérience sur laquelle vous souhaitez travailler, utilisez la commande MLflow mlflow.set_experiment().
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
Conseil
Lors de l’envoi de travaux à l’aide du kit de développement logiciel (SDK) Azure Machine Learning, vous pouvez définir le nom de l’expérience à l’aide de la propriété experiment_name au moment de son envoi. Il n’est pas nécessaire de le configurer sur votre script d’apprentissage.
Démarrer un cycle d’apprentissage
Après avoir défini le nom de l’expérience MLflow, vous pouvez commencer votre cycle d’apprentissage avec start_run(). Utilisez ensuite log_metric() à activer l’API de journalisation de MLflow et commencer la journalisation des métriques de votre cycle d’apprentissage.
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
Pour plus d’informations sur la façon de consigner les métriques, les paramètres et les artefacts d’une exécution à l’aide de MLflow, consultez Consigner et afficher les métriques.
Suivre les exécutions sur Azure Machine Learning
S’APPLIQUE À :SDK Python azureml v1
Les exécutions à distance (travaux) vous permettent d’effectuer l’apprentissage de vos modèles de manière plus robuste et répétitive. Elles peuvent également tirer parti d’environnements de calcul plus puissants, comme des clusters de calcul Machine Learning. Pour en savoir plus sur les différentes options de calcul, consultez Utiliser des cibles de calcul pour l’entraînement des modèles.
Lors de l’envoi d’une exécution, Azure Machine Learning configure automatiquement MLflow pour qu’il utilise l’espace de travail dans lequel l’exécution a lieu. Cela signifie qu’il n’est pas nécessaire de configurer l’URI de suivi MLflow. De plus, les expériences sont automatiquement nommées en fonction des détails de l’envoi de l’expérience.
Important
Lors de l’envoi de travaux d’apprentissage à Azure Machine Learning, il n’est pas nécessaire de configurer l’URI de suivi MLflow sur votre logique d’apprentissage, car elle est déjà configurée pour vous. Il n’est pas non plus nécessaire de configurer le nom de l’expérience dans votre routine d’apprentissage.
Créer une routine d’apprentissage
Vous devez commencer par créer un sous-répertoire src, ainsi qu’un fichier contenant votre code d’apprentissage dans un fichier train.py dans le sous-répertoire src. Tout votre code d’entraînement sera placé dans le sous-répertoire src, y compris train.py.
Dans l’exemple de dépôt Azure Machine Learning, le code d’entraînement est tiré de cet exemple MLflow.
Copiez ce code dans le fichier :
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
Configurer l’expérience
Vous devez utiliser Python pour envoyer l’expérience à Azure Machine Learning. Dans un notebook ou un fichier Python, configurez votre environnement de calcul et d’exécution de l’apprentissage avec la classe Environment.
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
Construisez ensuite ScriptRunConfig avec votre calcul à distance en tant que cible de calcul.
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
Avec cette configuration du cycle de calcul et d’apprentissage, utilisez la méthode Experiment.submit() pour soumettre un cycle. Cette méthode définit automatiquement l’URI du suivi MLflow et dirige la journalisation de MLflow vers votre espace de travail.
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
Afficher les métriques et les artefacts dans votre espace de travail
Les métriques et les artefacts de la journalisation MLflow sont suivis dans votre espace de travail. Pour les voir à tout moment, accédez à votre espace de travail, puis recherchez l’expérience par son nom dans votre espace de travail dans Azure Machine Learning Studio. Ou exécutez le code ci-dessous.
Récupérez la métrique d’exécution à l’aide de MLflow get_run().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
Pour afficher les artefacts d’une exécution, vous pouvez utiliser la commande MlFlowClient.list_artifacts ()
client.list_artifacts(run_id)
Pour télécharger un artefact dans le répertoire actif, vous pouvez utiliser la commande MLFlowClient.download_artifacts ()
client.download_artifacts(run_id, "helloworld.txt", ".")
Pour plus d’informations sur la récupération des informations des expériences et des exécutions dans Azure Machine Learning à l’aide de MLflow, consultez Gérer les expériences et les exécutions avec MLflow.
