Résoudre des problèmes de latence de réplication dans un serveur flexible Azure Database pour MySQL
S'APPLIQUE À :  Azure Database pour MySQL - Serveur unique Azure Database pour MySQL - Serveur flexible
Azure Database pour MySQL - Serveur unique Azure Database pour MySQL - Serveur flexible
Important
Le serveur unique Azure Database pour MySQL est en voie de mise hors service. Nous vous conseillons vivement de procéder à une mise à niveau vers Azure Database pour MySQL – Serveur flexible. Pour obtenir plus d’informations sur la migration vers Azure Database pour MySQL – Serveur flexible, consultez Qu’en est-il du Serveur unique Azure Database pour MySQL ?
Remarque
Cet article fait référence à un terme que Microsoft n’utilise plus. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
La fonctionnalité de réplica en lecture vous permet de répliquer les données d’un serveur Azure Database pour MySQL sur un serveur réplica en lecture seule. Vous pouvez effectuer un scale-out des charges de travail en acheminant les requêtes de lecture et de rapport de l’application vers les serveurs de réplication. Cette configuration réduit la pression sur le serveur source et améliore les performances et la latence globales de l’application au fur et à mesure qu’elle est mise à l’échelle.
Les réplicas sont mis à jour de façon asynchrone à l’aide de la technologie de réplication de fichier journal binaire native du moteur MySQL (binlog). Pour plus d’informations, consultez vue d’ensemble de la configuration de la réplication basée sur la position des fichiers binlog MySQL.
Le décalage de réplication sur les réplicas de lecture secondaires dépend de plusieurs facteurs. Ces facteurs incluent, sans s’y limiter, les éléments suivants :
- Latence du réseau.
- Volume de transactions sur le serveur source.
- Niveau de calcul du serveur source et du serveur réplica de lecture secondaire.
- Requêtes en cours d’exécution sur le serveur source et le serveur secondaire.
Dans cet article, vous allez apprendre à résoudre les problèmes de latence de réplication dans Azure Database pour MySQL. Vous allez également mieux comprendre certaines causes courantes de l’augmentation de la latence de réplication sur les serveurs de réplica.
Remarque
Cet article contient des références au terme esclave, un terme que Microsoft n’utilise plus. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Concepts de réplication
Lorsqu’un journal binaire est activé, le serveur source écrit les transactions validées dans le journal binaire. Le journal binaire est utilisé pour la réplication. Il est activé par défaut pour tous les serveurs nouvellement approvisionnés qui prennent en charge jusqu’à 16 To de stockage. Sur les serveurs de réplication, deux threads s’exécutent sur chaque serveur de réplication. Un thread est le thread d’e/set l’autre est le thread SQL :
- Le thread d’E/S se connecte au serveur source et demande les journaux binaires mis à jour. Ce thread reçoit les mises à jour des journaux binaires. Ces mises à jour sont enregistrées sur un serveur de réplication, dans un journal local appelé lejournal de relais.
- Le thread SQL lit le journal de relais, puis applique les modifications de données sur les serveurs de réplication.
Surveillance de la latence de réplication
Azure Database pour MySQL fournit la mesure pour le décalage de réplication en secondes dans Azure Monitor. Cette mesure est disponible uniquement sur les serveurs de réplica en lecture. Il est calculé à partir de la mesure seconds_behind_master disponible dans MySQL.
Pour comprendre la cause de l’augmentation de la latence de réplication, connectez-vous au serveur de réplication à l’aide de MySQL Workbench ou Azure Cloud Shell. Exécutez ensuite la commande suivante.
Notes
Dans votre code, remplacez les valeurs d’exemple par le nom de votre serveur de réplication et le nom d’utilisateur de l’administrateur. Le nom d’utilisateur de l’administrateur requiert @\<servername> pour Azure Database pour MySQL.
mysql --host=myreplicademoserver.mysql.database.azure.com --user=myadmin@mydemoserver -p
Voici comment se présente l’expérience utilisateur dans le terminal Cloud Shell :
Requesting a Cloud Shell.Succeeded.
