Modèles de conception pour les applications SaaS multi-locataires et la recherche Azure AI
Une application multilocataire est une application qui fournit les mêmes services et fonctionnalités à plusieurs locataires qui ne peuvent pas voir ni partager les données d’un autre locataire. Cet article aborde les stratégies d’isolation de locataire pour les applications multi-locataires conçues avec la recherche Azure AI.
Concepts de la recherche Azure AI
En tant que solution SaaS (logiciel en tant que service), la recherche Azure AI permet aux développeurs d’ajouter des expériences de recherche enrichies dans les applications sans avoir à gérer d’infrastructure, ni devenir un expert en matière de récupération d’informations. Les données sont téléchargées vers le service, puis stockées dans le cloud. À l’aide de requêtes simples dans l’API de recherche Azure AI, les données peuvent ensuite être modifiées et faire l’objet de recherches.
Rechercher des services, des index, des champs et des documents
Avant d’aborder les modèles de conception, il est important de comprendre certains concepts de base.
Lorsque vous utilisez la recherche Azure AI, vous vous abonnez à un service de recherche. Lorsque les données sont téléchargées vers la recherche Azure AI, elles sont stockées dans un index au sein du service de recherche. Un seul service peut contenir plusieurs index. Pour utiliser les concepts familiers des bases de données, le service de recherche peut être comparé à une base de données, tandis que les index au sein d’un service peuvent être comparés aux tables dans une base de données.
Chaque index au sein d’un service de recherche possède son propre schéma, qui est défini par un certain nombre de champspersonnalisables. Les données sont ajoutées à un index de recherche Azure AI sous la forme de documentsindividuels. Chaque document doit être téléchargé dans un index spécifique et doit respecter le schéma de cet index. Lors de la recherche de données à l’aide de la recherche Azure AI, les requêtes de recherche en texte intégral sont exécutées sur un index spécifique. Pour comparer ces concepts à ceux d’une base de données, les champs peuvent être comparés aux colonnes d’une table et les documents peuvent être comparés aux lignes.
Évolutivité
Tout service de recherche Azure AI dans le niveau tarifaire standard peut effectuer un scale-in en deux dimensions : stockage et disponibilité.
- partitions pour augmenter le stockage d’un service de recherche.
- réplicas à un service pour augmenter le débit des requêtes qu’un service de recherche peut gérer.
L’ajout et la suppression de partitions et de réplicas lorsque nécessaire permet à la capacité du service de recherche d’augmenter en fonction de la quantité de données et du trafic demandés par l’application. Pour qu’un service de recherche obtienne un Contrat de niveau de serviceen lecture, deux réplicas sont nécessaires. Pour qu’un service obtienne un Contrat de niveau de serviceen lecture et en écriture, trois réplicas sont nécessaires.
Limites du service et de l’index dans la recherche Azure AI
Il existe différents niveaux tarifaires dans la recherche Azure AI et chaque niveau présente des limites et quotas différents. Certaines de ces limites se situent au niveau du service, certaines au niveau de l’index, et d’autres au niveau de la partition.
Haute densité S3
Dans le niveau tarifaire S3 de la recherche Azure AI, il existe une option pour le mode haute densité (HD) conçue spécifiquement pour les scénarios multi-locataires. Dans de nombreux cas, il est nécessaire de prendre en charge un grand nombre de locataires plus petits sous un seul service pour tirer parti des avantages de simplicité et de rentabilité.
S3 HD permet de réunir les nombreux index de petite taille sous la gestion d’un seul service de recherche en troquant la possibilité d’effectuer un scale-out des index à l’aide de partitions contre la possibilité d’héberger plus d’index dans un seul service.
Un service S3 est conçu pour héberger un nombre fixe d’index (200 maximum) et permet à chaque index d’évoluer horizontalement au fur et à mesure que de nouvelles partitions sont ajoutées au service. L’ajout de partitions à des services S3 HD augmente le nombre maximal d’index que le service peut héberger. La taille maximale idéale pour un index S3 HD est d’environ 50 à 80 Go, même s’il n’y a pas de limite de taille matérielle sur chaque index imposée par le système.
Considérations relatives aux applications mutualisées
Les applications mutualisées doivent distribuer efficacement les ressources entre les clients tout en conservant un certain niveau de confidentialité entre les différents clients. Il existe quelques considérations à prendre en compte lors de la conception de l’architecture pour ce type d’application :
Isolation des clients : les développeurs d’applications doivent prendre les mesures appropriées pour s’assurer qu’aucun client ne bénéficie d’un accès non autorisé ou non désiré aux données d’autres clients. Au-delà de la confidentialité des données, les stratégies d’isolation des clients nécessitent une gestion efficace des ressources partagées et la protection contre les voisins bruyants.
