Recherche en texte intégral dans Azure AI Search
La recherche en texte intégral est une approche de la récupération des informations qui établit une correspondance au contenu en texte brut stocké dans un index. Par exemple, à partir d’une chaîne de requête « hôtels à San Diego sur la plage », le moteur de recherche cherche des chaînes tokenisées basées ces termes. Pour rendre les analyses plus efficaces, les chaînes de requête subissent une analyse lexicale : casse inférieure de tous les termes, suppression de mots vides comme « le/la/de/du/ce » et réduction des termes aux formes racines primitives. Lorsque des termes correspondants sont trouvés, le moteur de recherche récupère les documents, les classe dans l’ordre de pertinence et retourne les premiers résultats.
L’exécution des requêtes peut être complexe. Cet article est destiné aux développeurs qui ont besoin d’une compréhension plus approfondie du fonctionnement de la recherche en texte intégral dans Azure AI Search. Pour les requêtes de texte, Azure AI Search fournit en toute transparence des résultats attendus dans la plupart des scénarios, mais parfois, vous pouvez obtenir un résultat qui semble d’une certaine façon « inexactes ». Dans ce cas, le fait d’avoir une connaissance des quatre phases d’exécution des requêtes Lucene (analyse des requêtes, analyse lexicale, mise en correspondance des documents et notation) peut vous permettre d’identifier les modifications spécifiques des paramètres de requête ou de la configuration d’index qui permettront d’obtenir le résultat souhaité.
Remarque
Azure AI Search utilise Apache Lucene pour la recherche en texte intégral, mais l’intégration Lucene n’est pas exhaustive. Nous exposons et étendons la fonctionnalité Lucene de façon sélective pour activer les scénarios importants dans Azure AI Search.
Présentation et diagramme de l’architecture
L’exécution des requêtes comporte quatre étapes :
- Analyse des requêtes
- Analyse lexicale
- Extraction de documents
- Notation
Une requête de recherche en texte intégral commence par l’analyse du texte de la requête pour en extraire les termes de recherche et les opérateurs. Il existe deux analyseurs syntaxiques, ce qui vous permet de choisir entre rapidité et complexité. Une phase d’analyse est suivante, où les termes de requête individuels sont parfois décomposés et reconstitués dans de nouvelles formes. Cette étape permet de convertir un filet plus large sur ce qui pourrait être considéré comme une correspondance potentielle. Le moteur de recherche parcourt ensuite l’index pour rechercher les documents contenant des correspondances et attribue un score à chacune d’elles. Le jeu de résultats est ensuite trié en fonction d’un score de pertinence attribué à chaque document individuel correspondant. Les premiers résultats de la liste ordonnée sont renvoyés à l’application appelante.
Le diagramme ci-dessous illustre les composants utilisés pour traiter une demande de recherche.
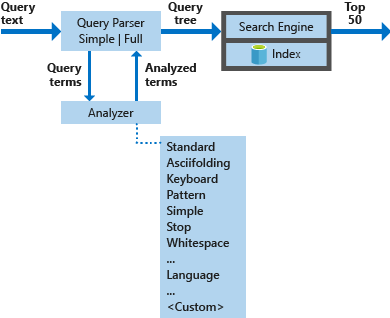
| Composants clés | Description fonctionnelle |
|---|---|
| Analyseurs de requêtes | Distinguez les termes de requête des opérateurs de requête et créez la structure de la requête (arborescence de requête) à envoyer au moteur de recherche. |
| Analyseurs | Effectuez une analyse lexicale sur les termes de requête. Ce processus peut impliquer la transformation, la suppression ou le développement des termes de requête. |
| Index | Structure de données efficace permettant de stocker et d’organiser les termes pouvant faire l’objet d’une recherche extraits à partir de documents indexés. |
| Moteur de recherche | Extrait et évalue les documents correspondants en fonction du contenu de l’index inversé. |
Anatomie d’une requête de recherche
Une requête de recherche est une spécification complète de ce qui doit être renvoyé dans un jeu de résultats. Dans sa forme la plus simple, il s’agit d’une requête vide sans aucun critère. Un exemple plus réaliste inclut des paramètres, plusieurs termes de requête, peut-être limités à certains champs, avec éventuellement une expression de filtre et des règles de classement.
