Créer une requête vectorielle dans Azure AI Search
Dans Recherche Azure AI, si vous avez un index vectoriel, cet article explique comment le faire :
Cet article utilise REST pour l’illustration. Pour obtenir des exemples de code dans d’autres langages, consultez les azure-search-vector-samples référentiel GitHub pour les solutions de bout en bout qui incluent des requêtes vectorielles.
Vous pouvez également utiliser l’Explorateur de recherche sur le Portail Azure.
Prérequis
La Recherche Azure AI, dans n’importe quelle région et sur n’importe quel niveau.
Magasin vectoriel sur Recherche Azure AI. Recherchez une section
vectorSearchdans votre index pour confirmer un index vectoriel.Si vous le souhaitez, ajoutez un vectoriseur à votre index pour la conversion de texte en vecteur ou d’image en vecteur intégrée pendant les requêtes.
Visual Studio Code avec un client REST et des exemples de données si vous souhaitez exécuter ces exemples vous-même. Pour bien démarrer avec le client REST, consultez Démarrage rapide : Recherche Azure AI à l’aide de REST.
Convertir une entrée de chaîne de requête en vecteur
Pour interroger un champ vectoriel, la requête elle-même doit être un vecteur.
Une approche pour convertir la chaîne de requête texte d'un utilisateur en sa représentation vectorielle consiste à appeler une bibliothèque d'intégration ou une API dans le code de votre application. Comme meilleure pratique, toujours utiliser les mêmes modèles d’incorporation utilisés pour générer des incorporations dans les documents sources. Vous trouverez des exemples de code montrant comment générer des incorporations dans le référentiel azure-search-vector-samples .
Une deuxième approche consiste à utiliser la vectorisation intégrée, actuellement en disponibilité générale, pour que la Recherche Azure AI gère vos entrées et sorties de vectorisation de requête.
Voici un exemple d’API REST d’une chaîne de requête soumise à un déploiement d’un modèle d’intégration Azure OpenAI :
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
La réponse attendue est 202 pour un appel réussi au modèle déployé.
Le champ « incorporation » dans le corps de la réponse est la représentation vectorielle de la chaîne de requête « entrée ». À des fins de test, vous copieriez la valeur du tableau « embedding » dans « vectorQueries.vector » dans une requête de requête, en utilisant la syntaxe présentée dans les sections suivantes.
La réponse réelle pour cet appel POST au modèle déployé comprend 1 536 intégrations, réduites ici uniquement aux premiers vecteurs pour plus de lisibilité.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
Dans cette approche, votre code d'application est responsable de la connexion à un modèle, de la génération des intégrations et de la gestion de la réponse.
Demande de requête vectorielle
Cette section présente la structure de base d’une requête vectorielle. Vous pouvez utiliser le Portail Microsoft Azure, les API REST ou les SDK Azure pour formuler une requête vectorielle. Si vous effectuez une migration à partir de 2023-07-01-Preview, il existe des changements cassants. Pour plus d’informations, consultez Mise à niveau vers la dernière de l’API REST.
2024-07-01 est la version stable de l’API REST pour Rechercher POST. Cette version prend en charge :
vectorQueriesest la construction de la recherche vectorielle.vectorQueries.kinddéfini survectorpour un tableau de vecteurs, ou défini surtextsi l’entrée est une chaîne et vous disposez d’un vectoriseur.vectorQueries.vectorest une requête (représentation vectorielle du texte ou d’une image).vectorQueries.weight(facultatif) spécifie la pondération relative de chaque requête vectorielle incluse dans les opérations de recherche (voir Pondération de vecteurs).exhaustive(facultatif) appelle un KNN exhaustif au moment de la requête, même si le champ est indexé pour HNSW.
Dans l’exemple suivant, le vecteur est une représentation de cette chaîne : « quels services Azure prennent en charge la recherche en texte intégral ». La requête cible le champ contentVector. La requête retourne k résultats. Le vecteur réel a 1536 incorporations. Il est donc rogné dans cet exemple pour la lisibilité.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Réponse à la requête vectorielle
Dans Recherche Azure AI, les réponses aux requêtes se composent de tous les champs retrievable par défaut. Toutefois, il est courant de limiter les résultats de recherche à un sous-ensemble de champs retrievable en les listant dans une instruction select .