Connecting terminal...
Welcome to Azure Cloud Shell
Type "az" to use Azure CLI
Type "help" to learn about Cloud Shell
user@Azure:~$mysql -h myreplicademoserver.mysql.database.azure.com -u myadmin@mydemoserver -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64796
Server version: 5.6.42.0 Source distribution
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Dans le même terminal Cloud Shell, exécutez la commande suivante :
mysql> SHOW SLAVE STATUS;
Voici une sortie standard :
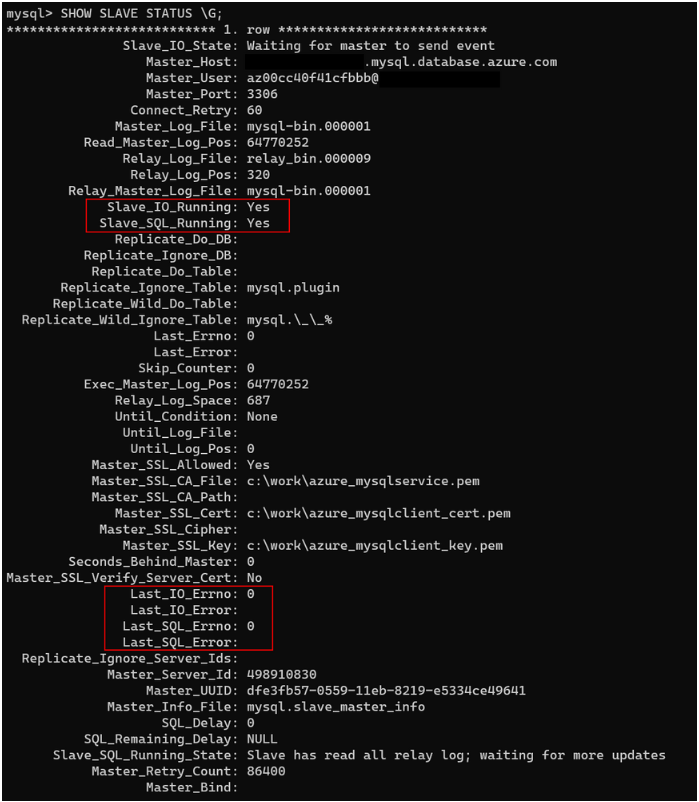
La sortie contient de nombreuses informations. Normalement, vous devez vous concentrer uniquement sur les lignes décrites dans le tableau suivant.
| Métrique | Description |
|---|---|
| Slave_IO_State | Représente l’état actuel du thread d’e/s. En règle générale, l’état est « en attente de l’envoi d’un événement par le maître » si le serveur source (maître) est en cours de synchronisation. Un état tel que « Connexion au maître », indique que le réplica a perdu la connexion au serveur source. Assurez-vous que le serveur source est en cours d’exécution ou vérifiez si un pare-feu bloque la connexion. |
| Master_Log_File | Représente le fichier journal binaire dans lequel le serveur source écrit. |
| Read_Master_Log_Pos | Indique l’emplacement où le serveur source écrit dans le fichier journal binaire. |
| Relay_Master_Log_File | Représente le fichier journal binaire que le serveur réplica lit à partir du serveur source. |
| Slave_IO_Running | Indique si le thread d’E/S est en cours d’exécution. La valeur doit être Yes. Si la valeur est NO, alors la réplication est probablement rompue. |
| Slave_SQL_Running | Indique si le thread SQL est en cours d’exécution. La valeur doit être Yes. Si la valeur est NO, alors la réplication est probablement rompue. |
| Exec_Master_Log_Pos | Indique la position du Relay_Master_Log_File que le réplica applique. En cas de latence, cette séquence de positions doit être inférieure à Read_Master_Log_Pos. |
| Relay_Log_Space | Indique la taille cumulée totale de tous les fichiers journaux de relais existants. Vous pouvez vérifier la taille limite maximale en interrogeant SHOW GLOBAL VARIABLES comme relay_log_space_limit. |
| Seconds_Behind_Master | Affiche la latence de réplication en secondes. |
| Last_IO_Errno | Affiche le code d’erreur de thread d’E/S, le cas échéant. Pour plus d’informations sur ces codes, consultez la page de référence des messages d’erreur MySQL Server. |
| Last_IO_Error | Affiche le message d’erreur de thread d’E/S, le cas échéant. |
| Last_SQL_Errno | Affiche le code d’erreur de thread SQL, le cas échéant. Pour plus d’informations sur ces codes, consultez la page de référence des messages d’erreur MySQL Server. |
| Last_SQL_Error | Affiche le message d’erreur de thread SQL, le cas échéant. |
| Slave_SQL_Running_State | Indique l’état actuel du thread SQL. Dans cet état, System lock est normal. Il est également normal de voir un état de Waiting for dependent transaction to commit. Cet état indique que le réplica attend une mise à jour des transactions validées par les threads de travail SQL. |
