Estimer et gérer la capacité d’un service de recherche
Dans Recherche Azure AI, la capacité est basée sur des réplicas et des partitions qui peuvent être mis à l’échelle vers votre charge de travail. Les réplicas sont des copies du moteur de recherche. Les partitions sont des unités de stockage. Au début, chaque nouveau service de recherche en dispose d’une, mais vous pouvez ajouter ou supprimer des réplicas et des partitions indépendamment pour prendre en charge les charges de travail fluctuantes. L’ajout de capacité augmente le coût d’exécution d’un service de recherche.
Les caractéristiques physiques des réplicas et des partitions, par exemple la vitesse de traitement et les E/S de disque, varient en fonction du niveau de service. Sur un service de recherche standard, les réplicas et les partitions sont plus rapides et supérieurs à ceux d’un service de base.
Le changement de capacité n’est pas instantané. L’activation ou la désactivation des partitions peut prendre jusqu’à une heure, en particulier pour les services comportant de grandes quantités de données.
Durant la mise à l’échelle d’un service de recherche, vous avez le choix entre les approches et les outils suivants :
Remarque
Des partitions de capacité plus élevées sont disponibles au même tarif de facturation sur les services plus récents créés après avril et mai 2024. Pour plus d’informations, consultez Limites de service pour les mises à niveau de la taille des partitions.
Concepts : unités de recherche, réplicas, partitions
La capacité est exprimée en unités de recherche qui peuvent être allouées en supplément des partitions et des replica.
| Concept | Définition |
|---|---|
| Unité de recherche | Incrément unique de la capacité disponible totale (36 unités). Le service a besoin au minimum d’une unité pour s’exécuter. La première paire réplica/partition est la première unité de recherche. Toutefois, chaque instance supplémentaire d’un réplica ou d’une partition consomme une unité de recherche supplémentaire. Par exemple, si vous commencez avec un réplica et une partition (une unité de recherche) et que vous ajoutez un deuxième réplica, vous consommez maintenant deux unités de recherche. Une unité de recherche est également l’unité de facturation pour un service Recherche Azure AI. |
| Réplica | Instances du service de recherche, principalement utilisées pour équilibrer la charge des opérations de requête. Chaque réplica héberge une copie d’un index. Si vous allouez trois réplicas, vous avez trois copies d’un index disponibles pour traiter les demandes de requête. |
| Partition | Stockage physique et E/S pour les opérations de lecture/écriture (par exemple, pendant la reconstruction ou l’actualisation d’un index). Chaque partition contient une section de l’index total. Si vous allouez trois partitions, l’index est divisé en trois. |
Passez en revue la table des partitions et des réplicas pour connaître les combinaisons possibles qui restent sous la limite de 36 unités.
Moment opportun pour ajouter de la capacité
Au départ, un service se voit allouer un niveau minimal de ressources consistant en une partition et un réplica. Le niveau que vous choisissez détermine la taille et la vitesse des partitions, et chaque niveau est optimisé par rapport à un ensemble de caractéristiques adaptées à différents scénarios. Si vous choisissez un niveau supérieur, vous aurez peut-être besoin de moins de partitions que si vous optez pour le niveau S1. L’une des questions auxquelles vous devrez répondre au moyen de tests autonomes est de savoir si une partition plus grande et plus coûteuse offre de meilleures performances que deux partitions moins chères sur un service provisionné à un niveau inférieur.
Un seul service doit avoir suffisamment de ressources pour gérer toutes les charges de travail (indexation et requêtes). Aucune charge de travail ne s’exécute en arrière-plan. Vous pouvez planifier l’indexation à des moments où les demandes de requête sont naturellement moins fréquentes, mais à part cela, le service n’établit pas de priorité entre les tâches. De plus, un certain degré de redondance lisse les performances des requêtes lorsque les services ou les nœuds sont mis à jour en interne.