L’exemple suivant est une requête de recherche que vous pourriez envoyer à Azure AI Search à l’aide de l’API REST.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Pour cette requête, le moteur de recherche effectue les opérations suivantes :
Recherche des documents où le prix est d’au moins 60 $ et inférieur à 300 $.
Exécute la requête. Dans cet exemple, la requête de recherche se compose d’expressions et de termes :
"Spacious, air-condition* +\"Ocean view\""(en général, les utilisateurs n’entrent pas de ponctuation, mais l’inclure dans l’exemple nous permet d’expliquer la manière dont les analyseurs la traite).Pour cette requête, le moteur de recherche parcourt les champs Description et Titre spécifiés dans « searchFields » à la recherche de documents qui contiennent
"Ocean view", mais également le terme"spacious", ou les termes qui commencent par le préfixe"air-condition". Le paramètre « searchMode » permet d’effectuer une recherche sur n’importe quel terme (valeur par défaut) ou sur tous les termes, dans les cas où un terme n’est pas explicitement requis (+).Classe l’ensemble d’hôtels résultant en fonction de leur proximité par rapport à un emplacement géographique donné, puis renvoie les résultats à l’application appelante.
La majeure partie de cet article porte sur le traitement de la requête de recherche : "Spacious, air-condition* +\"Ocean view\"". Le filtrage et le tri ne sont pas abordés. Pour plus d’informations, voir Documentation de référence sur l’API de recherche.
Étape 1 : Analyse des requêtes
Comme indiqué, la chaîne de requête constitue la première ligne de la requête :
"search": "Spacious, air-condition* +\"Ocean view\"",
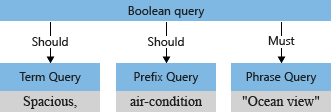
L’analyseur de requêtes distingue les opérateurs (tels que * et + dans l’exemple) des termes de recherche et décompose la requête de recherche en sous-requêtes d’un type pris en charge :
- requête de terme pour les termes autonomes (comme spacieux)
- requête d’expression pour les termes entre guillemets (comme vue mer)
- requête de préfixe pour les termes suivis d’un opérateur de préfixe
*(comme air condition)
Pour obtenir la liste complète des types de requêtes pris en charge, consultez syntaxe de requête Lucene
Les opérateurs associés à une sous-requête déterminent si la requête « doit être » ou « peut être » satisfaite pour qu’un document soit considéré comme correspondant. Par exemple, +"Ocean view" indique que la requête « doit être » satisfaite en raison de l’opérateur +.
L’analyseur de requêtes restructure les sous-requêtes en une arborescence de requête (structure interne représentant la requête) qu’il transmet au moteur de recherche. Dans la première étape d’analyse de la requête, l’arborescence de requête ressemble à ceci.
Analyseurs pris en charge : simple et complet (Lucene)
Azure AI Search expose deux langages de requête différents, simple (valeur par défaut) et full. En définissant le paramètre queryType avec votre requête de recherche, vous indiquez à l’analyseur de requêtes le langage de requête choisi afin qu’il sache comment interpréter les opérateurs et la syntaxe.
Le langage de requête simple est intuitif et robuste, généralement adapté à l’interprétation de l’entrée d’utilisateur telle quelle, sans traitement côté client. Il prend en charge les opérateurs de requête courants des moteurs de recherche web.
Le langage de requête complet Lucene, que vous pouvez obtenir en définissant
queryType=full, étend le langage de requête simple par défaut en y ajoutant la prise en charge de plusieurs opérateurs et types de requête, tels que les caractères génériques, et les requêtes partielles, d’expression régulière et portant sur des champs. Par exemple, une expression régulière envoyée en syntaxe de requête simple serait interprétée en tant que chaîne de requête et pas en tant qu’expression. L’exemple de requête de cet article utilise le langage de requête complet Lucene.
Impact du mode de recherche sur l’Analyseur
Le paramètre de requête de recherche « searchMode » peut également affecter l’analyse. Il contrôle l’opérateur par défaut pour les requêtes booléennes : quelconque (valeur par défaut) ou tout.