Si Slave_IO_Running est Yes et Slave_SQL_Running est Yes, la réplication s’exécute bien.
Ensuite, vérifiez Last_IO_Errno, Last_IO_Error, Last_SQL_Errno et Last_SQL_Error. Ces champs affichent le numéro d’erreur et le message d’erreur de l’erreur la plus récente qui a provoqué l’arrêt du thread SQL. Un numéro d’erreur de 0 et un message vide signifient qu’il n’y a pas d’erreur. Recherchez toute valeur d’erreur différente de zéro en vérifiant le code d’erreur dans lesinformations de référence sur les messages d’erreur MySQL Server.
Scénarios courants de latence de réplication élevée
Les sections suivantes traitent des scénarios dans lesquels une latence de réplication élevée est courante.
Latence du réseau ou consommation élevée du processeur sur le serveur source
Si vous observez les valeurs suivantes, la cause la plus courante de latence de réplication est une latence du réseau élevée ou une consommation élevée du processeur sur le serveur source.
Slave_IO_State: Waiting for master to send event
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller than Master_Log_File, e.g. mysql-bin.00010
Dans ce cas, le thread d’e/s est en cours d’exécution et en attente sur le serveur source. Le serveur source a déjà écrit dans le fichier journal binaire numéro 20. Le réplica a reçu uniquement jusqu’au fichier numéro 10. Les principaux facteurs de latence de réplication élevée dans ce scénario sont la vitesse du réseau ou une utilisation élevée du processeur sur le serveur source.
Dans Azure, la latence du réseau au sein d’une région peut généralement être mesurée en millisecondes. Entre les régions, la latence est comprise entre les millisecondes et les secondes.
Dans la plupart des cas, le délai de connexion entre les threads d’e/s et le serveur source est dû à une utilisation élevée du processeur sur le serveur source. Les threads d’e/s sont traités lentement. Vous pouvez détecter ce problème à l’aide de Azure Monitor pour vérifier l’utilisation du processeur et le nombre de connexions simultanées sur le serveur source.
Si vous ne voyez pas d’utilisation élevée du processeur sur le serveur source, le problème peut être lié à la latence du réseau. Si la latence du réseau est soudainement anormalement élevée, consultez la page des états d’Azure pour connaître les problèmes connus ou les pannes.
Pics de transactions importants sur le serveur source
Si les valeurs suivantes s’affichent, une forte rafale de transactions sur le serveur source est probablement à l’origine de la latence de réplication.
Slave_IO_State: Waiting for the slave SQL thread to free enough relay log space
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller then Master_Log_File, e.g. mysql-bin.00010
La sortie indique que le réplica peut récupérer le journal binaire situé derrière le serveur source. Toutefois, le thread d’e/s de réplica indique que l’espace du journal de relais est déjà plein.