Dans une requête vectorielle, réfléchissez bien à la nécessité de vecteur les champs dans une réponse. Les champs vectoriels ne sont pas lisibles par l'homme, donc si vous envoyez une réponse à une page Web, vous devez choisir des champs non vectoriels représentatifs du résultat. Par exemple, si la requête s'exécute sur contentVector, vous pouvez retourner content à la place.
Si vous souhaitez des champs vectoriels dans le résultat, voici un exemple de structure de réponse. contentVector est un tableau de chaînes d’incorporations, rogné ici pour la concision. Le score de recherche indique la pertinence. D'autres champs non vectoriels sont inclus pour le contexte.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Points essentiels :
kdétermine combien de résultats de voisins les plus proches sont renvoyés, dans ce cas, trois. Les requêtes vectorielles renvoient toujours deskrésultats, en supposant qu'au moins deskdocuments existent, même s'il existe des documents peu similaires, car l'algorithme trouve leskvoisins les plus proches du vecteur de requête.Le
@search.scoreest déterminé par l’algorithme de recherche vectorielle.Les champs des résultats de recherche sont soit tous les
retrievablechamps, soit lesselectchamps d'une clause. Lors de l’exécution d’une requête vectorielle, la correspondance est effectuée uniquement sur les données vectorielles. Toutefois, une réponse peut inclure n’importe quel champretrievabled’un index. Puisqu'il n'existe aucune possibilité de décoder le résultat d'un champ vectoriel, l'inclusion de champs de texte non vectoriels est utile pour leurs valeurs lisibles par l'homme.
Champs de vecteurs multiples
Vous pouvez définir la propriété « vectorQueries.fields » sur plusieurs champs vectoriels. La requête vectorielle s'exécute sur chaque champ vectoriel que vous fournissez dans la liste fields. Lorsque vous interrogez plusieurs champs vectoriels, assurez-vous que chacun contient des intégrations du même modèle d'intégration et que la requête est également générée à partir du même modèle d'intégration.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Requêtes vectorielles multiples
La recherche vectorielle multi-requête envoie plusieurs requêtes sur plusieurs champs vectoriels dans votre index de recherche. Un exemple courant de cette requête est l’utilisation de modèles tels que CLIP pour une recherche vectorielle modale où le même modèle peut vectoriser le contenu d’image et de texte.
L’exemple de requête suivant recherche la similarité dans les deux myImageVector et myTextVector, mais envoie respectivement deux incorporations de requêtes différentes, chacune s’exécutant en parallèle. Cette requête produit un résultat marqué à l’aide de fusion de classement réciproque (RRF).
vectorQueriesfournit un tableau de requêtes vectorielles.vectorcontient les vecteurs d’image et les vecteurs de texte dans l’index de recherche. Chaque instance est une requête distincte.fieldsspécifie le champ vecteur à cibler.kcorrespond au nombre de correspondances voisines les plus proches à inclure dans les résultats.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Les résultats de la recherche comprendront une combinaison de texte et d'images, à condition que votre index de recherche comprenne un champ pour le fichier image (un index de recherche ne stocke pas les images).
Interroger avec la vectorisation intégrée
Cette section présente une requête vectorielle qui appelle la vectorisation intégrée qui convertit requête d’image ou de texte en vecteur. Nous recommandons l’API REST stable 2024-07-01, l’Explorateur de recherche ou les packages de SDK Azure plus récents pour cette fonctionnalité.
La condition préalable est que l'index de recherche soit doté d'un vecteur configuré et assigné à un champ de vecteurs. Le vectoriseur fournit des informations de connexion à un modèle d’incorporation utilisé au moment de la requête.
L’Explorateur de recherche prend en charge la vectorisation intégrée au moment de la requête. Si votre index contient des champs vectoriels et possède un vectoriseur, vous pouvez utiliser la conversion de texte en vecteur intégrée.
Connectez-vous au portail Azure avec votre compte Azure, puis accédez à votre service Azure AI Search.
Dans le menu de gauche, développez Gestion de la recherche>Index, puis sélectionnez votre index. L’Explorateur de recherche est le premier onglet de la page d’index.
Vérifiez les Profils vectoriels pour confirmer que vous disposez d’un vectoriseur.

Dans l’Explorateur de recherche, vous pouvez entrer une chaîne de texte dans la barre de recherche par défaut de la vue Requête. Le vectoriseur intégré convertit votre chaîne en vecteur, effectue la recherche et retourne les résultats.
