Rechercher dans le contenu Stockage Blob Azure
La recherche dans les différents types de contenu stockés dans Stockage Blob Azure peut être un problème difficile à résoudre, mais Recherche Azure AI fournit une intégration profonde au niveau de la couche de contenu, en extrayant et en déduisant des informations textuelles, qui peuvent ensuite être interrogées dans un index de recherche.
Cet article examine le flux de travail de base pour l’extraction de contenu et de métadonnées de blobs et leur envoi à un index de recherche dans le service Recherche Azure AI. L’index obtenu peut être interrogé à l’aide d’une recherche en texte intégral. Vous pouvez éventuellement envoyer le contenu du blob traité à une base de connaissances pour des scénarios autres que la recherche.
Remarque
Vous êtes déjà familiarisé avec le flux de travail et la composition ? Votre prochaine étape est de configurer un indexeur de blobs.
Implications de l’ajout de la recherche en texte intégral aux données blob
Recherche Azure AI est un service de recherche autonome qui prend en charge les charges de travail d’indexation et d’interrogation sur des index définis par l’utilisateur qui contiennent votre contenu privé qui peut être recherché et qui est hébergé dans le cloud. Colocaliser votre contenu recherchable avec le moteur de requête dans le cloud est une nécessité pour offrir aux utilisateurs les performances qu’ils attendent eu égard au délai d’affichage des résultats des requêtes de recherche.
Recherche Azure AI s’intègre avec Stockage Blog Azure au niveau de la couche d’indexation. Le contenu de vos objets blob est ainsi importé sous forme de documents de recherche indexés dans des index inversés et d’autres structures de requête qui prennent en charge les requêtes de texte en forme libre et les expressions de filtre. Le contenu de votre blob étant indexé dans un index de recherche, vous pouvez utiliser la panoplie complète des fonctionnalités de requête du service Recherche Azure AI pour trouver des informations dans le contenu de votre blob.
Les entrées sont vos objets blob, dans un même conteneur, dans Stockage Blob Azure. Les objets blob peuvent correspondre à pratiquement tout type de données texte. Si vos blobs contiennent des images, vous pouvez ajouter l’enrichissement par IA pour créer et extraire du texte et des caractéristiques à partir des images.
La sortie est toujours un index Recherche Azure AI, utilisé pour la recherche, l’extraction et l’exploration rapides de texte dans les applications clientes. Au milieu se trouve l’architecture proprement dite du pipeline d’indexation. Le pipeline est basé sur la fonctionnalité d’indexeur, décrite plus loin dans cet article.
Une fois créé et rempli, l’index existe indépendamment de votre conteneur d’objets blob. Vous pouvez néanmoins réexécuter les opérations d’indexation de façon à actualiser l’index sur la base des documents modifiés. Les informations d’horodatage des différents objets blob servent à détecter les modifications. Vous pouvez opter pour une exécution planifiée ou une indexation à la demande en guise de mécanisme d’actualisation.
Ressources utilisées dans une solution de recherche de blob
Vous avez besoin de la Recherche Azure AI, du Stockage Blob Azure et d’un client. La Recherche Azure AI est généralement l’un des nombreux composants d’une solution, où votre code d’application envoie des demandes d’API de requête et traite la réponse. Vous pouvez également écrire du code d’application pour traiter l’indexation. Toutefois, pour les tests de validation technique et les tâches impromptues, il est courant d’utiliser le portail Azure comme client de recherche.
Dans le Stockage Blob, vous avez besoin d’un conteneur qui fournit le contenu source. Vous pouvez définir des critères d’inclusion et d’exclusion de fichier, et spécifier les parties d’un blob à indexer dans la Recherche Azure AI.
Vous pouvez commencer directement dans la page du portail de votre compte de stockage.