Coût des ressources cloud : comme pour toute autre application, les solutions logicielles doivent rester compétitives au niveau du coût en tant que composant d’une application mutualisée.
Facilité des opérations : lors du développement d’une architecture mutualisée, l’impact sur les opérations et la complexité de l’application est un facteur important. La recherche Azure AI bénéficie d’un Contrat de niveau de service de 99,9 %.
Empreinte globale : les applications multitenants doivent souvent servir des tenants répartis dans le monde entier.
Évolutivité : les développeurs d’applications doivent trouver l’équilibre entre le fait de maintenir un niveau de complexité des applications suffisamment faible et la conception de l’application de façon à ce qu’elle évolue avec le nombre de clients, ainsi que la taille des données et la charge de travail des clients.
La recherche Azure AI propose quelques limites qui peuvent être utilisées pour isoler les données et la charge de travail des locataires.
Modélisation d’une architecture multi-locataires avec la recherche Azure AI
Dans le cas d’un scénario multilocataire, le développeur de l’application consomme un ou plusieurs services de recherche et répartit leurs locataires entre les services, les index ou les deux. La recherche Azure AI offre quelques modèles courants pour la modélisation d’un scénario multi-locataires :
Un index par locataire : chaque locataire a son propre index dans un service de recherche qui est partagé avec d’autres locataires.
Un service par locataire : chaque locataire possède son propre service de recherche Azure AI dédié, pour un niveau de séparation maximal entre les données et la charge de travail.
Combinaison des deux : les clients les plus volumineux et actifs se voient attribuer des services dédiés, tandis que les clients plus petits se voient attribuer des index individuels au sein de services partagés.
Modèle 1 : Un index par locataire
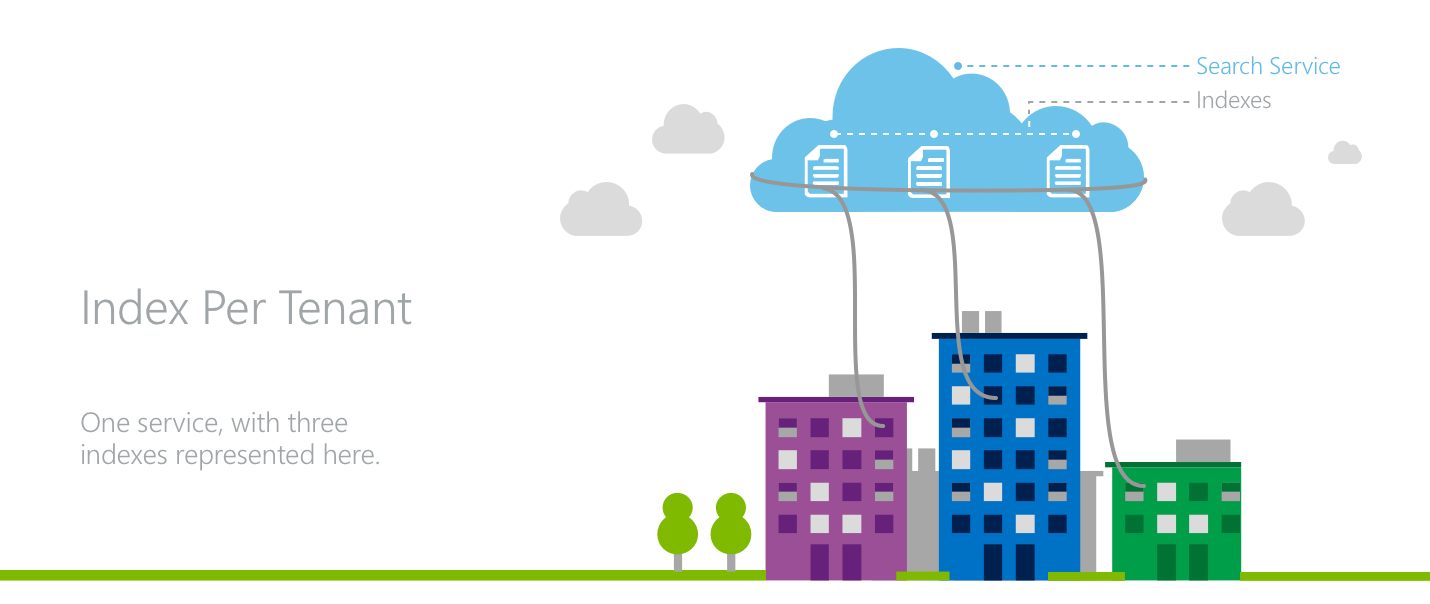
Dans un modèle d’index par locataire, plusieurs locataires occupent un seul service de recherche Azure AI où chaque locataire a son propre index.