Lorsque « searchMode=any » (valeur par défaut), le délimiteur d’espace entre « spacieux » et « air condition » est OU (||). Le texte de l’exemple de requête équivaut donc à :
Spacious,||air-condition*+"Ocean view"
Les opérateurs explicites, tels que + dans +"Ocean view", ne sont pas équivoques dans la construction de requête booléenne (le terme doit correspondre). Il est moins évident d’interpréter les termes restants : spacieux et air condition. Le moteur doit-il rechercher les correspondances avec vue mer et spacieux et air condition ? Ou doit-il rechercher les correspondances avec vue mer et l’un des termes restants ?
Par défaut (« searchMode=any »), le moteur de recherche choisit l’interprétation la plus large. N’importe quel champ doit être mis en correspondance, reflétant la sémantique du « ou ». L’arborescence de requête initiale décrite précédemment, avec les deux opérations « doit », indique la valeur par défaut.
Supposons que nous définissions maintenant « searchMode=all ». Dans ce cas, l’espace est interprété comme une opération « et ». Chacun des termes restants doit être présent dans le document pour être considéré comme une correspondance. L’exemple de requête résultant serait interprété comme suit :
+Spacious,+air-condition*+"Ocean view"
Une arborescence de requête modifiée pour cette requête se présente comme suit, où un document correspondant représente l’intersection des trois sous-requêtes :

Remarque
Choisir « searchMode=any » plutôt que « searchMode=all » est le meilleur moyen d’exécuter des requêtes représentatives. Les utilisateurs susceptibles d’inclure des opérateurs (fréquent lors de la recherche dans des magasins de documents) peuvent trouver les résultats plus intuitifs si « searchMode=all » informe les constructions de requêtes booléennes. Pour plus d’informations sur l’interaction entre « searchMode » et les opérateurs, consultez Syntaxe de requête simple.
Étape 2 : Analyse lexicale
Les analyseurs lexicaux traitent les requêtes de terme et les requêtes d’expression une fois l’arborescence de requête structurée. Un analyseur accepte les entrées de texte transmises par l’analyseur, traite le texte, puis renvoie les termes tokénisés à incorporer dans l’arborescence de requête.
La forme la plus courante d’analyse lexicale est l’analyse linguistique qui transforme les termes de la requête en fonction des règles propres à une langue donnée :
- Réduire un terme de requête à la racine d’un mot
- Supprimer les mots non essentiels (mots vides, tels que « le », « la », « les » ou « et » en français)
- Diviser un mot composite en composants
- Convertir en minuscules un mot en majuscules
Toutes ces opérations ont tendance à gommer les différences entre l’entrée de texte fournie par l’utilisateur et les termes stockés dans l’index. Ces opérations vont au-delà du traitement de texte et nécessitent une connaissance approfondie du langage lui-même. Pour ajouter cette couche de sensibilisation linguistique, Azure AI Search prend en charge une longue liste d’analyseurs de langage Lucene et Microsoft.
Remarque
Les exigences d’analyse peuvent être minimales ou élaborées, selon votre scénario. Vous pouvez contrôler la complexité de l’analyse lexicale en sélectionnant l’un des analyseurs prédéfinis ou en créant votre propre analyseur personnalisé. Les analyseurs sont limités aux champs pouvant faire l’objet d’une recherche et sont spécifiés dans le cadre d’une définition de champ. Cela vous permet de faire varier l’analyse lexicale en fonction du champ. L’analyseur Lucene standard est utilisé si aucun autre analyseur n’est spécifié.
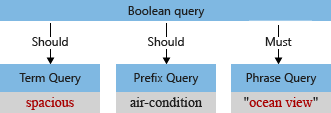
Dans notre exemple, avant l’analyse, l’arborescence de requête initiale contient le terme « Spacieux, », avec un « S » majuscule et une virgule que l’analyseur de requêtes interprète comme faisant partie du terme de la requête (une virgule n’est pas considérée comme un opérateur du langage de requête).