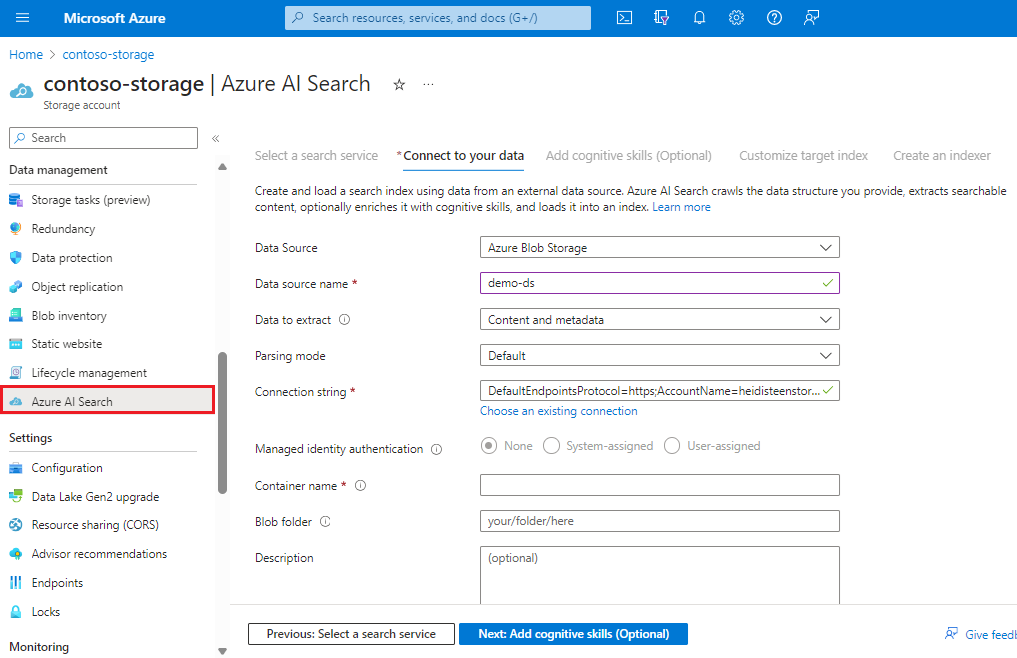
Dans la page de navigation de gauche, sous Gestion des données, sélectionnez Recherche Azure AI pour sélectionner ou créer un service de recherche.
Suivez les étapes de l’Assistant pour extraire et éventuellement créer du contenu pouvant faire l’objet d’une recherche à partir de vos blobs. Le flux de travail est l’Assistant Importation de données. Le flux de travail crée un indexeur, une source de données, un index et un ensemble d’options de compétences sur votre service Recherche Azure AI.
Utilisez Navigateur de recherche dans la page du portail de recherche pour interroger votre contenu.
L’Assistant est le meilleur point de départ, mais vous découvrirez des options plus flexibles en configurant un indexeur de blobs vous-même. Vous pouvez utiliser un client REST. Tutoriel : Indexer et rechercher des données semi-structurées (blobs JSON) vous guide tout au long des étapes d’appel de l’API REST.
Comment les blobs sont indexés
Par défaut, la plupart des objets blob sont indexés en tant que document de recherche unique dans l’index, y compris les objets blob avec un contenu structuré, par exemple au format JSON ou CSV, qui sont indexés en tant que bloc de texte unique. Toutefois, si les documents JSON ou CSV ont une structure interne (délimiteurs), vous pouvez assigner des modes d’analyse pour générer des documents de recherche individuels pour chaque ligne ou élément :
Un document composé ou incorporé (comme une archive ZIP, un document Word avec un e-mail Outlook incorporé intégrant des pièces jointes ou un fichier .MSG avec des pièces jointes) est également indexé comme un seul document. Par exemple, toutes les images extraites des pièces jointes d’un fichier .MSG seront renvoyées dans le champ normalized_images. Si vous avez des images, pensez à ajouter l’enrichissement par IA pour que ce contenu soit plus utile aux recherches.
Le contenu textuel d’un document est extrait dans un champ de type chaîne nommé « content ». Vous pouvez également extraire les métadonnées standard et définies par l’utilisateur.
Remarque
Recherche Azure AI impose des limites d’indexeur quant à la quantité de texte qu’il extrait en fonction du niveau tarifaire. Un avertissement s’affiche dans la réponse d’état de l’indexeur si les documents sont tronqués.
Utiliser un indexeur de blobs pour l’extraction de contenu
Un indexeur est un sous-service qui reconnaît les sources de données dans Recherche Azure AI. Avec sa logique interne, il échantillonne les données, lit et extrait les données et les métadonnées et les sérialise dans des documents JSON à partir de formats natifs en vue d’une importation ultérieure.
Les blobs dans le service Stockage Azure sont indexés à l’aide de l’indexeur de blobs. Vous pouvez invoquer cet indexeur en utilisant la commande Recherche Azure AI dans le Stockage Azure, l’Assistant Importation de données, une API REST ou le Kit de développement logiciel (SDK) .NET. Dans le code, vous pouvez utiliser cet indexeur en définissant le type et en fournissant des informations de connexion qui incluent un compte Stockage Azure associé à un conteneur d’objets blob. Vous pouvez créer un sous-ensemble de vos objets blob en créant un répertoire virtuel, que vous pouvez ensuite transmettre comme paramètre, ou en filtrant sur une extension de type de fichier.
Un indexeur effectue le « craquage de document » en ouvrant un objet blob pour en inspecter le contenu. Une fois connecté à la source de données, il s’agit de la première étape du pipeline. Pour les données blob, c’est à ce stade que les fichiers PDF, les documents Office et d’autres types de contenu sont détectés. Le craquage de document avec extraction de texte n’est pas facturé. Si vos objets blob contiennent des images, celles-ci sont ignorées si vous n’ajoutez pas l’enrichissement par IA. L’indexation standard s’applique uniquement au contenu texte.