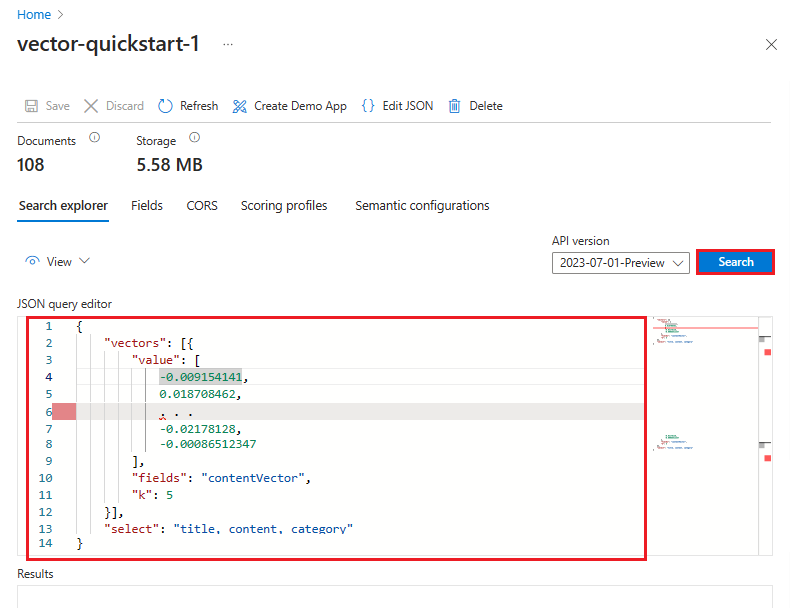
Vous pouvez également sélectionner Vue>Vue JSON pour afficher ou modifier la requête. Si des vecteurs sont présents, l’Explorateur de recherche configure automatiquement une requête vectorielle. Vous pouvez utiliser la vue JSON pour sélectionner des champs utilisés dans la recherche et dans la réponse, ajouter des filtres ou construire des requêtes plus avancées, comme des requêtes hybrides. Un exemple JSON est fourni dans l’onglet API REST de cette section.
Nombre de résultats classés dans une réponse de requête vectorielle
Une requête vectorielle spécifie le paramètre k , qui détermine le nombre de correspondances retournées dans les résultats. Le moteur de recherche retourne toujours k nombre de correspondances. Si k est supérieur au nombre de documents dans l’index, le nombre de documents détermine alors la limite supérieure de ce qui peut être renvoyé.
Si vous connaissez la recherche en texte intégral, vous savez que vous obtenez zéro résultat si l’index ne contient pas de terme ou d’expression. Toutefois, dans la recherche vectorielle, l’opération de recherche identifie les voisins les plus proches et retourne toujours des résultats k même si les voisins les plus proches ne sont pas similaires. Par conséquent, il est possible d’obtenir des résultats pour les requêtes nonsensiques ou hors rubrique, en particulier si vous n’utilisez pas d’invites pour définir des limites. Les résultats moins pertinents ont un score de similarité moins bon, mais ils sont toujours les « plus proches » vecteurs s’il n’existe rien de plus proche. Par conséquent, une réponse sans résultats significatifs peut toujours renvoyer des résultats k, mais le score de similarité de chaque résultat est faible.
Une approche hybride qui inclut la recherche en texte intégral peut atténuer ce problème. Une autre atténuation consiste à définir un seuil minimal sur le score de recherche, mais uniquement si la requête est une requête vectorielle unique pure. Les requêtes hybrides ne sont pas propices aux seuils minimaux, car les plages RRF sont tellement plus petites et volatiles.
Les paramètres de requête affectant le nombre de résultats sont les suivants :
"k": nrésultats pour les requêtes vectorielles uniquement"top": nrésultats pour les requêtes hybrides qui incluent un paramètre « recherche »
« k » et « top » sont facultatifs. Non spécifié, le nombre par défaut de résultats dans une réponse est 50. Vous pouvez définir « haut » et « ignorer » sur la page par le biais de résultats supplémentaires ou modifier la valeur par défaut.
Algorithmes de classement utilisés dans une requête vectorielle
Le classement des résultats est calculé par les deux :
- Métrique de similarité
- Fusion réciproque des rangs (RRF) s'il y a plusieurs ensembles de résultats de recherche.