Voici quelques conseils pour déterminer s’il convient d’ajouter de la capacité :
- Respect des critères de haute disponibilité pour le contrat de niveau de service
- La fréquence des erreurs HTTP 503 augmente
- Des volumes de requêtes volumineux sont attendus
En règle générale, les applications de recherche tendent à avoir besoin de plus de réplicas que de partitions, en particulier lorsque les opérations de service favorisent les charges de travail de requête. Chaque réplica est une copie de votre index, ce qui permet au service d’équilibrer la charge des requêtes sur plusieurs copies. L’équilibrage de la charge et la réplication d’un index sont entièrement gérés par la Recherche Azure AI, mais vous pouvez à tout moment changer le nombre de réplicas alloués à votre service. Vous pouvez allouer jusqu'à 12 réplicas dans un service de recherche Standard, et 3 dans un service de recherche de base. L’allocation de réplicas peut s’effectuer à partir du portail Azure ou de l’une des options de programmation.
Les partitions supplémentaires sont utiles pour les charges de travail d’indexation intensives. Des partitions supplémentaires répartissent les opérations de lecture/écriture sur un plus grand nombre de ressources de calcul.
Enfin, plus les index sont grands, plus ils sont longs à interroger. Par conséquent, peut-être constaterez-vous que chaque augmentation incrémentielle des partitions nécessite une augmentation plus faible mais proportionnelle des réplicas. La complexité et le volume de vos requêtes auront une incidence sur la vitesse d’exécution des requêtes.
Remarque
L’ajout de réplicas ou de partitions augmente le coût d’exécution du service et peut introduire de légères variations dans la façon dont les résultats sont classés. N’oubliez pas d’utiliser la calculatrice de prix pour bien comprendre l’impact de l’ajout de nœuds supplémentaires sur votre facturation. Le graphique ci-dessous peut vous aider à déterminer le nombre d’unités de recherche requises pour une configuration spécifique. Pour plus d’informations sur l’impact des réplicas supplémentaires sur le traitement des requêtes, consultez Classement des résultats.
Comment modifier la capacité
Pour augmenter ou diminuer la capacité de votre service de recherche, ajoutez ou supprimez des partitions et des réplicas.
Connectez-vous au portail Azure, puis sélectionnez le service de recherche.
Sous Paramètres, ouvrez la page Mise à l’échelle pour modifier les réplicas et partitions.
La capture d’écran suivante montre un service approvisionné standard avec un réplica et une partition. La formule en bas indique combien d’unités de recherche sont utilisées (1). Si le prix unitaire était de 100 (prix fictif), le coût mensuel de l’exécution de ce service serait de 100 en moyenne.
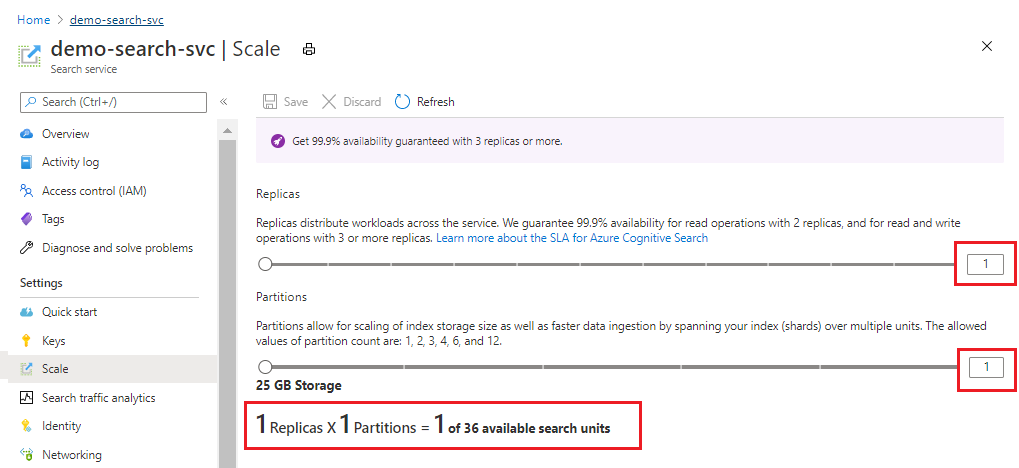
Utilisez le curseur pour augmenter ou diminuer le nombre de partitions. Cliquez sur Enregistrer.