Lorsque l’analyseur par défaut traite le terme, « vue mer » et « spacieux » sont en minuscules et la virgule est supprimée. L’arborescence de requêtes modifiée ressemble à ceci :
Test des comportements de l’analyseur
Le comportement d’un analyseur peut être testé à l’aide de l’API Analyser. Indiquez le texte que vous souhaitez analyser pour voir les termes générés par l’analyseur. Par exemple, pour voir comment l’analyseur standard traite le texte « air condition », vous pouvez émettre la requête suivante :
{
"text": "air-condition",
"analyzer": "standard"
}
L’analyseur standard fractionne le texte d’entrée en deux jetons, les annotant avec des attributs tels que les décalages de début et de fin (pour la mise en surbrillance des correspondances), et annotant également leur position (pour la correspondance d’expression) :
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Exceptions à l’analyse lexicale
L’analyse lexicale s’applique uniquement aux types de requêtes qui nécessitent des termes complets (requête de terme ou requête d’expression). Elle ne s’applique pas aux types de requête avec des termes incomplets : requête de préfixe, requête de caractère générique, requête d’expression régulière ou requête partielle. Ces types de requête, y compris la requête de préfixe avec le terme air-condition* dans notre exemple, sont ajoutés directement à l’arborescence de requête, en ignorant la phase d’analyse. La seule transformation effectuée sur les termes de requête de ce type est l’utilisation de minuscules.
Étape 3 : Extraction de documents
L’extraction de documents fait référence à la recherche de documents avec des termes correspondants dans l’index. Vous comprendrez mieux cette étape à l’aide d’un exemple. Commençons par un index des hôtels dont le schéma simple est le suivant :
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Supposons également que cet index contient les quatre documents suivants :
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Comment les termes sont indexés
Pour comprendre l’extraction, il est utile de connaître quelques notions de base sur l’indexation. L’unité de stockage est un index inversé, un pour chaque champ pouvant faire l’objet d’une recherche. Un index inversé comprend la liste triée de tous les termes issus de tous les documents. Chaque terme correspond à la liste des documents dans laquelle il se trouve, comme le montre l’exemple ci-dessous.
Pour produire les termes d’un index inversé, le moteur de recherche effectue une analyse lexicale sur le contenu des documents, de façon similaire à ce qui se produit pendant le traitement des requêtes :
- Les entrées de texte sont transmises à un analyseur, en minuscules, débarrassées des signes de ponctuation et ainsi de suite, en fonction de la configuration de l’analyseur.
- Les jetons sont le résultat de l’analyse lexicale.
- Les termes sont ajoutés à l’index.
Il est commun, mais pas obligatoire, d’utiliser les mêmes analyseurs pour les opérations de recherche et d’indexation afin que les termes de requête ressemblent davantage aux termes de l’index.
Remarque
Azure AI Search vous permet de spécifier différents analyseurs pour l’indexation et la recherche via les paramètres de champ supplémentaires indexAnalyzer et searchAnalyzer. Par défaut, l’analyseur défini avec la propriété analyzer est utilisé pour l’indexation et la recherche.
Index inversé pour les documents d’exemple
Dans notre exemple, pour le champ titre, l’index inversé ressemble à ceci :
| Terme | Liste de documents |
|---|---|
| atman | 1 |
| plage | 2 |
| hôtel | 1, 3 |
| mer | 4 |
| playa | 3 |
| complexe | 3 |
| retraite | 4 |
Dans le champ Titre, seul hôtel apparaît dans deux documents : 1, 3.
Pour le champ Description, l’index est le suivant :
| Terme | Liste de documents |
|---|---|
| air | 3 |
| et | 4 |
| plage | 1 |
| conditionné | 3 |
| confortable | 3 |
| distance | 1 |
| île | 2 |
| kauai | 2 |
| situé | 2 |
| north | 2 |
| mer | 1, 2, 3 |
| sur | 2 |
| on | 2 |
| calme | 4 |
| chambres | 1, 3 |
| isolé | 4 |
| rive | 2 |
| spacieux | 1 |
| le | 1, 2 |
| à | 1 |
| view | 1, 2, 3 |
| marche | 1 |
| par | 3 |
Termes de requête correspondant aux termes indexés
Étant donné les index inversés ci-dessus, nous allons revenir à l’exemple de requête et voir comment les documents correspondants sont trouvés pour notre exemple. L’arborescence de requête finale ressemble à ceci :
Pendant l’exécution de la requête, les requêtes individuelles sont exécutées indépendamment sur les champs pouvant faire l’objet d’une recherche.