Comparer et interroger
Comparez et interrogez toutes les cycles d’exécution de MLflow dans votre espace de travail Azure Machine Learning avec le code suivant. En savoir plus sur la façon d’interroger des cycles d’exécution avec MLflow.
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
Journalisation automatique
Avec Azure Machine Learning et MLFlow, les utilisateurs peuvent journaliser automatiquement les métriques, les paramètres de modèle et les artefacts de modèle lors de l’entraînement d’un modèle. Une variété de bibliothèques de machine learning connues sont prises en charge.
Pour activer la journalisation automatique, insérez le code suivant avant votre code d’entraînement :
mlflow.autolog()
En savoir plus sur la journalisation automatique avec MLflow.
Gérer les modèles
Enregistrez et suivez vos modèles avec le registre de modèles Azure Machine Learning qui prend en charge le registre de modèles MLflow. Les modèles Azure Machine Learning sont alignés avec le schéma de modèle MLflow, ce qui facilite l’exportation et l’importation de ces modèles dans différents flux de travail. Les métadonnées associées à MLflow, telles que l’ID d’exécution, sont également suivies avec le modèle inscrit pour la traçabilité. Les utilisateurs peuvent soumettre des exécutions de formation, enregistrer, mais aussi déployer des modèles produits à partir de MLflow.
Si vous souhaitez déployer et inscrire votre modèle prêt pour la production en une seule étape, consultez déployer et inscrire des modèles MLflow.
Pour inscrire et afficher un modèle à partir d’une exécution, procédez comme suit :
Une fois un cycle d’exécution terminé, appelez la méthode
register_model().# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")Affichez le modèle inscrit dans votre espace de travail avec Azure Machine Learning Studio.
Dans l’exemple suivant, le modèle inscrit,
my-modela des métadonnées de MLflow Tracking marquées.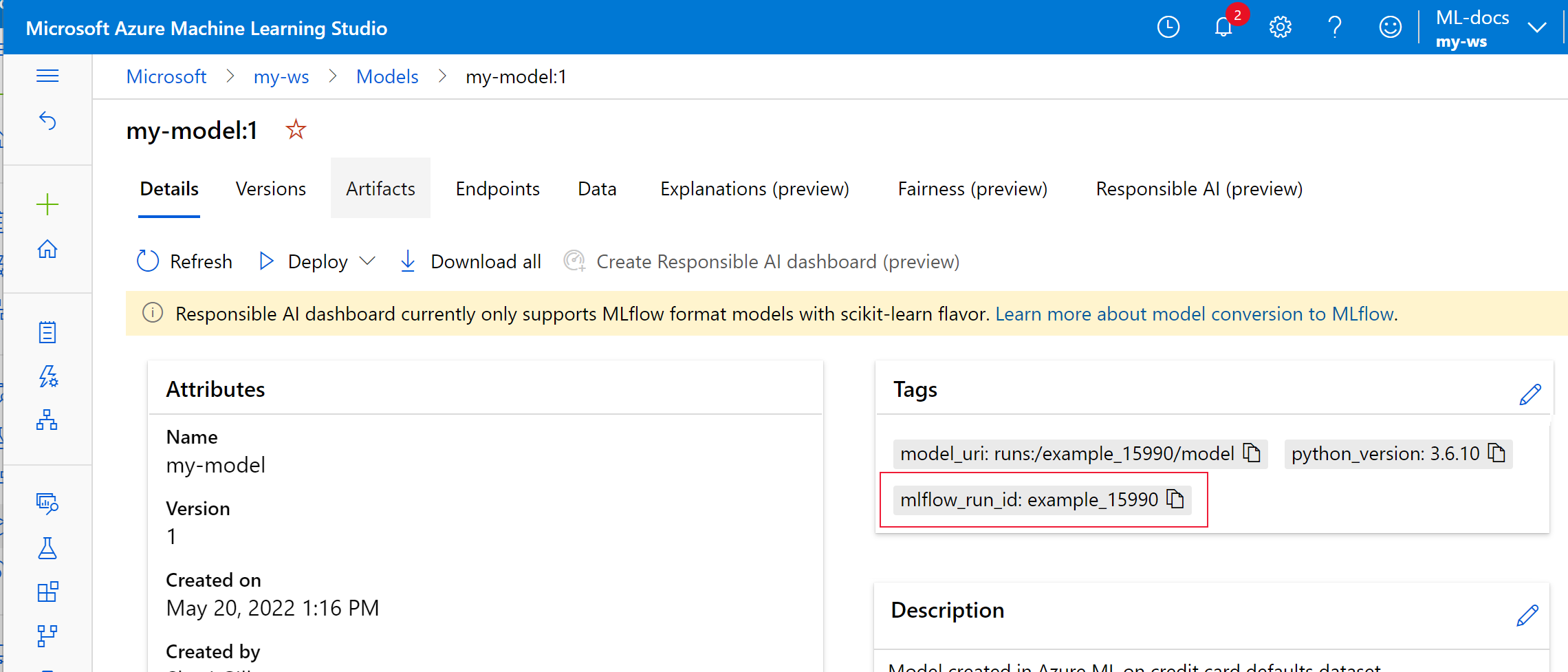
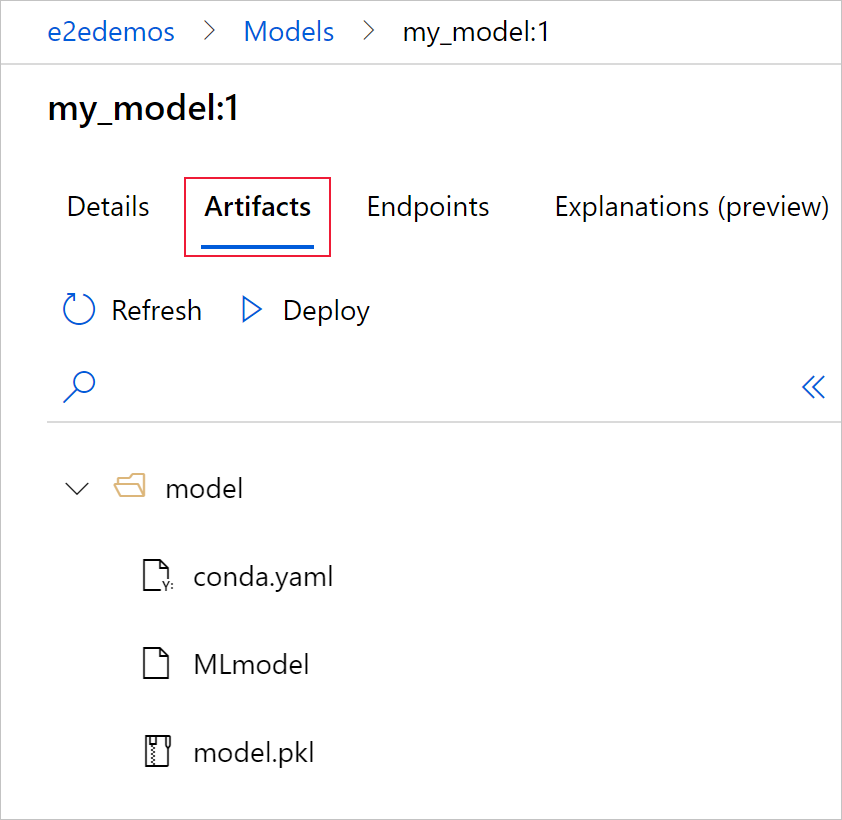
Sélectionnez l’onglet Artefacts pour afficher tous les fichiers de modèle qui s’alignent sur le schéma de modèle MLflow (conda.yaml, MLmodel, model.pkl).