Les locataires bénéficient de l’isolation des données, car toutes les requêtes de recherche et les opérations sur les documents sont émises au niveau de l’index dans la recherche Azure AI. Dans la couche d’application, il est entendu qu’il est nécessaire de diriger le trafic des divers locataires vers les index appropriés, tout en gérant les ressources au niveau du service pour tous les locataires.
Un attribut clé du modèle d’index par client est la possibilité pour le développeur d’applications d’augmenter la capacité d’un service de recherche pour les clients de l’application. Si la répartition de la charge de travail est inégale entre les clients, la combinaison optimale des clients peut être distribuée entre les index d’un service de recherche pour prendre en charge un nombre de clients très actifs, gourmands en ressources, tout en gérant simultanément une longue file de clients moins actifs. Le compromis réside dans l’incapacité du modèle à gérer les situations où chaque client est simultanément très actif.
Le modèle d’index par locataire sert de base à un modèle de coût variable, où un service de recherche Azure AI entier est acheté d’avance, puis rempli avec des locataires. Cela permet d’attribuer la capacité inutilisée aux essais et aux comptes gratuits.
Pour les applications ayant une empreinte globale, le modèle d’index par tenant n’est peut-être pas le plus efficace. Si les tenants d’une application sont répartis dans le monde entier, un service distinct peut être nécessaire pour chaque région, ce qui entraîne une duplication des coûts pour chacune d’elles.
La recherche Azure AI permet de mettre à l’échelle les index individuels et d’augmenter le nombre total d’index. Si un niveau tarifaire approprié est choisi, des réplicas et des partitions peuvent être ajoutés au service de recherche entier lorsqu’un index individuel au sein du service devient trop important en termes de stockage ou de trafic.
Si le nombre total d’index devient trop important pour un seul service, un autre service doit être configuré pour prendre en charge les nouveaux clients. Si les index doivent être déplacés entre les services de recherche quand de nouveaux services sont ajoutés, les données de l’index doivent être copiées manuellement d’un index vers l’autre car le déplacement d’un index n’est pas autorisé dans la recherche Azure AI.
Modèle 2 : un service par locataire
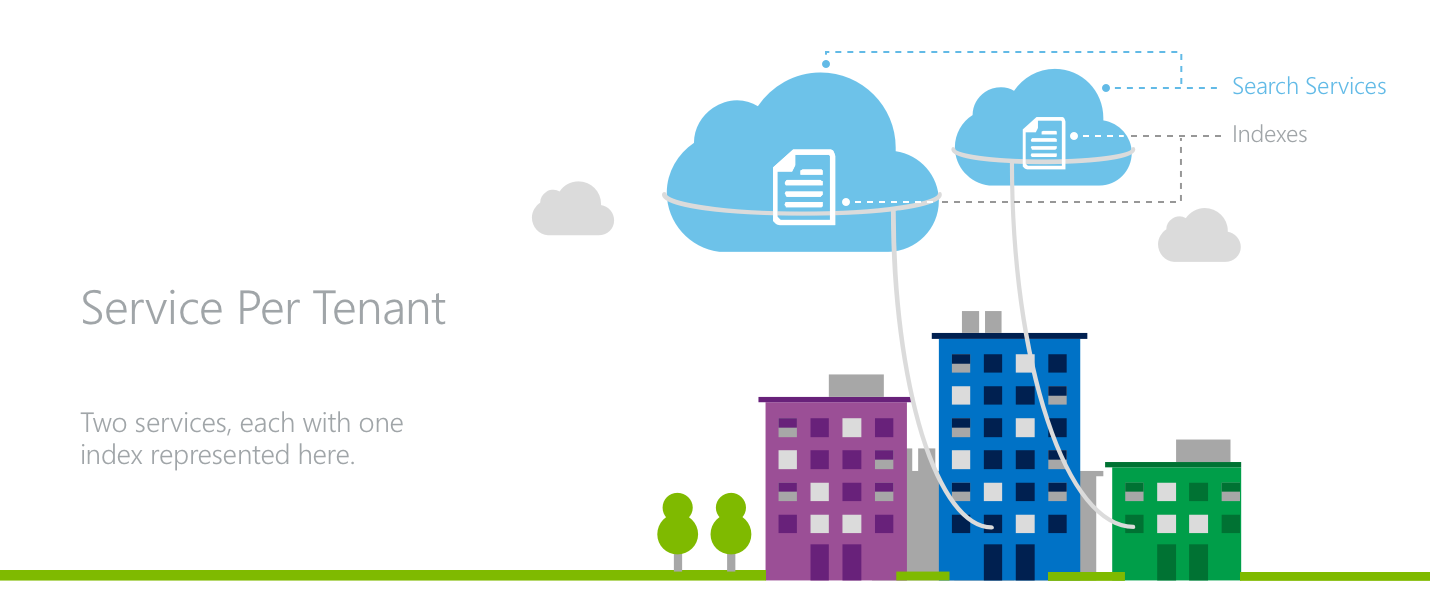
Dans une architecture de service par client, chaque client possède son propre service de recherche.