La vitesse du réseau n’est pas à l’origine du délai. Le réplica tente de rattraper son retard. Toutefois, la taille du journal binaire mise à jour dépasse la limite supérieure de l’espace du journal de relais.
Pour résoudre ce problème, activez le journal des requêtes lentes sur le serveur source. Utilisez des journaux de requêtes lents pour identifier les transactions de longue durée sur le serveur source. Ajustez ensuite les requêtes identifiées pour réduire la latence sur le serveur.
La latence de réplication de ce tri est généralement causée par le chargement des données sur le serveur source. Lorsque les serveurs sources ont des chargements de données hebdomadaires ou mensuels, la latence de la réplication est malheureusement inévitable. Les serveurs de réplication finissent par se retrouver après la fin du chargement des données sur le serveur source.
Lenteur du serveur réplica
Si vous observez les valeurs suivantes, le problème peut être sur le serveur de réplication.
Slave_IO_State: Waiting for master to send event
Master_Log_File: The binary log file sequence equals to Relay_Master_Log_File, e.g. mysql-bin.000191
Read_Master_Log_Pos: The position of master server written to the above file is larger than Relay_Log_Pos, e.g. 103978138
Relay_Master_Log_File: mysql-bin.000191
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Exec_Master_Log_Pos: The position of slave reads from master binary log file is smaller than Read_Master_Log_Pos, e.g. 13468882
Seconds_Behind_Master: There is latency and the value here is greater than 0
Dans ce scénario, la sortie indique que le thread d’e/s et le thread SQL s’exécutent correctement. Le réplica lit le même fichier de journal binaire que le serveur source écrit. Toutefois, une certaine latence sur le serveur de réplication reflète la même transaction à partir du serveur source.
Les sections suivantes décrivent les causes courantes de ce type de latence.
Aucune clé primaire ou unique sur une table
Azure Database pour MySQL utilise la réplication basée sur les lignes. Le serveur source écrit les événements dans le journal binaire, en enregistrant les modifications dans les lignes individuelles de la table. Le thread SQL réplique ensuite ces modifications dans les lignes correspondantes de la table sur le serveur de réplication. Lorsqu’une table n’a pas de clé primaire ou de clé unique, le thread SQL analyse toutes les lignes de la table cible pour appliquer les modifications. Cette analyse peut entraîner une latence de réplication.
Dans MySQL, la clé primaire est un index associé qui garantit des performances de requête rapides, car il ne peut pas inclure de valeurs NULL. Si vous utilisez le moteur de stockage InnoDB, les données de la table sont organisées de façon physique afin d’effectuer des recherches ultra-rapides et de les trier en fonction de la clé primaire.
Nous vous recommandons d’ajouter une clé primaire sur les tables du serveur source avant de créer le serveur de réplication. Dans ce scénario, vous devez ajouter des clés primaires sur le serveur source et recréer des réplicas en lecture pour améliorer la latence de réplication.
Utilisez la requête suivante pour identifier les tables qui ne contiennent pas de clé primaire sur le serveur source :
select tab.table_schema as database_name, tab.table_name
from information_schema.tables tab left join
information_schema.table_constraints tco
on tab.table_schema = tco.table_schema
and tab.table_name = tco.table_name
and tco.constraint_type = 'PRIMARY KEY'
where tco.constraint_type is null
and tab.table_schema not in('mysql', 'information_schema', 'performance_schema', 'sys')
and tab.table_type = 'BASE TABLE'
order by tab.table_schema, tab.table_name;
Requêtes de longue durée sur le serveur de réplication
La charge de travail sur le serveur de réplication peut décaler le thread SQL derrière le thread d’e/s. Les requêtes de longue durée sur le serveur de réplication sont l’une des causes les plus courantes de latence de réplication élevée. Pour résoudre ce problème, activez le journal des requêtes lentes sur le serveur de réplication.