Cet exemple ajoute un deuxième réplica et une autre partition. Notez le nombre d’unités de recherche. Il est désormais de quatre, car la formule de facturation multiplie le nombre de réplicas par le nombre de partitions (2 x 2). Le doublement de la capacité fait plus que doubler le coût de l’exécution du service. Si le coût d’une unité de recherche était de 100, la nouvelle facture mensuelle serait désormais de 400.
Pour le coût unitaire de chaque niveau, visitez la page Tarification.
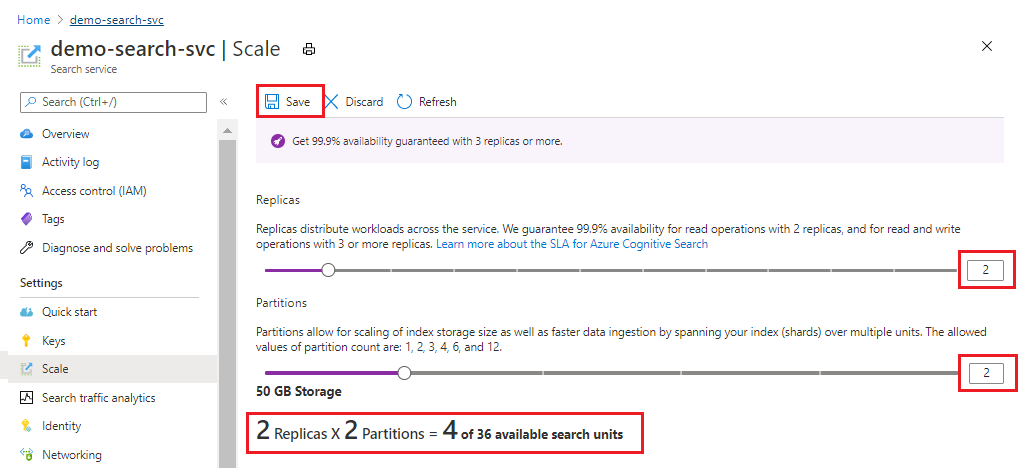
Après l’enregistrement, vous pouvez vérifier les notifications pour confirmer que l’action a réussi.
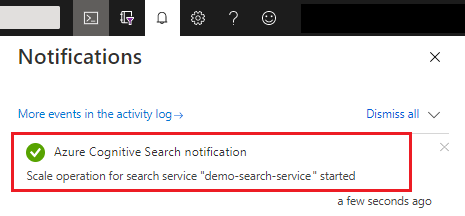
La prise d’effet des changements de capacité peut nécessiter de 15 minutes à quelques heures. Une fois que le processus a démarré, vous ne pouvez pas l’annuler, et il n’y a pas de supervision en temps réel des ajustements de réplicas et de partitions. Toutefois, le message suivant reste visible pendant que les changements prennent effet.

Remarque
Une fois qu’un service a été provisionné, il ne peut pas être mis à niveau vers un niveau supérieur. Vous devez créer un service de recherche au nouveau niveau et recharger vos index. Pour obtenir des instructions sur l’approvisionnement du service, voir Créer un service Recherche Azure AI dans le portail.
Gestion des requêtes de mise à l’échelle
Quand une requête de mise à l’échelle est reçue, le service de recherche :
- Vérifie si la requête est valide.
- Démarre la sauvegarde des données et des informations système.
- Vérifie si le service est déjà dans un état de provisionnement (ajout ou suppression de réplicas ou de partitions).
- Démarre le provisionnement.
La mise à l’échelle d’un service peut prendre dans les 15 minutes ou bien plus d’une heure, selon la taille du service et l’étendue de la requête. La sauvegarde peut prendre plusieurs minutes, en fonction de la quantité de données et du nombre de partitions et de réplicas.
Les étapes ci-dessus ne sont pas entièrement consécutives. Par exemple, le système démarre le provisionnement quand il peut le faire de manière sécurisée, ce qui peut avoir lieu au moment où la sauvegarde s’achève.
Erreurs durant la mise à l’échelle
Le message d’erreur « Les opérations de mise à jour du service ne sont pas autorisées pour le moment, car nous traitons déjà une requête » est provoqué par la répétition d’une requête de scale-down ou de scale-up alors que le service traite déjà une requête.