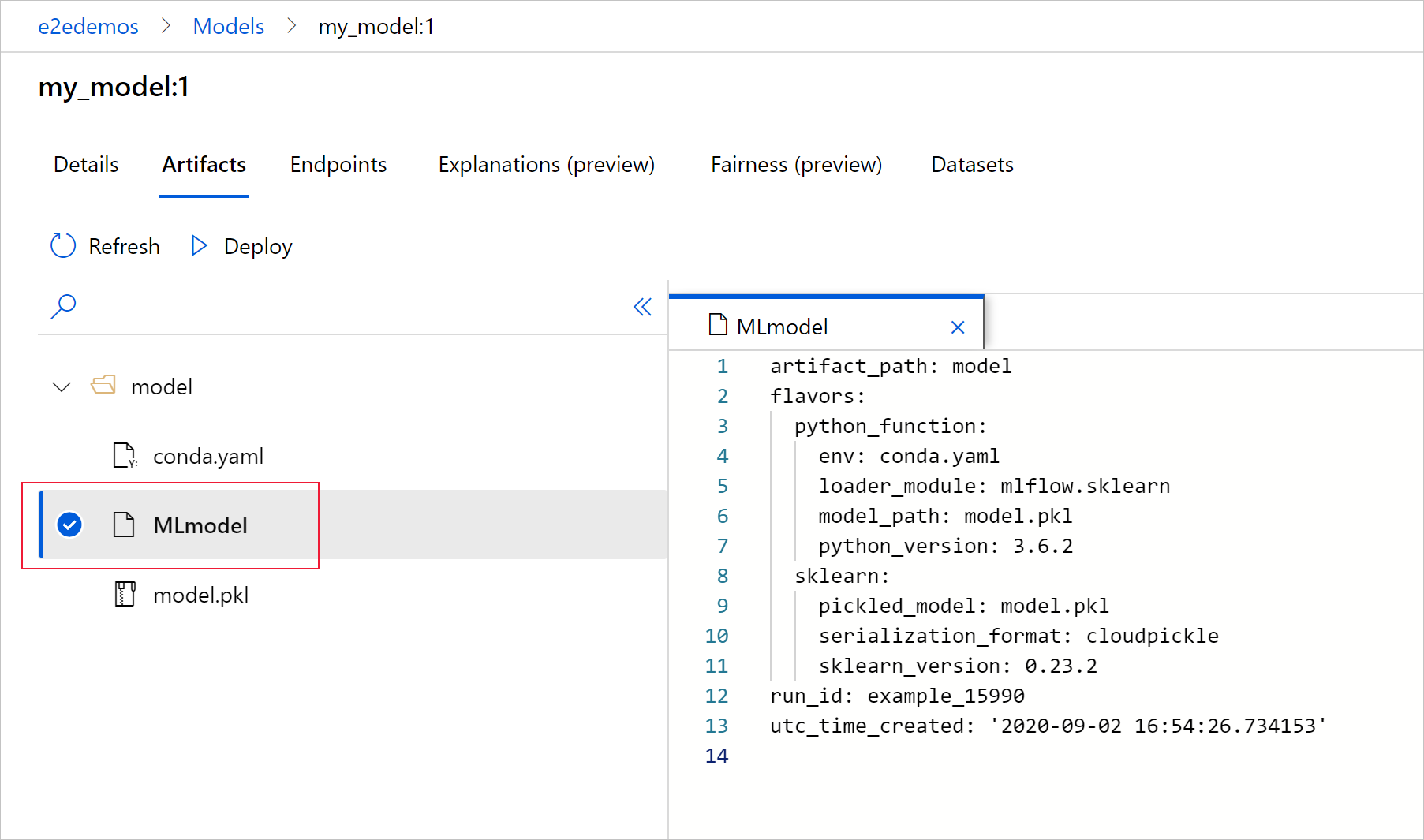
Sélectionnez MLmodel pour afficher le fichier MLmodel généré par l’exécution.
Nettoyer les ressources
Si vous ne prévoyez pas d’utiliser les métriques et artefacts enregistrés dans votre espace de travail, la possibilité de les supprimer individuellement est actuellement indisponible. Au lieu de cela, supprimez le groupe de ressources contenant le compte de stockage et l’espace de travail afin d’éviter des frais supplémentaires :
Dans le portail Azure, sélectionnez Groupes de ressources tout à gauche.
À partir de la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Exemples de notebooks
Les notebooks MLflow avec Azure Machine Learning illustrent et développent les concepts abordés dans cet article. Consultez également le référentiel piloté par la communauté, AzureML-Examples.
Étapes suivantes
- Déployer des modèles avec MLflow.
- Surveillez la dérive des données de vos modèles de production.
- Suivez les exécutions d’Azure Databricks avec MLflow.
- Gérez vos modèles.
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour