Options de configuration pour réduire la latence du réseau avec des applications SAP
Important
En novembre 2021, nous avons apporté des modifications importantes à la manière d’utiliser les groupes de placement de proximité avec la charge de travail SAP dans les déploiements de zone.
Les applications SAP basées sur l’architecture SAP NetWeaver ou SAP S/4HANA sont sensibles à la latence réseau entre la couche Application SAP et la couche Base de données SAP. Cette sensibilité est due au fait que la plupart de la logique métier s’exécute dans la couche Application. Étant donné que la couche Application SAP exécute la logique métier, elle émet des requêtes à la base de données à une fréquence élevée (plusieurs milliers ou dizaines de milliers par seconde). Dans la plupart des cas, la nature de ces requêtes est simple. Elles peuvent souvent être exécutées sur la couche Base de données en 500 microsecondes ou moins.
Le temps passé sur le réseau à envoyer une telle requête de la couche Application à la couche Base de données et à recevoir le jeu de résultats a un impact majeur sur le temps nécessaire à l’exécution des processus métier. Cette sensibilité à la latence réseau est la raison pour laquelle vous souhaiterez peut-être atteindre une latence réseau minimale donnée dans les projets de déploiement SAP. Voir la Note de support SAP 1100926 - FAQ : Performances réseau pour obtenir des instructions sur la façon de classifier la latence réseau.
Dans de nombreuses régions Azure, le nombre de centres de données a augmenté. En même temps, les clients, en particulier pour les systèmes SAP haut de gamme, utilisent des familles de machines virtuelles davantage spécifiques comme la famille Mv2 ou Mv3 et les versions ultérieures. Ces types de machines virtuelles Azure ne sont pas toujours disponibles dans chacun des centres de données qui collecte des données dans une région Azure. Ces faits peuvent créer des opportunités d’optimisation de la latence du réseau entre la couche application SAP et la couche SGBD SAP.
Azure fournit différentes options de déploiement pour les charges de travail SAP. Pour le type de déploiement choisi, des options pour optimiser la latence réseau s’offrent à vous si nécessaire. Des informations détaillées sur chaque option sont présentées dans cet article :
- Groupes de placement de proximité
- Groupe de machines virtuelles identiques avec une orchestration flexible
Groupes de placement de proximité
Les groupes de placement de proximité permettent de regrouper différents types de VM sous une seule colonne vertébrale de réseau, ce qui garantit une faible latence optimale du réseau entre eux. Lorsque la première VM est déployée dans un groupe de placement de proximité, cette VM est liée à une colonne vertébrale de réseau spécifique. Comme toutes les autres machines virtuelles qui vont être déployées dans le même groupe de placement de proximité, ces machines virtuelles sont regroupées sous la même branche centrale réseau. Comme c’est le cas pour ce prospect, l’utilisation de la construction introduit également des restrictions et des pièges :
- Vous ne pouvez pas supposer que tous les types de machines virtuelles Azure sont disponibles dans tous les centres de données Azure et sous chaque branche centrale du réseau. Par conséquent, la combinaison de différents types de machines virtuelles dans un groupe de placement de proximité peut être sérieusement restreinte. Ces restrictions surviennent parce que le matériel hôte nécessaire à l'exécution d'un certain type de machine virtuelle peut ne pas être présent dans le centre de données ou sous la branche centrale réseau auquel le groupe de placement de proximité a été attribué.
- Quand vous redimensionnez certaines machines virtuelles qui se trouvent dans un groupe de placement de proximité, vous ne pouvez pas supposer automatiquement que dans tous les cas, le nouveau type de machine virtuelle est disponible dans le même centre de données ou sous la même branche centrale du réseau que les autres machines virtuelles qui sont affectées au groupe de placement de proximité.
- Comme Azure désactive le matériel, il peut forcer certaines machines virtuelles d’un groupe de placement de proximité dans un autre centre de donnés Azure ou sous une autre branche centrale réseau. Pour plus d’informations sur ce cas, consultez les Groupes de placement de proximité du document
Important
En raison de restrictions potentielles, seuls les groupes de placement de proximité doivent être utilisés :
- Si nécessaire dans certains scénarios (voir plus loin)
- Lorsque la latence du réseau entre la couche application et la couche SGBD est trop élevée et a un impact sur la charge de travail
- Uniquement sur la granularité d’un seul système SAP et non pour l’ensemble du paysage système ou SAP complet
- Pour conserver les différents types de machines virtuelles et un nombre minimum de machines virtuelles dans un groupe de placement de proximité
Les scénarios dans lesquels les groupes de placement de proximité peuvent être utilisés pour optimiser la latence réseau :
- Vous vouliez déployer les ressources critiques de votre charge de travail SAP dans différentes zones de disponibilité et, d’autre part, vous avez besoin que les machines virtuelles de la couche Application seraient réparties dans différents domaines d’erreur en utilisant des groupes à haute disponibilité dans chacune des zones. Dans ce cas, comme décrit plus loin dans le document, les groupes de placement de proximité sont le ciment nécessaire.
- Déploiement de la charge de travail SAP avec des groupes à haute disponibilité. Où la couche base de données SAP, la couche application SAP et les machines virtuelles ASCS/SCS ont été regroupées dans trois groupes à haute disponibilité différents. Dans ce cas, vous voulez vérifier que les groupes à haute disponibilité ne sont pas répartis dans l’ensemble de la région Azure, car cela peut, en fonction de la région Azure, entraîner une latence réseau pouvant avoir un impact négatif sur la charge de travail SAP.
- Vous avez utilisé des groupes de placement de proximité pour regrouper des machines virtuelles afin d’atteindre une latence réseau la plus faible possible entre les services hébergés sur les machines virtuelles. Par exemple, la latence dans une zone de disponibilité seule ne répond pas aux exigences de l’application.
Comme pour le scénario de déploiement n° 2, dans de nombreuses régions, en particulier les régions sans zones de disponibilité et la plupart des régions avec zones de disponibilité, la latence du réseau indépendamment de l’implémentation des machines virtuelles est acceptable. Toutefois, certaines régions d’Azure ne peuvent pas fournir une expérience suffisamment bonne si elles ne colocalisent pas les trois différents groupes à haute disponibilité sans utiliser de groupes de placement de proximité.
Définition des groupes de placement de proximité
Un groupe de placement de proximité Azure est une construction logique. Lorsqu’un groupe de placement de proximité est défini, il est lié à une région Azure et à un groupe de ressources Azure. Quand des machines virtuelles sont déployées, un groupe de placement de proximité est référencé par :
- La première machine virtuelle Azure déployée sous une branche centrale réseau avec de nombreuses unités de calcul Azure et une faible latence réseau. Une telle branche centrale réseau correspond souvent à un seul centre de données Azure. Vous pouvez considérer la première machine virtuelle comme une « machine virtuelle d’étendue » qui est déployée dans une unité d’échelle de calcul basée sur les algorithmes d’allocation Azure qui sont finalement combinés avec les paramètres de déploiement.
- Toutes les machines virtuelles suivantes déployées qui référencent le groupe de placement de proximité vont être déployées sous la même branche centrale réseau que la première machine virtuelle.
Notes
Si aucun matériel hôte pouvant exécuter un type VM spécifique sous la branche centrale du réseau où la première machine virtuelle a été placée n’est déployé, le déploiement du type VM demandé échoue. Vous obtenez un message d’échec d’allocation qui indique que la machine virtuelle ne peut pas être prise en charge dans le périmètre du groupe de placement de proximité.
Pour limiter les risques d’échec, nous vous recommandons d’utiliser l’option d’intention quand vous créez le groupe de placement de proximité. L’option d’intention vous permet de lister les types VM que vous prévoyez d’ajouter dans le groupe de placement de proximité. Cette liste de types VM est utilisée pour rechercher le meilleur centre de données qui héberge ces types VM. Si le centre de données est trouvé, le groupe de placement de proximité est créé, limité au centre de données qui répond aux exigences de la référence SKU VM. Si aucun centre de données n’est trouvé, la création du groupe de placement de proximité échoue. Plus d’informations sont disponibles dans la documentation Groupe de placement de proximité - Utiliser l’intention pour spécifier des tailles VM. Pour rappel, les situations de capacité réelles ne sont pas prises en compte dans les vérifications déclenchées par l’option d’intention. Par conséquent, il peut encore y avoir des erreurs d’allocation liées à une capacité disponible insuffisante.
Plusieurs groupes de placement de proximité peuvent être affectés à un seul et même groupe de ressources Azure. En revanche, un groupe de placement de proximité ne peut être affecté qu’à un seul groupe de ressources Azure.
Pour plus d’informations et des exemples de déploiement de groupes de placement de proximité, consultez la documentation disponible.
Groupes de placement de proximité avec des déploiements de zone
Il est important de fournir une latence réseau raisonnablement faible entre la couche Application SAP et la couche SGBD. Dans la plupart des cas, un déploiement zonal suffit à répondre à cette exigence. Dans certains cas spécifiques, un déploiement zonal unique pourrait ne pas suffire à répondre aux besoins de latence de l’application. Ces scénarios nécessitent de placer les machines virtuelles aussi près que possible et d’activer une latence de réseau raisonnablement faible. Vous pouvez définir un groupe de placement de proximité Azure pour un tel système SAP.
Évitez de regrouper plusieurs systèmes de non-production ou de production SAP dans un même groupe de placement de proximité. Évitez les regroupements de systèmes SAP, car plus vous regroupez de systèmes dans un groupe de placement de proximité, plus la probabilité est élevée :
- Vous avez besoin d’un type de machine virtuelle qui n’est pas disponible sous la branche centrale réseau dans laquelle le groupe de placement de proximité a été affecté.
- Que les ressources des machines virtuelles non courantes, telles que les machines virtuelles de la série M, soient finalement non satisfaites si vous avez besoin d’augmenter le nombre de machines virtuelles dans un groupe de placement de proximité au fil du temps.
En s’appuyant sur de nombreuses améliorations déployées par Microsoft dans les régions Azure pour réduire la latence du réseau au sein d'une zone de disponibilité Azure, les directives de déploiement lors de l’utilisation de groupes de placement de proximité pour les déploiements zonaux, ressemblent à ceci :
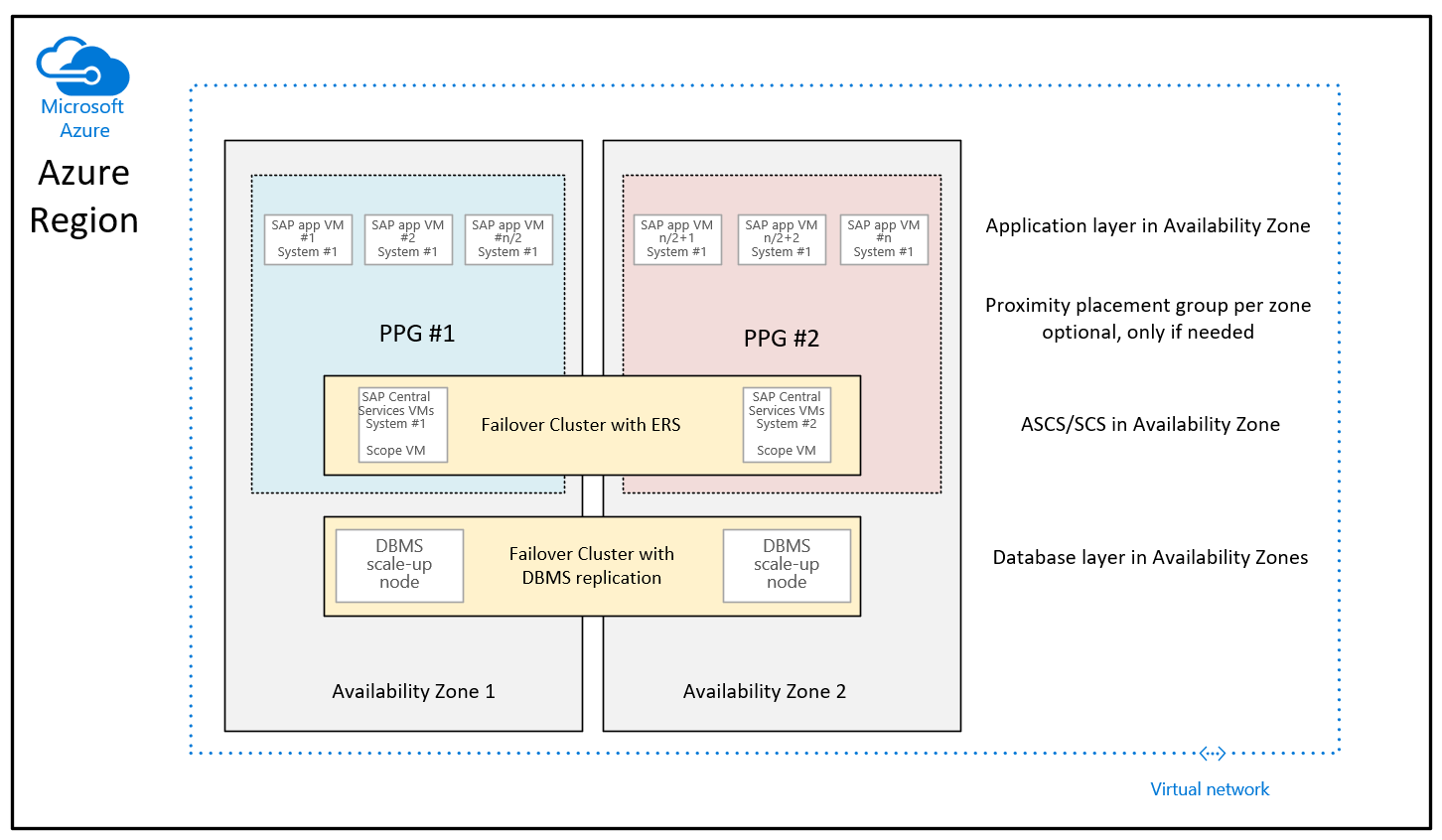
La différence avec la recommandation donnée jusqu’à présent réside dans le fait que les machines virtuelles de base de données des deux zones ne font plus partie des groupes de placement de proximité. Les groupes de placement de proximité par zone sont désormais étendus avec le déploiement de la machine virtuelle exécutant les instances SAP ASCS/SCS. Cela signifie également que pour les régions où les zones de disponibilité sont collectées par plusieurs centres de données, l’instance ASCS/SCS et la couche Application peuvent s’exécuter sous une branche centrale réseau et les machines virtuelles de base de données sous une autre branche centrale réseau. Toutefois, avec les améliorations apportées au réseau, la latence du réseau entre la couche application SAP et la couche SGBD devrait toujours être suffisante pour des performances et un débit de qualité suffisante. Grâce à cette nouvelle configuration, vous disposez d’une plus grande flexibilité pour redimensionner les machines virtuelles ou passer aux nouveaux types de machines virtuelles avec la couche SGBD ou la couche application du système SAP.
Pour le cas particulier de l’utilisation d’Azure NetApp Files pour l’environnement SGBD et de la fonctionnalité liée à Azure NetApp Files, le groupe de volumes d’application Azure NetApp Files pour SAP HANA et son besoin de groupes de placement de proximité, consultez le document Volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA.
Groupes de placement de proximité avec des déploiements de groupe à haute disponibilité
Dans ce cas, l’objectif est d’utiliser des groupes de placement de proximité pour colocaliser les machines virtuelles déployées par le biais de groupes à haute disponibilité différents. Dans ce scénario d’utilisation, vous n’utilisez pas de déploiement contrôlé sur différentes zones de disponibilité dans une région. Au lieu de cela, vous souhaitez déployer le système SAP à l’aide de groupes à haute disponibilité. Par conséquent, vous disposez au moins d’un groupe à haute disponibilité pour les machines virtuelles SGBD, les machines virtuelles ASCS/SCS et les machines virtuelles de la couche application. Comme vous ne pouvez pas spécifier au moment du déploiement d’une machine virtuelle un groupe à haute disponibilité ET une zone de disponibilité, vous ne pouvez pas contrôler l’allocation des machines virtuelles dans les différents groupes à haute disponibilité. Ainsi, dans certaines régions Azure, la latence réseau entre les différentes machines virtuelles pourrait être trop élevée pour offrir des performances suffisantes. Par conséquent, l’architecture qui en résulte ressemble à ce qui suit :
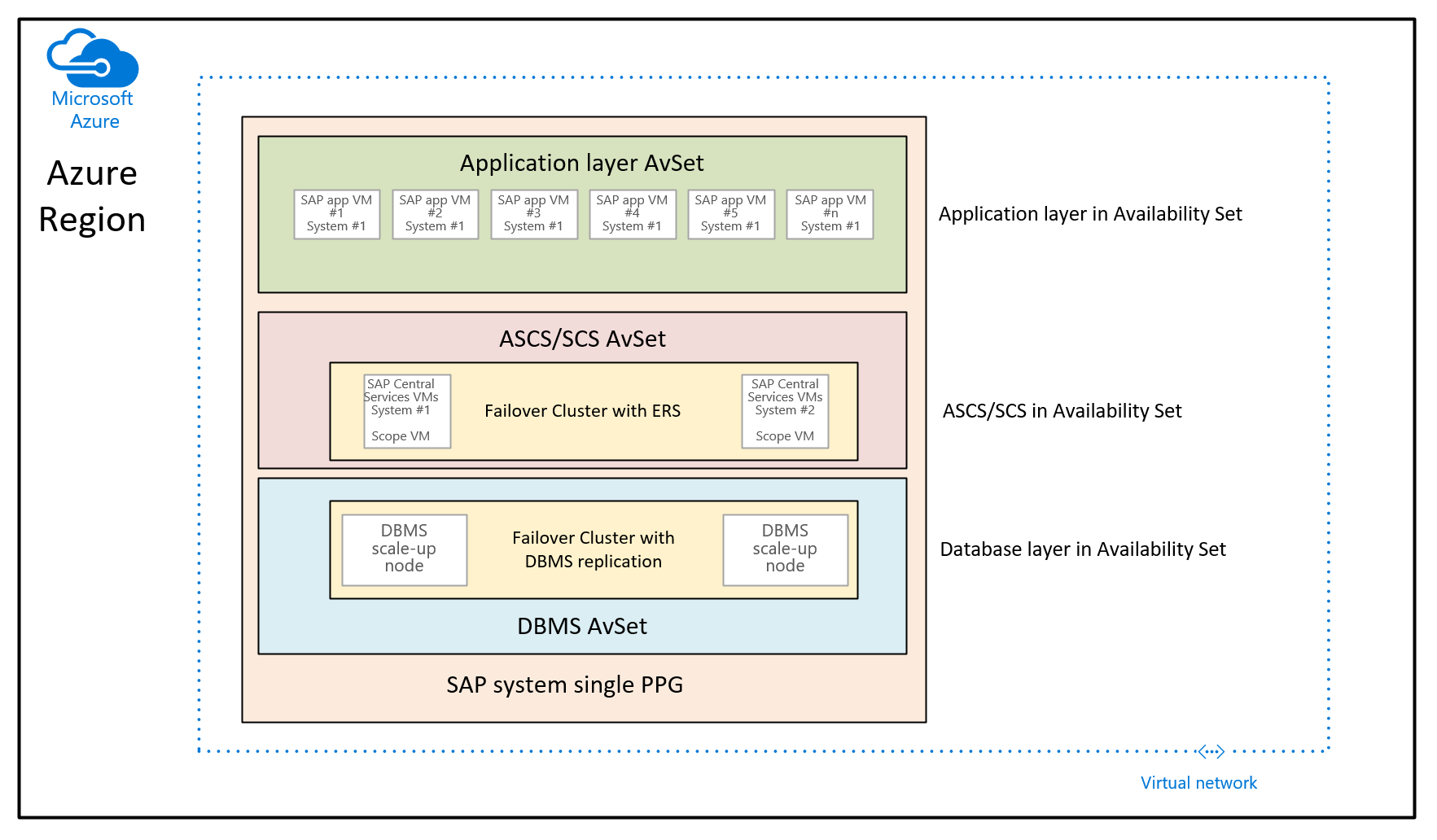
Dans ce graphique, un seul groupe de placement de proximité serait affecté à un seul système SAP. Ce PPG est affecté aux trois groupes à haute disponibilité. Le groupe de placement de proximité est ensuite étendu en déployant les premières machines virtuelles de la couche base de données dans le groupe à haute disponibilité SGBD. Cette recommandation d’architecture colocalise toutes les machines virtuelles sous la même branche centrale réseau. Elle présente les restrictions mentionnées plus haut dans cet article. Par conséquent, l’architecture de groupe de placement de proximité doit être utilisée de manière éparse.
Combiner des groupes à haute disponibilité et des zones de disponibilité avec des groupes de placement de proximité
L’un des problèmes que présente l’utilisation de zones de disponibilité pour des déploiements de systèmes SAP est que vous ne pouvez pas déployer la couche Application SAP au moyen de groupes à haute disponibilité dans la zone de disponibilité spécifique. Vous souhaitez que la couche Application SAP soit déployée dans les mêmes zones que les machines virtuelles SAP ASCS/SCS. Le référencement d’une zone de disponibilité et d’un groupe à haute disponibilité pendant le déploiement d’une machine virtuelle n’est pas possible pour le moment. Cependant, par le simple fait de déployer une machine virtuelle qui demande une zone de disponibilité, vous ne pouvez plus vous assurer que les machines virtuelles de la couche application sont réparties sur des domaines de mise à jour et d’erreur différents.
En utilisant des groupes de placement de proximité, vous pouvez contourner cette restriction. Voici la séquence de déploiement :
- Créez un groupe de placement de proximité.
- Déployez votre machine virtuelle d’ancrage, recommandée comme machine virtuelle ASCS/SCS, en référençant une zone de disponibilité.
- Créez un groupe à haute disponibilité qui référence le groupe de placement de proximité Azure. (Voir la commande plus loin dans cet article.)
- Déployez les machines virtuelles de la couche Application en référençant le groupe à haute disponibilité et le groupe de placement de proximité.
Important
Il est important de comprendre que les disques des VM de la couche d’application ne sont pas garantis d’être alloués dans la même zone de disponibilité que celle vers laquelle les VM sont dirigées à l’aide du groupe de placement de proximité. Le résultat du déploiement présenté dans les étapes suivantes peut être que les VM sont allouées dans la même colonne vertébrale du réseau et, par conséquent, dans la même zone de disponibilité que la VM d’ancrage. Toutefois, les disques respectifs (disque dur virtuel de base et disques de stockage de blocs Azure montés) peuvent ne pas être alloués sous la même branche centrale réseau ou même dans la même zone de disponibilité. En revanche, les disques de ces machines virtuelles peuvent être alloués dans n’importe quel centre de données de la région concernée. Bien que les disques de la VM d’ancrage qui a été déployée en définissant une zone soient déployés dans la même zone que celle où la VM a été déployée, les disques de la VM d’ancrage sont déployés dans la même zone que celle où la VM a été déployée.
Au lieu de déployer la première machine virtuelle comme illustré dans la section précédente, vous référencez une zone de disponibilité et le groupe de placement de proximité lors du déploiement de la machine virtuelle :
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Un déploiement réussi de cette machine virtuelle hébergerait l’instance ASCS/SCS du système SAP dans une zone de disponibilité. Dans ce cas, la VM et le VHD de base de la VM et les disques de stockage en bloc Azure potentiellement montés sont alloués dans la même zone de disponibilité. L’étendue du groupe de placement de proximité est fixée à l’une des branches centrales réseau de la zone de disponibilité que vous avez définie.
À l’étape suivante, vous devez créer les groupes à haute disponibilité que vous voulez utiliser pour la couche Application de votre système SAP.
Définissez et créez le groupe de placement de proximité. La commande permettant de créer le groupe à haute disponibilité nécessite une référence supplémentaire à l’ID de groupe de placements de proximité (et non pas à son nom). Vous pouvez obtenir l’ID du groupe de placement de proximité à l’aide de cette commande :
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Quand vous créez le groupe à haute disponibilité, vous devez prendre en compte des paramètres supplémentaires lors de l’utilisation de disques managés (par défaut, sauf indication contraire) et des groupes de placement de proximité :
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
Dans l’idéal, vous devez utiliser trois domaines d’erreur. Toutefois, le nombre de domaines d’erreur pris en charge peut varier d’une région à l’autre. Dans ce cas, le nombre maximal de domaines d’erreur possibles pour les régions spécifiques est de deux. Pour déployer vos machines virtuelles de couche Application, vous devez ajouter une référence au nom de votre groupe à haute disponibilité et au nom du groupe de placement de proximité, comme indiqué ici :
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Remarque
Les disques des machines virtuelles déployées dans l’ensemble de disponibilité ci-dessus ne sont pas obligés d’être alloués dans la même zone de disponibilité que la machine virtuelle. Bien que vous ayez obtenu que les VM de la couche d’application soient réparties dans différents domaines de défaillance sous le même réseau que celui attribué à la VM d’ancrage, les disques, bien qu’également attribués dans différents domaines de défaillance, peuvent être alloués à différents endroits dans une région entière.
Le résultat de ce déploiement est le suivant :
- Les services centraux de votre système SAP situés dans une ou plusieurs zones de disponibilité spécifiques.
- Couche d’application SAP qui se trouve dans des groupes à haute disponibilité dans la même branche centrale réseau que la machine virtuelle ou les machines virtuelles SAP Central (ASCS/SCS).
Notes
Étant donné que vous déployez des machines virtuelles SGBD et ASCS/SCS dans une zone et d’autres machines de mêmes types dans une autre zone pour créer des configurations de haute disponibilité, vous aurez besoin d’un groupe de placement de proximité différent pour chacune des zones. Il en va de même pour tout groupe à haute disponibilité que vous utilisez.
Modifier les configurations de groupe de placement de proximité d’un système existant
Si vous avez implémenté des groupes de placement de proximité à partir des recommandations fournies jusqu’à présent, et que vous souhaitez vous adapter à la nouvelle configuration, vous pouvez le faire avec les méthodes décrites dans les articles suivants :
- Déployer des machines virtuelles dans des groupes de placements de proximité avec Azure CLI.
- Déployer des machines virtuelles dans des groupes de placements de proximité avec PowerShell.
Vous pouvez également utiliser ces commandes si vous obtenez des erreurs d’allocation quand vous ne pouvez pas changer le type VM d’une machine virtuelle existante dans le groupe de placement de proximité.
Groupe de machines virtuelles identiques avec une orchestration flexible
Pour éviter les limitations associées au groupe de placement de proximité, il est conseillé de déployer la charge de travail SAP à travers les zones de disponibilité en utilisant l’ensemble d’échelle flexible avec FD=1. Cette stratégie de déploiement garantit que les machines virtuelles déployées dans chaque zone ne sont pas limitées à un seul centre de données ou à un seul réseau, et que tous les composants du système SAP, tels que les bases de données, ASCS/ERS et le niveau d’application, sont répartis dans une zone. Tous les composants du système SAP étant répartis au niveau de la zone, la latence du réseau entre les différents composants d’un même système SAP doit être suffisante pour garantir un niveau de performance et un débit satisfaisants. Le principal avantage de cette nouvelle option de déploiement avec un jeu d’échelle flexible avec FD=1 est qu’elle offre une plus grande flexibilité dans le redimensionnement des VM ou le passage à de nouveaux types de VM pour toutes les couches du système SAP. En outre, le jeu d’échelle répartirait les VM entre plusieurs domaines de défaillance au sein d’une même zone, ce qui est idéal pour l’exécution de plusieurs VM du niveau d’application dans chaque zone. Pour plus d’informations, voir le jeu d’échelle de la machine virtuelle pour le document sur la charge de travail SAP.
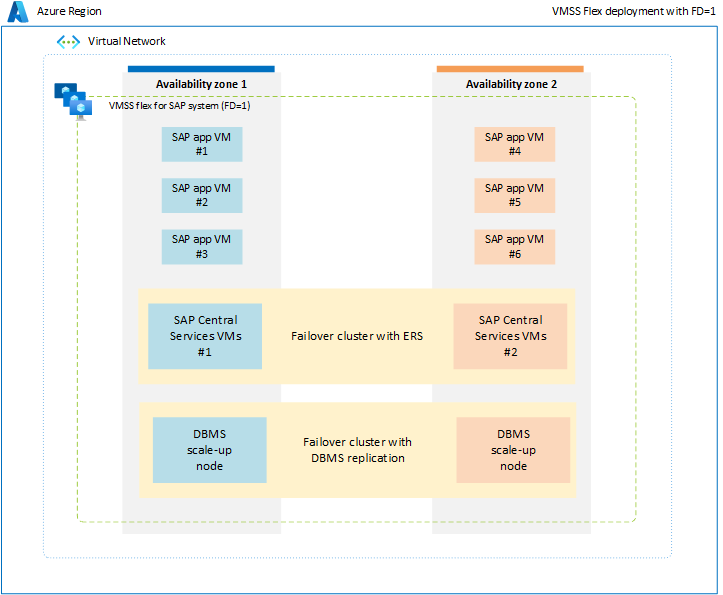
Dans un environnement de non-production ou de non-HA, il est possible de déployer tous les composants du système SAP, y compris la base de données, l’ASCS et le niveau d’application, au sein d’une seule zone en utilisant un jeu d’échelle flexible avec FD=1.