Dans ce modèle, l’application atteint le niveau maximal d’isolation pour ses clients. Chaque service bénéficie d’un débit et d’un stockage dédiés pour gérer les requêtes de recherche. Chaque locataire possède une propriété individuelle des clés API.
Pour les applications où chaque locataire a une grande envergure ou si la charge de travail varie peu d’un locataire à l’autre, le modèle de service par locataire constitue un choix efficace car les ressources ne sont pas partagées entre les charges de travail de différents locataires.
Un modèle de service par client offre également l’avantage d’un modèle à coût prévisible et fixe. Il n’existe aucun investissement initial pour un service de recherche entier jusqu’à ce qu’il y ait un locataire pour le remplir. Cependant, le coût par locataire est supérieur au modèle d’index par locataire.
Le modèle de service par client constitue une solution efficace pour les applications d’envergure internationale. Avec des locataires répartis géographiquement, il est facile de placer le service de chaque locataire dans la région appropriée.
Les défis liés à la mise à l’échelle de ce modèle se présentent lorsque la croissance des clients individuels surpasse celle de leur service. La recherche Azure AI ne prenant pas en charge l’amélioration du niveau tarifaire d’un service de recherche, toutes les données doivent être copiées manuellement vers un nouveau service.
Modèle 3 : Hybride
Un autre modèle pour la modélisation mutualisée est de combiner les stratégies d’index par client et de service par client.
En mélangeant les deux modèles, les clients les plus volumineux d’une application peuvent occuper des services dédiés, tandis que la longue file de clients moins actifs et plus petits peut occuper des index dans un service partagé. Ce modèle garantit que les clients les plus volumineux bénéficient toujours de performances élevées du service tout en protégeant les clients plus petits des voisins bruyants.
Cependant, l’implémentation de cette stratégie repose sur la capacité à prévoir quels locataires nécessiteront un service dédié au lieu d’un index dans un service partagé. La complexité de l’application augmente avec la nécessité de gérer les deux modèles d’architecture mutualisée.
Atteindre une granularité encore plus fine
Les modèles de conception ci-dessus pour les scénarios multi-locataires dans la recherche Azure AI supposent qu’il existe une étendue uniforme, où chaque locataire constitue une instance entière d’une application. Toutefois, les applications peuvent parfois gérer plusieurs étendues plus petites.
Si les modèles service par locataire et index par locataire ne sont pas des étendues suffisamment petites, il est possible de modéliser un index pour atteindre un degré de précision encore plus fin.
Pour qu’un seul index se comporte différemment pour des points de terminaison clients différents, il est possible d’ajouter un champ à un index, qui désigne une certaine valeur pour chaque client possible. À chaque fois qu’un client appelle la recherche Azure AI pour interroger ou modifier un index, le code de l’application cliente spécifie la valeur appropriée pour ce champ à l’aide de la capacité filtre de la recherche Azure AI au moment de la requête.
Cette méthode peut être utilisée pour obtenir une fonctionnalité de comptes d’utilisateurs distincts, de niveaux d’autorisation distincts et même d’applications distinctes.
Remarque
Utiliser l’approche décrite ci-dessus pour configurer un index unique pour servir plusieurs locataires affecte la pertinence des résultats de recherche. Les notes de pertinence de la recherche sont calculées au niveau de l’index et non au niveau du locataire. Ainsi, toutes les données des locataires sont incorporées dans les statistiques sous-jacentes des notes de pertinence, comme la fréquence des termes.
Étapes suivantes
La recherche Azure AI est un choix irrésistible pour de nombreuses applications. Lorsque vous évaluez les différents modèles de conception pour les applications multi-locataires, consultez les différents niveaux tarifaires et les limites de service respectives pour mieux adapter la recherche Azure AI aux architectures et aux charges de travail de toutes tailles.