Segmenter des documents volumineux pour les solutions de recherche vectorielle dans Recherche Azure AI
Le partitionnement de documents volumineux en blocs plus petits peut vous aider à rester dans les limites du nombre maximal d’entrées de jeton des modèles d’incorporations. Par exemple, la longueur maximale du texte d’entrée pour le modèle text-embedding-ada-002 Azure OpenAI est de 8 191 jetons. Étant donné que chaque jeton est composé d’environ quatre caractères de texte pour les modèles OpenAI courants, cette limite maximale équivaut à environ 6 000 mots de texte. Si vous utilisez ces modèles pour générer des incorporations, il est essentiel que le texte d’entrée reste sous la limite. Le partitionnement de votre contenu en blocs garantit que vos données peuvent être traitées par les modèles d’incorporation et que vous ne perdez pas d’informations en raison de la troncation.
Nous recommandons la vectorisation intégrée pour la segmentation et l’incorporation de données intégrées. La vectorisation intégrée dépend des indexeurs, des ensembles de compétences, de la compétence Fractionnement de texte et d’une compétence d’incorporation telle que Compétence d’incorporation Azure OpenAI. Si vous ne pouvez pas utiliser la vectorisation intégrée, cet article décrit certaines approches de segmentation de votre contenu.
Techniques courantes de découpage en morceaux
La segmentation n’est requise que si les documents sources sont trop volumineux pour la taille maximale d’entrée imposée par les modèles.
Voici quelques techniques courantes de segmentation, en commençant par la méthode la plus couramment utilisée :
Morceaux de taille fixe : La définition d'une taille fixe suffisante pour des paragraphes sémantiquement significatifs (par exemple, 200 mots) et permettant un certain chevauchement (par exemple, 10 à 15 % du contenu) peut produire de bons morceaux qui serviront d'entrée aux générateurs de vecteurs d'incorporation.
Segments de taille variable en fonction du contenu : partitionnez vos données en fonction des caractéristiques de contenu, telles que les marques de ponctuation de fin de phrase, les marqueurs de fin de ligne ou l’utilisation de fonctionnalités dans les bibliothèques NLP (Natural Language Processing). La structure du langage Markdown peut également être utilisée pour fractionner les données.
Personnaliser ou itérer sur l'une des techniques ci-dessus. Par exemple, lorsqu'il s'agit de documents volumineux, vous pouvez utiliser des morceaux de taille variable, mais aussi ajouter le titre du document aux morceaux du milieu du document afin d'éviter la perte de contexte.
Considérations relatives au chevauchement de contenu
Lorsque vous segmentez des données, le chevauchement d’une petite quantité de texte entre les blocs peut aider à préserver le contexte. Nous recommandons de commencer par un chevauchement d'environ 10 %. Par exemple, étant donné une taille de bloc fixe de 256 jetons, vous commencerez à tester avec un chevauchement de 25 jetons. La quantité réelle de chevauchement varie en fonction du type de données et du cas d'utilisation spécifique, mais nous avons constaté que 10 à 15 % conviennent à de nombreux scénarios.
Facteurs de segmentation des données
Quand il s’agit de segmenter des données, réfléchissez à ces facteurs :
Forme et densité des documents. Si vous avez besoin d’un texte ou d’un passage intact, des segments plus volumineux et des segments variables qui préservent la structure des phrases peuvent produire de meilleurs résultats.
Requêtes utilisateur : les segments plus volumineux et les stratégies qui se chevauchent permettent de préserver le contexte et la richesse sémantique des requêtes qui ciblent des informations spécifiques.
Les modèles de langage volumineux (LLM) ont des instructions de performances pour la taille de bloc. vous devez définir une taille de bloc qui fonctionne le mieux pour tous les modèles que vous utilisez. Par exemple, si vous utilisez des modèles pour résumer et incorporer des éléments, choisissez une taille de bloc optimale qui fonctionne pour les deux.
Fonctionnement de la segmentation dans le flux de travail
Si vous avez des documents volumineux, vous devez insérer une étape de segmentation dans les workflows d’indexation et d’interrogation qui décompose le texte volumineux. Lorsque vous utilisez la vectorisation intégrée, une stratégie de segmentation par défaut utilisant la compétence de fractionnement de texte est appliquée. Vous pouvez également appliquer une stratégie de segmentation personnalisée à l’aide d’une compétence personnalisée. Voici quelques bibliothèques qui proposent le découpage en morceaux :
La plupart des bibliothèques fournissent des techniques courantes de segmentation pour la taille fixe, la taille variable ou une combinaison. Vous pouvez également spécifier un chevauchement qui duplique une petite quantité de contenu dans chaque bloc pour la conservation du contexte.
