Vue d’ensemble des machines virtuelles série HB
S’applique aux : ✔️ Machines virtuelles Linux ✔️ Machines virtuelles Windows ✔️ Groupes identiques flexibles ✔️ Groupes identiques uniformes
L’optimisation des performances des applications de calcul haute performance (HPC)sur AMD EPYC nécessite une approche bien pensée de l’emplacement de la mémoire et du placement du processus. Nous décrivons ci-dessous l’architecture AMD EPYC et son implémentation sur Azure pour les applications HPC. Nous utilisons le terme « pNUMA » pour faire référence à un domaine NUMA physique et « vNUMA » pour faire référence à un domaine NUMA virtualisé.
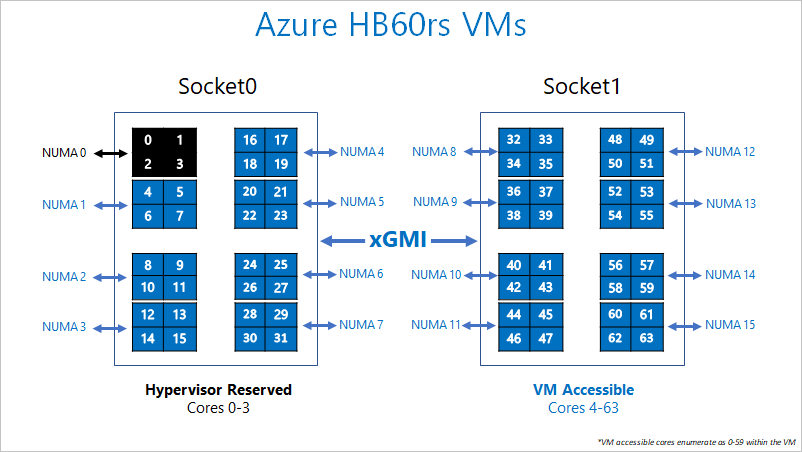
Physiquement, un serveur de la série HB a 2 UC EPYC 7551 de 32 cœurs, soit un total de 64 cœurs physiques. Ces 64 cœurs sont divisées en 16 domaines pNUMA (8 par socket), chacun d’eux comprenant quatre cœurs et étant appelé « Complexe UC » (ou « CCX »). Chaque CCX a son propre cache L3, qui correspond à la représentation de la limite pNUMA/vNUMA par un système d’exploitation. Une paire d’accès de CCXs adjacents se partage l’accès à deux canaux de DRAM physique (32 Go de DRAM dans les serveurs de la série HB).
Pour permettre à l’hyperviseur Azure de fonctionner sans interférer avec la machine virtuelle, nous réservons le domaine pNUMA physique 0 (le premier CCX). Ensuite, nous attribuons les domaines pNUMA 1 à 15 (les unités CCX restantes) à la machine virtuelle. La machine virtuelle voit :
(15 vNUMA domains) * (4 cores/vNUMA) = 60 cœurs par machine virtuelle
La machine virtuelle proprement dite ne sait pas que pNUMA 0 ne le lui a pas été donné. La machine virtuelle comprend pNUMA 1 à 15 comme vNUMA 0 à 14, avec 7 vNUMA sur vSocket 0 et 8 vNUMA sur vSocket 1. Bien que cela soit asymétrique, votre système d’exploitation doit démarrer et fonctionner normalement. Plus loin dans ce guide, nous indiquons comment exécuter au mieux des applications MPI sur cette disposition NUMA asymétrique.
L’épinglage de processus fonctionne sur les machines virtuelles série HB, car nous exposons le silicium sous-jacent tel quel à la machine virtuelle invitée. Nous recommandons vivement l’épinglage de processus (process pinning) à des fins de performances optimales.
Le diagramme suivant illustre la répartition des cœurs réservés pour l’hyperviseur Azure et la machine virtuelle série HB.
Spécifications matérielles
| Spécifications matérielles | Machine virtuelle série HB |
|---|---|
| Cœurs | 60 (SMT désactivé) |
| UC | AMD EPYC 7551 |
| Fréquence de l’UC (non AVX) | ~2,55 GHz (simple + tous les cœurs) |
| Mémoire | 4 GB/cœur (240 Go au total) |
| Disque local | -SSD de 700 Go |
| Infiniband | 100 Gbits EDR Mellanox ConnectX-5 |
| Réseau | 50 Gbits Ethernet (40 Gbits utilisables) SmartNIC Azure 2ème gén. |
Spécifications logicielles
| Spécifications logicielles | Machine virtuelle série HB |
|---|---|
| Taille de travail MPI max | 18 000 cœurs (300 machines virtuelles dans un seul groupe de machines virtuelles identiques avec singlePlacementGroup=true) |
| Prise en charge MPI | HPC-X, Intel MPI, OpenMPI, MVAPICH2, MPICH, Platform MPI |
| Frameworks supplémentaires | UCX, libfabric, PGAS |
| Prise en charge de Stockage Azure | Disques Standard et Premium (maximum 4 disques) |
| Prise en charge du système d’exploitation pour SRIOV RDMA | RHEL 7.6+, Ubuntu 18.04+, SLES 15.4, WinServer 2016+ |
| Prise en charge d’Orchestrator | CycleCloud, Batch, AKS ; options de configuration de cluster |
Important
Ce document fait référence à une version de Linux qui approche ou est en fin de vie (EOL). Envisagez une mise à jour vers une version plus récente.
Étapes suivantes
- Pour en savoir plus, consultez Architecture AMD EPYC et Architectures multiprocesseur. Pour plus d’informations, consultez le Guide d’optimisation HPC pour les processeurs AMD EPYC.
- Consultez les dernières annonces, des exemples de charge de travail HPC et les résultats des performances sur les blogs de la communauté Azure Compute Tech.
- Pour une vision plus globale de l’architecture d’exécution des charges de travail HPC, consultez Calcul haute performance (HPC) sur Azure.