Options de déploiement précédemment recommandées
Cette section contient des détails sur les options de déploiement précédemment recommandées pour optimiser la latence réseau pour SAP. Avec les nouvelles fonctionnalités et la croissance d’Azure au fil du temps, les détails de cette section ne doivent être appliqués que dans de rares cas uniquement.
Groupes de placement de proximité pour l’ensemble du système SAP avec des déploiements zonaux
L’utilisation du groupe de placement de proximité que nous avons recommandée jusqu’à présent est illustrée dans ce graphique.

Vous créez un groupe de placement de proximité (PPG) dans chacune des deux zones de disponibilité dans lesquelles vous avez déployé votre système SAP. Toutes les machines virtuelles d’une zone particulière font partie du groupe de placement de proximité individuel de cette zone. Vous démarrez dans chaque zone avec le déploiement de la machine virtuelle SGBD pour étendre le PPG, puis vous déployez la machine virtuelle ASCS dans la même zone et dans le PPG. Dans une troisième étape, vous créez un groupe à haute disponibilité Azure, affectez le groupe à haute disponibilité au PPG étendu et déployez la couche d’application SAP dans celle-ci. Cette configuration avait pour avantage d’aligner parfaitement tous les composants sous la même branche centrale réseau. Le gros inconvénient réside dans le fait que la flexibilité du redimensionnement des machines virtuelles peut être limitée.
En s’appuyant sur de nombreuses améliorations déployées par Microsoft dans les régions Azure pour réduire la latence du réseau au sein d'une zone de disponibilité Azure, les actuelles directives de déploiement pour les déploiements zonaux de cet article existent.
Groupes de placement de proximité et grandes instances HANA
Si certains de vos systèmes SAP s’appuient sur de grandes instances HANA pour la couche Base de données, vous pouvez bénéficier d’améliorations importantes de la latence réseau entre l’unité de grandes instances HANA et les machines virtuelles Azure quand vous utilisez des unités de grandes instances HANA déployées dans des tampons ou lignes de la révision 4. L’une des améliorations est que les unités de grandes instances HANA, une fois déployées, sont déployées avec un groupe de placement de proximité. Vous pouvez utiliser ce groupe de placements de proximité pour déployer vos machines virtuelles de couche Application. Ainsi, ces machines virtuelles seront déployées dans le même centre de données que celui qui héberge votre unité de grandes instances HANA.
Pour déterminer si votre unité de grandes instances HANA est déployée dans un tampon ou une ligne de la révision 4, consultez l’article Contrôle des grandes instances Azure HANA à l’aide du portail Azure. Dans la vue d’ensemble des attributs de votre unité de grandes instances HANA, vous pouvez également déterminer le nom du groupe de placement de proximité car il a été créé au moment du déploiement de votre unité de grandes instances HANA. Le nom affiché dans la vue d’ensemble des attributs est le nom du groupe de placement de proximité dans lequel vous devez déployer vos machines virtuelles de couche Application.
Par rapport aux systèmes SAP qui utilisent uniquement des machines virtuelles Azure, quand vous utilisez de grandes instances HANA, vous disposez de moins de souplesse quant au nombre de groupes de ressources Azure à utiliser. Toutes les unités de grandes instances HANA d’un locataire de grandes instances HANA sont regroupées dans un seul groupe de ressources, comme décrit dans cet article. À moins d’effectuer un déploiement dans plusieurs locataires, par exemple pour séparer les systèmes de production et de non-production ou d’autres systèmes, toutes vos unités de grandes instances HANA seront déployées dans un locataire de grandes instances HANA. Ce locataire a une relation un-à-un avec un groupe de ressources. Toutefois, un groupe de placement de proximité distinct sera défini pour chacune des unités.
Ainsi, les relations entre les groupes de ressources Azure et les groupes de placement de proximité pour un même locataire seront les suivantes :

Étapes suivantes
Consultez la documentation :
- Check-list relative à la planification et au déploiement de la charge de travail SAP sur Azure
- Déployer des machines virtuelles dans des groupes de placements avec Azure CLI
- Déployer des machines virtuelles dans des groupes de placements avec PowerShell
- Facteurs à prendre en compte pour le déploiement SGBD des machines virtuelles Azure pour la charge de travail SAP