Exemples de segmentation
Les exemples suivants montrent comment les stratégies de segmentation sont appliquées au fichier PDF du livre électronique Earth at Night de la NASA :
Exemple de compétence de Fractionnement de texte
La segmentation des données intégrées par le biais de la compétence de fractionnement de texte est en disponibilité générale.
Cette section décrit la segmentation de données intégrée à l’aide d’une approche pilotée par les compétences et des paramètres de compétence de fractionnement de texte.
Vous trouverez un exemple de notebook pour cet exemple dans le référentiel azure-search-vector-samples.
Configurez textSplitMode de façon à décomposer le contenu en blocs plus petits :
pages(par défaut). Les blocs sont constitués de plusieurs phrases.sentences. Les blocs sont constitués de phrases uniques. Ce qui constitue une « phrase » dépend de la langue. En anglais, la ponctuation de fin de phrase standard telle que.ou!est utilisée. La langue est contrôlée par le paramètredefaultLanguageCode.
Le paramètre pages ajoute des paramètres supplémentaires :
maximumPageLengthdéfinit le nombre maximal de caractères 1 ou de tokens 2 dans chaque bloc. Le séparateur de texte évite de fractionner les phrases ; le nombre de caractères réel dépend par conséquent du contenu.pageOverlapLengthdéfinit le nombre de caractères, à compter de la fin de la page précédente, inclus au début de la page suivante. Si ce paramètre est défini, il doit être inférieur à la moitié de la longueur maximale de la page.maximumPagesToTakedéfinit le nombre de pages/blocs à prendre à partir d’un document. La valeur par défaut est 0, ce qui signifie qu’il faut prendre toutes les pages ou blocs du document.
1 Les caractères ne s’alignent pas sur la définition d’un jeton. Le nombre de jetons mesurés par le modèle LLM peut être différent de la taille de caractère mesurée par la compétence Fractionnement de texte.
2 La segmentation de jetons est disponible dans la préversion 2024-09-01-preview et inclut des paramètres supplémentaires pour spécifier un générateur de jetons et tout jeton qui ne doit pas être fractionné pendant la segmentation.
Le tableau suivant montre comment le choix des paramètres affecte le nombre total de blocs du livre électronique Earth at Night :
textSplitMode |
maximumPageLength |
pageOverlapLength |
Nombre total de blocs |
|---|---|---|---|
pages |
1 000 | 0 | 172 |
pages |
1 000 | 200 | 216 |
pages |
2 000 | 0 | 85 % |
pages |
2000 | 500 | 113 |
pages |
5 000 | 0 | 34 |
pages |
5 000 | 500 | 38 |
sentences |
N/A | N/A | 13 361 |
Lorsque textSplitMode a la valeur pages, une majorité de blocs ont un nombre total de caractères proche de maximumPageLength. Le nombre de caractères des blocs varie en raison des différences entre les emplacements des limites de phrases à l’intérieur du bloc. La longueur du jeton de bloc varie en raison des différences de contenu du bloc.
Les histogrammes suivants montrent la distribution de la longueur des caractères des blocs en fonction de la longueur du jeton de bloc pour gpt-35-turbo lorsque textSplitMode a la valeur pages,maximumPageLength a la valeur 2000 et pageOverlapLength a la valeur 500 sur le livre électronique Earth at Night :
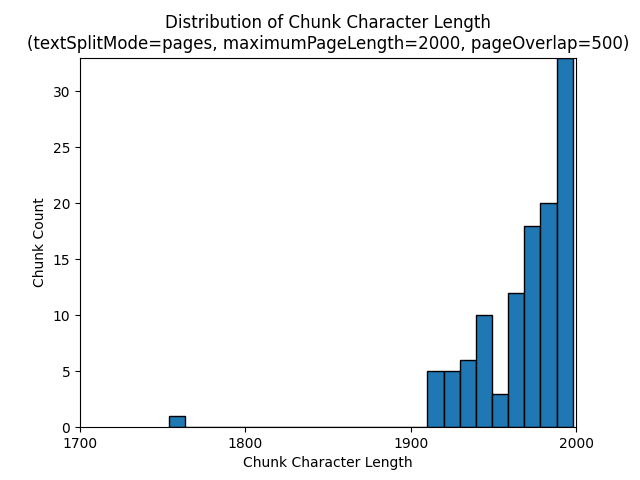
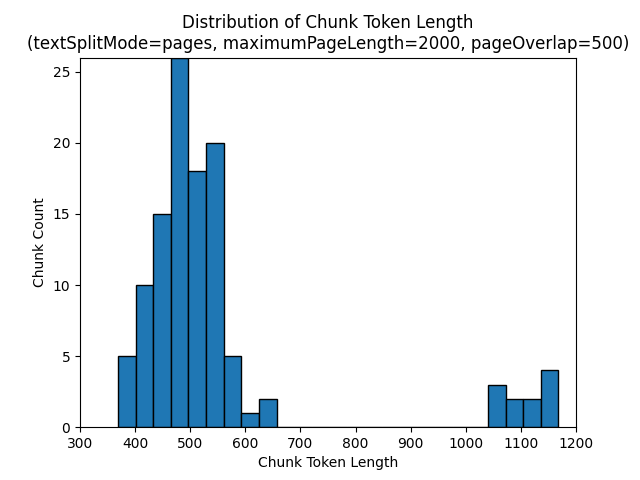
L’utilisation de la valeur sentences pour textSplitMode génère un grand nombre de blocs constitués de phrases individuelles. Ces blocs sont beaucoup plus petits que ceux produits par pages, et le nombre de jetons des blocs correspond plus étroitement au nombre de caractères.