Les requêtes lentes peuvent augmenter la consommation des ressources ou ralentir le serveur afin que le réplica ne puisse pas rattraper le serveur source. Dans ce scénario, réglez les requêtes lentes. Des requêtes plus rapides empêchent le blocage du thread SQL et améliorent considérablement la latence de la réplication.
Requêtes DDL sur le serveur source
Sur le serveur source, une commande DDL (Data Definition Language) comme ALTER TABLE peut prendre beaucoup de temps. Pendant l’exécution de la commande DDL, des milliers d’autres requêtes peuvent s’exécuter en parallèle sur le serveur source.
Lorsque le DDL est répliqué, pour garantir la cohérence de la base de données, le moteur MySQL exécute le DDL dans un thread de réplication unique. Au cours de cette tâche, toutes les autres requêtes répliquées sont bloquées et doivent attendre que l’opération DDL se termine sur le serveur de réplication. Même les opérations DDL en ligne provoquent ce retard. Les opérations DDL augmentent la latence de la réplication.
Si vous avez activé le journal des requêtes lentes sur le serveur source, vous pouvez détecter ce problème de latence en recherchant une commande DDL qui s’exécutait sur le serveur source. À l’aide de la suppression, du changement de nom et de la création d’index, vous pouvez utiliser l’algorithme InPlace pour l’instruction ALTER TABLE. Vous devrez peut-être copier les données de la table et reconstruire la table.
En règle générale, les DML simultanés sont pris en charge pour l’algorithme InPlace. Toutefois, vous pouvez rapidement prendre un verrou de métadonnées exclusif sur la table lorsque vous préparez et exécutez l’opération. Ainsi, pour l’instruction CREATe INDEX, vous pouvez utiliser l’ALGORITHMe et le verrou des clauses pour influencer la méthode de copie de table et le niveau de concurrence pour la lecture et l’écriture. Vous pouvez toujours empêcher les opérations DML en ajoutant un index de texte intégral ou un index SPATIAL.
L’exemple suivant crée un index à l’aide de clauses d’ALGORITHMe et de VERROUs.
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Malheureusement, pour une instruction DDL qui requiert un verrou, vous ne pouvez pas éviter la latence de réplication. Pour réduire les effets potentiels, effectuez ces types d’opérations DDL pendant les heures creuses, par exemple pendant la nuit.
Serveur réplica rétrogradé
Dans Azure Database pour MySQL, les réplicas de lecture utilisent la même configuration de serveur que le serveur source. Vous pouvez modifier la configuration du serveur de réplication après qu’il a été créé.
Si le serveur de réplication est rétrogradé, la charge de travail peut consommer plus de ressources, ce qui peut à son tour entraîner la latence de la réplication. Pour détecter ce problème, utilisez Azure Monitor pour vérifier la consommation de l’UC et de la mémoire du serveur de réplication.
Dans ce scénario, nous vous recommandons de conserver la configuration du serveur de réplication à des valeurs égales ou supérieures aux valeurs du serveur source. Cette configuration permet au réplica de suivre le serveur source.
Amélioration de la latence de la réplication en réglant les paramètres du serveur source
Dans Azure Database pour MySQL, par défaut, la réplication est optimisée pour s’exécuter avec les threads parallèles sur les réplicas. Lorsque des charges de travail à forte concurrence sur le serveur source provoquent le basculement du serveur de réplication, vous pouvez améliorer la latence de réplication en configurant le paramètre binlog_group_commit_sync_delay sur le serveur source.
Le paramètre binlog_group_commit_sync_delay contrôle le nombre de microsecondes pendant lesquelles la validation du journal binaire attend avant de synchroniser le fichier journal binaire. L’avantage de ce paramètre est qu’au lieu d’appliquer immédiatement chaque transaction validée, le serveur source envoie les mises à jour binaires du journal en bloc. Ce délai réduit les e/s sur le réplica et contribue à améliorer les performances.