Résolvez cette erreur en consultant l’état du service pour vérifier l’état du provisionnement :
- Utilisez l’API REST de gestion, Azure PowerShell ou Azure CLI pour obtenir l’état du service.
- Appelez Obtenir le service (REST) ou équivalent pour PowerShell ou l’interface CLI.
- Vérifiez la réponse pour "provisioningState": "provisioning"
Si l’état est « Provisioning », attendez la fin de la requête. L’état doit être "Succeeded" ou "Failed" avant qu’une autre requête ne soit tentée. Il n’existe aucun état pour la sauvegarde. La sauvegarde est une opération interne. Il est peu probable qu’elle soit un facteur disruptif dans un exercice de mise à l’échelle.
Si votre service de recherche semble bloqué dans un état d’approvisionnement, recherchez les index orphelins inutilisables, avec zéro volume de requête et aucune mise à jour d’index. Un index inutilisable peut bloquer les modifications apportées à la capacité de service. En particulier, recherchez les index qui sont chiffrés par CMK, dont les clés ne sont plus valides. Vous devez supprimer l’index ou restaurer les clés pour rétablir l’index en ligne et débloquer votre opération de mise à l’échelle.
combinaisons de partitions et de réplicas
Le graphique suivant s’applique au niveau Standard et supérieur. Il affiche toutes les combinaisons possibles de partitions et de réplicas, soumises au maximum de 36 unités de recherche par service.
| 1 partition | 2 partitions | 3 partitions | 4 partitions | 6 partitions | 12 partitions | |
|---|---|---|---|---|---|---|
| 1 réplica | 1 unité de diffusion en continu | 2 unités de recherche | 3 unités de recherche | 4 unités de recherche | 6 unités de recherche | 12 unités de recherche |
| 2 réplicas | 2 unités de recherche | 4 unités de recherche | 6 unités de recherche | 8 unités de recherche | 12 unités de recherche | 24 unités de recherche |
| 3 réplicas | 3 unités de recherche | 6 unités de recherche | 9 unités de recherche | 12 unités de recherche | 18 unités de recherche | 36 unités de recherche |
| 4 réplicas | 4 unités de recherche | 8 unités de recherche | 12 unités de recherche | 16 unités de recherche | 24 unités de recherche | N/A |
| 5 réplicas | 5 unités de recherche | 10 unités de recherche | 15 unités de recherche | 20 unités de recherche | 30 unités de recherche | N/A |
| 6 réplicas | 6 unités de recherche | 12 unités de recherche | 18 unités de recherche | 24 unités de recherche | 36 unités de recherche | N/A |
| 12 réplicas | 12 unités de recherche | 24 unités de recherche | 36 unités de recherche | N/A | N/A | N/A |
Les services de recherche Essentiel ont des nombres d’unités de recherche inférieurs.
Sur les services de recherche créés avant le 3 avril 2024, le service de recherche de base peut avoir exactement une partition et jusqu’à trois réplicas, pour une limite maximale de trois unités de stockage (SU). Les seules ressources ajustables sont les réplicas.
Sur les services de recherche créés après le 3 avril 2024 dans les régions prises en charge, les services de base peuvent avoir jusqu’à trois partitions et trois réplicas. La limite maximale d’unités de stockage (SU) est de neuf pour prendre en charge un ensemble complet de partitions et de réplicas.
Pour les services de recherche de tout niveau facturable, quelle que soit la date de création, vous avez besoin d’au moins deux réplicas pour assurer la haute disponibilité des requêtes.
Pour connaître les tarifs de facturation par niveau et par devise, consultez la Page de tarification de Recherche Azure AI.
Estimer la capacité à l’aide d’un niveau facturable
Les besoins de stockage dépendent de la taille des index que vous prévoyez de générer. Il n’existe pas d’euristique solide ou de généralités qui facilitent les estimations. La seule façon de déterminer la taille d’un index est d’en créer un. Sa taille est basée sur la segmentation du texte en unités lexicales et les incorporations, mais également l’activation des suggesteurs, du filtrage et du tri, ou peut tirer profit de la compression vectorielle.