Les histogrammes suivants montrent la distribution de la longueur des caractères des blocs en fonction de la longueur du jeton de bloc pour gpt-35-turbo lorsque textSplitMode a la valeur sentencessur le livre électronique Earth at Night :
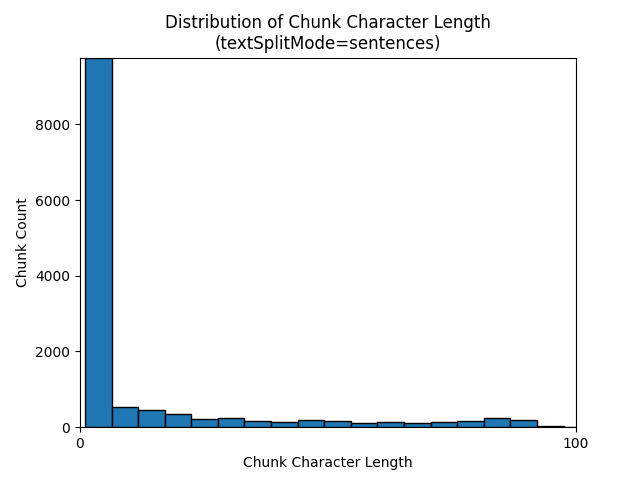
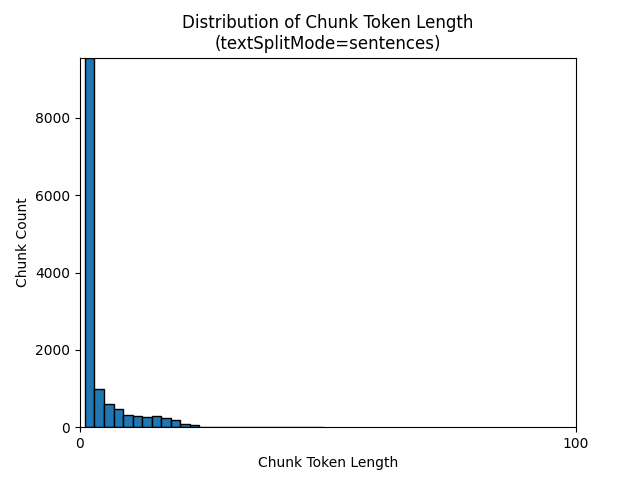
Le choix optimal des paramètres dépend de la façon dont les blocs seront utilisés. Pour la plupart des applications, il est recommandé de commencer par les paramètres par défaut suivants :
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Exemple de segmentation de données LangChain
LangChain fournit des chargeurs de documents et des séparateurs de texte. Cet exemple montre comment charger un fichier PDF, obtenir les quantités de jetons et configurer un séparateur de texte. L’obtention des quantités de jetons vous aide à prendre une décision éclairée quant au dimensionnement des segments.
Vous trouverez un exemple de notebook pour cet exemple dans le référentiel azure-search-vector-samples.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
La sortie indique 200 documents ou pages dans le PDF.
Pour obtenir une estimation de la quantité de jetons pour ces pages, utilisez TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
La sortie indique qu’aucune page n’a zéro jeton, que la quantité moyenne de jetons par page est 189, et que le nombre maximal de jetons d’une page est 1583.
La connaissance de la quantité moyenne et maximale de jetons vous aide à définir la taille de segment. Bien que vous puissiez utiliser la recommandation standard de 2000 caractères avec un chevauchement de 500 caractères, dans le cas présent il est judicieux d’aller plus bas, étant donné le nombre de jetons de l’exemple de document. En fait, la définition d’une valeur de chevauchement trop élevée peut entraîner l’absence totale de chevauchement.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
La sortie de deux blocs consécutifs montre le texte du premier bloc qui chevauche le deuxième bloc. La sortie est légèrement modifiée pour des raisons de lisibilité.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Compétence personnalisée
Un exemple de de génération de segments de taille fixe et d’incorporation illustre la génération d’incorporation de segments et de vecteurs à l’aide de modèles d’incorporation Azure OpenAI . Cet exemple utilise une compétence personnalisée Recherche Azure AI dans le référentiel Power Skills pour encapsuler l’étape de segmentation.