La requête TermQuery « spacieux » correspond au document 1 (hôtel Atman).
La requête PrefixQuery « air condition » ne correspond à aucun document.
Ce comportement déroute parfois les développeurs. Bien que le terme « air condition » existe dans le document, il est divisé en deux termes par l’analyseur par défaut. N’oubliez pas que les requêtes de préfixe, qui contiennent des termes partiels, ne sont pas analysées. Par conséquent, les termes avec le préfixe « air condition » sont recherchés dans l’index inversé, mais demeurent introuvables.
La requête PhraseQuery, « vue mer », recherche les termes « mer » et « vue » et vérifie la proximité des termes dans le document d’origine. Les documents 1, 2 et 3 correspondent à cette requête dans le champ Description. Le document 4 contient le terme mer dans le titre, mais n’est pas considéré comme une correspondance, puisque nous recherchons l’expression « vue mer » plutôt que des mots individuels.
Remarque
Une requête de recherche est exécutée indépendamment sur tous les champs pouvant faire l’objet d’une recherche dans l’index Azure AI Search, sauf si vous limitez les champs définis avec le paramètre searchFields , comme illustré dans l’exemple de demande de recherche. Les documents qui correspondent à l’un des champs sélectionnés sont renvoyés.
Dans l’ensemble, pour la requête en question, les documents qui correspondent sont les documents 1, 2, 3.
Étape 4 : Notation
Un score de pertinence est attribué à chaque document d’un jeu de résultats de recherche. La fonction du score de pertinence est d’accorder une place prioritaire aux documents qui répondent le mieux à une question de l’utilisateur exprimée par la requête de recherche. Le score est calculé en fonction des propriétés statistiques des termes qui correspondent. La base de la formule de notation est appelée TF-IDF (Term Frequency-Inverse Document Frequency, fréquence de terme-fréquence inverse de document). Dans les requêtes qui contiennent des termes rares et courants, TF/IDF promeut les résultats contenant le terme rare. Par exemple, dans un index hypothétique de tous les articles Wikipedia, à partir de documents correspondant à la requête le président, les documents correspondant au terme président sont considérés comme plus pertinents que les documents correspondant au terme le.
Exemple de notation
Souvenez-vous des trois documents correspondant à notre exemple de requête :
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Le document 1 correspond mieux à la requête, car le terme spacieux et l’expression requise vue mer se trouvent tous les deux dans le champ Description. Les documents2 et 3 correspondent uniquement à l’expression vue mer. Il peut être surprenant que le score de pertinence des documents 2 et 3 soit différent, bien qu’ils correspondent à la requête de la même façon. Cela signifie que la formule de notation a plus de composants que la formule TF/IDF. Dans ce cas, un score légèrement plus élevé a été affecté au document 3, car sa description est plus courte. En savoir plus sur la formule de notation pratique Lucene pour comprendre comment la longueur de champ et d’autres facteurs peuvent influencer le score de pertinence.
Certains types de requête (caractère générique, préfixe, expression régulière) contribuent toujours à un score constant dans le score général du document. Ainsi, les correspondances trouvées par le biais de l’extension de requête sont incluses dans les résultats, sans affecter le classement.
L’exemple suivant illustre l’importance de ce facteur. Les recherches avec caractères génériques, y compris les recherches de préfixe, sont ambiguës par définition, car l’entrée est une chaîne partielle avec des correspondances potentielles sur un très grand nombre de termes disparates (imaginez l’entrée « tour* » avec des correspondances trouvées sur « tours », « tourettes » et « tourmaline »). Étant donné la nature de ces résultats, il est impossible de déduire raisonnablement quels termes sont plus utiles que d’autres. Pour cette raison, nous ignorons les fréquences de terme lors de la notation des résultats dans les requêtes de types génériques, de préfixe et d’expression régulière. Dans une requête de recherche à parties multiples qui comprend des termes partiels et complets, les résultats de l’entrée partielle sont incorporés à un score constant pour éviter le biais vers les correspondances potentiellement inattendues.