L’indexeur de blobs Azure intègre des paramètres de configuration et prend en charge le suivi des modifications si les données sous-jacentes fournissent suffisamment d’informations. Vous trouverez des informations supplémentaires sur la fonctionnalité de base dans Indexer des données à partir du Stockage Blob Azure.
Niveaux d’accès pris en charge
Les niveaux d’accès au service Stockage Blob sont chaud, sporadique, froid et archive. Les indexeurs peuvent récupérer des objets blob sur les niveaux d’accès chaud, sporadique et froid.
Types de contenu pris en charge
En exécutant un indexeur de blobs sur un conteneur, vous pouvez extraire du texte et des métadonnées à partir des types de contenu suivants avec une seule requête :
- CSV (consultez Indexation d’objets blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (consultez l’indexation d’objets JSON blobs)
- KML (XML pour les représentations géographiques)
- Formats Microsoft Office : DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (e-mails Outlook), XML (XML WORD 2003 et 2006)
- Formats de document ouverts : ODT, ODS, ODP
- Fichiers de texte brut (voir aussi l’indexation de texte brut)
- RTF
- XML
- ZIP
Contrôle les objets blob indexés
Vous pouvez contrôler quels blobs sont indexés, et lesquels sont ignorés, par le type de fichier du blob ou en définissant des propriétés sur le blob proprement dit, ce qui fait que l’indexeur les ignore.
Incluez des extensions de fichiers spécifiques en définissant "indexedFileNameExtensions" sur une liste d’extensions de fichier séparées par des virgules (avec un point au début). Excluez des extensions de fichiers spécifiques en définissant "excludedFileNameExtensions" sur les extensions qui doivent être ignorées. Si la même extension figure dans les deux listes, elle est exclue de l’indexation.
PUT /indexers/[indexer name]?api-version=2024-07-01
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Ajouter une fonctionnalité « ignorer » des métadonnées au blob
Les paramètres de configuration de l’indexeur s’appliquent à tous les blobs du conteneur ou du dossier. Parfois, vous souhaitez contrôler la manière dont différents blobs sont indexés.
Ajoutez les propriétés et valeurs de métadonnées suivantes aux blobs dans Stockage Blob. Lorsque l’indexeur rencontre ces propriétés, il ignore le blob ou son contenu dans l’exécution de l’indexation.
| Nom de la propriété | Valeur de la propriété | Explication |
|---|---|---|
| "AzureSearch_Skip" | "true" |
Indique à l’indexeur d’objets blob d’ignorer complètement l’objet blob. Ni l’extraction des métadonnées, ni l’extraction de contenu n’est tentée. Cette propriété est utile lorsqu’un objet blob spécifique échoue à plusieurs reprises et interrompt le processus d’indexation. |
| "AzureSearch_SkipContent" | "true" |
Ceci est équivalent au paramètre "dataToExtract" : "allMetadata" décrit ci-dessus délimité à un objet blob particulier. |
Indexation de métadonnées blob
Pour faciliter le tri des blobs constitués de tout type de contenu, un scénario courant consiste à indexer les métadonnées personnalisées et les propriétés système pour chaque blob. De cette façon, les informations de tous les objets blob sont indexées indépendamment du type de document et stockées dans un index de votre service de recherche. Le nouvel index vous permet alors d’effectuer un tri, un filtrage et une facette dans l’ensemble du contenu du stockage Blob.
Remarque
Les balises d’index d’objet blob sont indexées en mode natif par le service de stockage d’objets blob et exposées pour l’interrogation. Si les attributs clé/valeur de vos objets blob nécessitent des fonctionnalités d’indexation et de filtrage, les balises d’index d’objet blob doivent être exploitées à la place des métadonnées.
Pour en savoir plus sur un index d’objets blob, consultez Gérer et rechercher des données sur le Stockage Blob Azure avec un index d’objets blob.
Rechercher du contenu d’objet blob dans un index de recherche
La sortie d’un indexeur est un index de recherche, qui permet une exploration interactive à l’aide de requêtes de texte libre et filtrées dans une application cliente. Pour une exploration et une vérification initiales de contenu, nous vous recommandons de commencer avec l’Explorateur de recherche sur le portail, qui vous permet d’examiner la structure du document. Dans l’Explorateur de recherche, vous pouvez utiliser les éléments suivants :
Une solution plus permanente consiste à regrouper les entrées de requête et à présenter la réponse sous forme de résultats de recherche dans une application cliente. Le didacticiel C# suivant explique comment créer une application de recherche : Ajouter une recherche à une application ASP.NET Core (MVC).