Il peut être utile de définir le paramètre binlog_group_commit_sync_delay sur 1000 ou environ. Ensuite, surveillez la latence de réplication. Définissez ce paramètre avec prudence et utilisez-le uniquement pour les charges de travail à fort accès concurrentiel.
Important
Dans le serveur de réplication, il est recommandé que le paramètre binlog_group_commit_sync_delay ait la valeur 0. Cela est recommandé, car, contrairement au serveur source, le serveur de réplication n’a pas d’accès concurrentiel élevé et l’augmentation de la valeur de binlog_group_commit_sync_delay sur le serveur de réplication peut entraîner l’augmentation du décalage de la réplication.
Pour les charges de travail de faible concurrence qui incluent de nombreuses transactions Singleton, le paramètre binlog_group_commit_sync_delay peut augmenter la latence. La latence peut augmenter, car le thread d’e/s attend des mises à jour en bloc des journaux binaires, même si seules quelques transactions sont validées.
Options de résolution de problèmes avancées
Si l’utilisation de la commande « afficher l’état d’esclave » ne fournit pas suffisamment d’informations pour résoudre des problèmes de latence de réplication, essayez d’afficher ces options supplémentaires pour en savoir plus sur les processus actifs ou en attente.
Afficher la table des threads
La table performance_schema.threads indique l’état du processus. Un processus avec l’état En attente du verrou lock_type indique qu’il existe un verrou sur l’une des tables, empêchant le thread de réplication de mettre à jour la table.
SELECT name, processlist_state, processlist_time FROM performance_schema.threads WHERE name LIKE '%slave%';
Si vous souhaitez obtenir plus d’informations, consultez États généraux des threads.
Afficher la table replication_connection_status
La table performance_schema.replication_connection_status affiche l’état actuel du thread d’E/S de réplication qui gère la connexion du réplica à la source, qui change plus fréquemment. La table contient des valeurs qui varient pendant la connexion.
SELECT * FROM performance_schema.replication_connection_status;
Afficher la table replication_applier_status_by_worker
La table performance_schema.replication_applier_status_by_worker montre l’état des threads du Worker, Dernière transaction affichée, ainsi que le dernier numéro d’erreur et le dernier message, qui vous aident à trouver la transaction présentant un problème et à identifier la cause racine.
Vous pouvez exécuter les commandes ci-dessous dans la réplication des données entrantes pour ignorer des erreurs ou des transactions :
az_replication_skip_counter
ou
az_replication_skip_gtid_transaction
SELECT * FROM performance_schema.replication_applier_status_by_worker;
Afficher l’instruction SHOW RELAYLOG EVENTS
L’instruction show relaylog events affiche les événements dans le journal de relais d’un réplica.
· Pour la réplication basée sur GITD (réplica Lecture), l’instruction affiche la transaction GTID et le fichier binlog ainsi que sa position. Vous pouvez utiliser mysqlbinlog pour obtenir le contenu et les instructions en cours d’exécution. · Pour la réplication de position binlog MySQL (utilisée pour la réplication des données entrantes), elle affiche les instructions en cours d’exécution, ce qui permet de savoir quelles transactions de table sont exécutées
Vérifier la sortie du moniteur InnoDB Standard et du moniteur de verrou
Vous pouvez également essayer de vérifier la sortie du moniteur InnoDB Standard et du moniteur de verrou pour faciliter la résolution des verrous et des interblocages et réduire le retard de réplication. Le moniteur de verrou est identique au moniteur Standard, sauf qu’il inclut des informations de verrou supplémentaires. Pour afficher ces informations supplémentaires de verrou et d’interblocage, exécutez la commande show engine innodb status\G.
Étapes suivantes
Consultez la vue d’ensemble de la réplication MySQL binlog.