Réglage de la pertinence
Il existe deux façons de régler les scores de pertinence dans Azure AI Search :
Les profils de score promeuvent les documents dans la liste ordonnée des résultats en fonction d’un ensemble de règles. Dans notre exemple, nous pourrions considérer que les documents correspondant au champ Titre sont plus pertinents que les documents correspondant au champ Description. En outre, si notre index comporte un champ Prix pour chaque hôtel, nous aurions pu promouvoir les documents avec un prix inférieur. Pour plus d’informations, consultez Ajouter des profils de score à un index de recherche.
La promotion de termes (disponible uniquement dans la syntaxe de requête complète Lucene) fournit un opérateur de promotion
^qui peut être appliqué à d’autres parties de l’arborescence de requête. Dans notre exemple, au lieu de rechercher le préfixe air condition, on peut rechercher le terme exact air condition ou le préfixe, mais les documents qui correspondent au terme exact sont mieux classés lorsqu’on applique la promotion à la requête de terme : air condition^2||air condition*. Pour plus d’informations, consultez Promotion de termes dans une requête.
Notation dans un index distribué
Tous les index dans Azure AI Search sont automatiquement divisés en plusieurs partitions, ce qui nous permet de distribuer rapidement l’index entre plusieurs nœuds pendant le scale-up ou le scale-down du service. Lorsqu’une requête de recherche est émise, elle est émise sur chaque partition indépendamment. Les résultats de chaque partition sont ensuite fusionnés et classés par notation (si aucun autre classement n’est défini). Il est important de savoir que la fonction de scoring compare la fréquence de terme de requête à la fréquence inverse de documents dans tous les documents de la partition, et pas dans toutes les partitions.
Cela signifie qu’un score de pertinence peut être différent pour des documents identiques s’ils résident sur différentes partitions. Heureusement, ces différences ont tendance à disparaître à mesure que le nombre de documents dans l’index augmente et ce, grâce à une distribution des termes plus homogène. Il est impossible de deviner sur quelle partition un document sera placé. Toutefois, si la clé de document ne change pas, celui-ci sera toujours affecté à la même partition.
En général, le score du document n’est pas le meilleur attribut pour classer les documents si la stabilité du classement est importante. Par exemple, étant donné deux documents avec un score identique, il n’existe aucune garantie qu’un document apparaît en premier dans les exécutions suivantes de la même requête. Le score du document doit uniquement fournir une idée générale de la pertinence du document par rapport à d’autres documents dans le jeu de résultats.
Conclusion
Le succès des moteurs de recherche commerciaux a suscité des attentes en matière de recherche en texte intégral sur les données privées. Quelle que soit l’expérience de recherche, nous nous attendons désormais à ce que le moteur comprenne notre intention, même lorsque les termes sont mal orthographiés ou incomplets. Nous pouvons même nous attendre à des correspondances basées sur des termes ou synonymes quasiment équivalents que nous n’avons jamais spécifiés.
D’un point de vue technique, la recherche en texte intégral est très complexe, nécessitant une analyse linguistique sophistiquée et une approche systématique du traitement de manière à distiller, développer et transformer les termes de requête pour renvoyer un résultat correspondant. Compte tenu des complexités inhérentes, de nombreux facteurs peuvent affecter le résultat d’une requête. Pour cette raison, prenez le temps nécessaire pour comprendre le fonctionnement de la recherche en texte intégral si vous essayez d’analyser des résultats inattendus.
Cet article a exploré la recherche en texte intégral dans le contexte d’Azure AI Search. Nous espérons qu’il vous a donné les bases nécessaires pour connaître les causes potentielles des problèmes les plus courants en matière de requête, ainsi que leurs résolutions.
Étapes suivantes
Créez l’index des exemples, essayez différentes requêtes et passez en revue les résultats. Pour obtenir des instructions, consultez la page Générer et interroger un index dans le portail.
Essayez d’autres syntaxes de requête à partir de la section exemple Rechercher des documents ou à partir de la Syntaxe de requête simple dans l’Explorateur de recherche du portail.
Passez en revue les profils de score si vous souhaitez paramétrer le classement dans votre application de recherche.
Découvrez comment appliquer des analyseurs lexicaux propres au langage.
Configurez des analyseurs personnalisés pour un traitement minimal ou pour un traitement spécialisé sur des champs spécifiques.
Voir aussi
API REST de recherche de documents