Nous vous recommandons de procéder à l’estimation d’un niveau facturable, Essentiel ou supérieur. Le niveau Gratuit s’exécute sur des ressources physiques partagées par plusieurs clients et il est soumis à des facteurs qui vous échappent. Seules des ressources dédiées de service de recherche facturable peuvent prendre en charge un échantillonnage et des temps de traitement plus conséquents pour produire des estimations plus réalistes de quantité d’index, de taille et de volume de requête durant le développement.
Passez en revue les limites de service de chaque niveau afin de déterminer si les niveaux inférieurs peuvent prendre en charge le nombre d’index dont vous avez besoin. Déterminez votre besoin en copies d’un index pour des environnements actifs de développement, de test et de production.
Un service de recherche est soumis à des limites de nombre d’objets (nombre maximal d’index, d’indexeurs, d’ensembles de compétences, etc.) et des limites de stockage. Quelle que soit la limite atteinte en premier, c’est la limite effective.
Créez un service à un niveau facturable. Niveaux optimisés pour certaines charges de travail. Le niveau de stockage optimisé présente par exemple une limite de 10 index, car il a été conçu pour prendre en charge un petit nombre d’index très volumineux.
Si vous n’êtes pas sûr de la charge projetée, commencez modestement, au niveau De base ou S1.
Commencez à un niveau élevé, à S2 ou même S3, si les tests comprennent des charges d’interrogation et d’indexation à grande échelle.
Enfin, si vous indexez une grande quantité de données et que la charge de requêtes est relativement faible, comme dans le cas d’une application métier interne, commencez par le niveau À stockage optimisé L1 ou L2.
Générez un index initial pour déterminer comment les données sources se traduisent par un index. C’est l’unique façon d’estimer la taille de l’index. Les attributs des définitions de champ affectent les exigences de la mémoire physique :
Pour la recherche par mot clé, le marquage des champs comme filtrables et pouvant être triés augmente la taille de l’index.
Pour la recherche vectorielle, vous pouvez définir des paramètres pour réduire le stockage.
Surveillez le stockage, les limites de service, le volume de requêtes et la latence dans le portail. Le portail vous indique le nombre de requêtes par seconde, les requêtes limitées et la latence de recherche. Toutes ces valeurs peuvent vous aider à décider si vous avez sélectionné le niveau adéquat.
Ajoutez des réplicas pour une haute disponibilité ou pour atténuer les contre-performances des requêtes lentes.
Il n’existe aucune instruction sur le nombre de réplicas nécessaires pour prendre en charge les charges d’interrogation. Les performances des requêtes dépendent de la complexité des requêtes et des charges de travail concurrentes. Bien que l’ajout de réplicas entraîne clairement une amélioration de l’évolutivité et des performances, le résultat final n’est pas strictement linéaire : si vous ajoutez trois réplicas, le débit n’est pas forcément multiplié par trois. Pour obtenir de l’aide sur l’estimation du nombre de requêtes par seconde (RPS) pour votre solution, consultez Analyser les performances et Superviser les requêtes.
Dans le cas d’un index inversé, la taille et la complexité sont déterminées par le contenu, nécessairement pas par la quantité de données qui l’alimentent. Une source de données volumineuse avec un haut niveau de redondance peut générer un index plus restreint qu’un jeu de données plus modeste présentant un contenu extrêmement variable. Il est donc généralement impossible de déduire la taille de l’index d’après celle du jeu de données d’origine.
Les exigences en matière de stockage peuvent être gonflées si vous incluez des données qui ne seront jamais recherchées. Dans l’idéal, les documents contiennent uniquement les données dont vous avez besoin pour l’expérience de recherche.
Considérations liées au contrat de niveau de service
Le niveau Gratuit et les fonctionnalités d’évaluation ne sont pas couverts par des Contrats de niveau de service (SLA). Pour tous les niveaux facturables, les SLA entrent en vigueur lorsque vous approvisionnez une redondance suffisante pour votre service.
Au moins deux réplicas répondent aux contrats SLA de requête (lecture).
Un SLA de requête et d’indexation (lecture-écriture) nécessite au moins trois réplicas.
Le nombre de partitions n’affecte pas les SLA.