Métrique de similarité
Métrique de similarité spécifiée dans la section vectorSearch d’index pour une requête vectorielle uniquement. Les valeurs valides sont cosine, euclidean et dotProduct.
Les modèles d’incorporation Azure OpenAI utilisent la similarité cosinus. Par conséquent, si vous utilisez des modèles d’incorporation Azure OpenAI, cosine est la métrique recommandée. Les autres métriques de classement prises en charge incluent euclidean et dotProduct.
Utiliser RRF
Plusieurs ensembles sont créés si la requête cible plusieurs champs vectoriels, exécute plusieurs requêtes vectorielles en parallèle ou si la requête est un hybride de recherche vectorielle et de recherche en texte intégral, avec ou sans classement sémantique.
Lors de l'exécution d'une requête, une requête vectorielle ne peut cibler qu'un seul index vectoriel interne. Ainsi, pour plusieurs champs vectoriels et plusieurs requêtes vectorielles, le moteur de recherche génère plusieurs requêtes qui ciblent les index vectoriels respectifs de chaque champ. Le résultat est un ensemble de résultats classés pour chaque requête, qui sont fusionnés à l'aide de la méthode RRF. Pour plus d'informations, consultez Score de pertinence à l'aide de Reciprocal Rank Fusion (RRF).
Pondération de vecteurs
Ajoutez un paramètre de requête weight pour spécifier le poids relatif de chaque requête vectorielle incluse dans les opérations de recherche. Cette valeur est utilisée lors de la combinaison des résultats de plusieurs listes de classement produites par deux requêtes vectorielles ou plus dans la même requête, ou à partir de la partie vectorielle d’une requête hybride.
La valeur par défaut est 1,0 et la valeur doit être un nombre positif supérieur à zéro.
Les pondérations sont utilisées lors du calcul des scores de fusion de classement réciproque de chaque document. Le calcul consiste à multiplier la valeur weight par le score de classement du document dans son jeu de résultats respectif.
L’exemple suivant est une requête hybride avec deux chaînes de requête vectorielle et une chaîne de caractères. Les pondérations sont affectées aux requêtes vectorielles. La première requête est 0,5 ou la moitié de la pondération, ce qui réduit son importance dans la requête. La deuxième requête vectorielle est deux fois plus importante.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
La pondération vectorielle s’applique uniquement aux vecteurs. La requête texte dans cet exemple (« hello world ») a un poids implicite de 1,0 ou de poids neutre. Toutefois, dans une requête hybride, vous pouvez augmenter ou diminuer l’importance des champs de texte en définissant maxTextRecallSize.
Définir des seuils pour exclure les résultats de faible score (préversion)
La recherche voisine la plus proche retournant toujours les k voisins demandés, il est possible d’obtenir de nombreuses correspondances de score faible pour répondre aux exigences de nombre k sur les résultats de la recherche. Pour exclure les résultats de recherche à faible score, vous pouvez ajouter un paramètre de requête threshold qui filtre les résultats en fonction d’un score minimal. Le filtrage se produit avant la fusion des résultats des différents ensembles de rappels.
Ce paramètre est toujours en préversion. Nous vous recommandons la préversion de l’API REST version 2024-05-01-preview.
Dans cet exemple, toutes les correspondances dont le score est inférieur à 0,8 sont exclues des résultats de recherche vectorielle, même si le nombre de résultats passe en dessous k.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall pour la recherche hybride (préversion)
Les requêtes vectorielles sont souvent utilisées dans des constructions hybrides qui incluent des champs non vecteurs. Si vous découvrez que les résultats du classement BM25 sont sur ou sous-représentés dans les résultats d’une requête hybride, vous pouvez définir maxTextRecallSize pour augmenter ou diminuer les résultats du classement BM25 fournis pour le classement hybride.
Vous ne pouvez définir cette propriété que dans les requêtes hybrides qui incluent à la fois les composants « search » et « vectorQueries ».
Ce paramètre est toujours en préversion. Nous vous recommandons la préversion de l’API REST version 2024-05-01-preview.
Pour plus d’informations, consultez Set maxTextRecallSize – Créer une requête hybride.
Étapes suivantes
Dans une prochaine étape, examinez des exemples de code de requête vectorielle en Python, C# ou JavaScript.