Surveillance détaillée des applications Apache Spark
Avec Microsoft Fabric, vous pouvez utiliser Apache Spark pour exécuter des notebooks, des travaux Apache Spark et d'autres types d’applications dans votre espace de travail. Cet article explique comment superviser vos applications Apache Spark, et ainsi garder un œil sur leur état d’exécution actuel, leurs problèmes et la progression de leurs travaux.
Afficher les applications Apache Spark
Vous pouvez afficher toutes les applications Apache Spark à partir de la définition de tâche Spark, ou le menu contextuel de l’élément de notebook affiche l’option d’exécution récente ->Exécutions récentes.

Vous pouvez sélectionner le nom de l’application que vous souhaitez afficher dans la liste des applications, puis afficher les détails dans la page des détails de l’application.
Surveiller l’état des applications Apache Spark
Ouvrez la page Exécutions récentes du notebook ou de la définition de tâche Spark pour afficher l’état de l’application Apache.
- Réussite

- Mis(e) en file d’attente

- Arrêté

- Annulée

- Échec

Tâches
Ouvrez un travail d’application Apache Spark à partir de la définition de tâche Spark, ou le menu contextuel de l’élément de notebook affiche l’option Exécution récente ->Exécutions récentes -> sélectionner un travail dans la page des exécutions récentes.
Dans la page des détails de l’analyse de l’application Apache Spark, la liste des exécutions de travaux s’affiche sous l’onglet Travaux. Vous pouvez afficher les détails de chaque travail ici, notamment l’ID du travail, la description, l’état, les étapes, les tâches, la durée, les données traitées, la lecture des données, les données écrites et l’extrait de code.
- Cliquer sur l’ID du travail peut développer/réduire le travail.
- Cliquez sur la description du travail. Vous pouvez accéder à la page du travail ou de l’étape dans l’interface utilisateur Spark.
- Cliquez sur l’extrait de code du travail. Vous pouvez vérifier et copier le code associé à ce travail.

Ressources (préversion)
Le graphique d’utilisation de l’Exécuteur affiche visuellement l’allocation d’Exécuteurs de travail Spark et l’utilisation des ressources. Seules les informations de runtime de spark 3.4 et versions ultérieures affichent actuellement cette fonctionnalité. Sélectionnez Ressources (préversion), puis quatre types de courbes sur l’utilisation des Exécuteurs sont tracés, notamment En cours d’exécution, Inactifs, Alloués, Instances maximales.

Pour le type Alloués, se réfère à la situation de nœuds alloués pendant l’exécution de l’application Spark.
Pour les Instances maximales, se réfère au nombre maximal de cœurs alloués à l’application Spark.
Pour le type En cours d’exécution, se réfère au nombre réel de cœurs utilisés par l’application Spark lors de son exécution. Cliquez sur une limite dans le temps lorsque l’application Spark est en cours d’exécution. Les détails de l’allocation de cœurs d’Exécuteur en cours d’exécution s’affichent en bas du graphique.
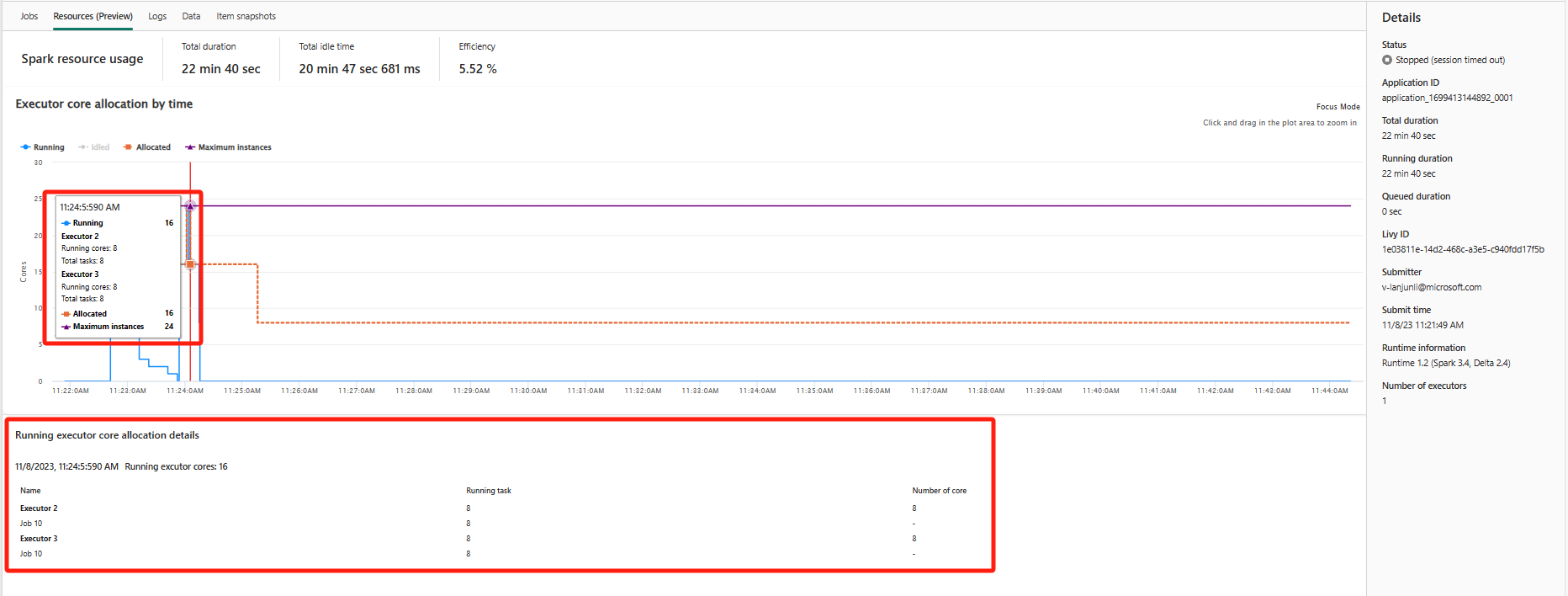
Pour le type Inactifs, il s’agit du nombre de cœurs inutilisés lorsque l’application Spark est en cours d’exécution.

Dans certains cas, il est possible que le nombre de tâches à certains points dans le temps excèdent la capacité des cœurs Exécuteur (par exemple, nombre de tâches > nombre total de cœurs Exécuteur / spark.task.cpus). Cela est conforme aux attentes, car il existe un écart de temps entre une tâche marquée comme étant en cours d’exécution et son exécution réelle sur un cœur Exécuteur. Par conséquent, il est possible que certaines tâches s’affichent comme étant en cours d’exécution, mais qu’elles ne s’exécutent sur aucun cœur.
Sélectionnez l’icône de couleur pour sélectionner ou désélectionner le contenu correspondant dans tous les graphiques.

Panneau Résumé
Dans la page d’analyse de l’application Apache Spark, cliquez sur le bouton Propriétés pour ouvrir/réduire le panneau de résumé. Vous pouvez afficher les détails de cette application dans Détails.
- État de cette application Spark.
- ID de cette application Spark.
- Durée totale.
- Durée d’exécution de cette application Spark.
- Durée mise en file d’attente pour cette application Spark.
- ID Livy
- Émetteur de cette application Spark.
- Temps d’envoi pour cette application Spark.
- Nombre d’exécuteurs.

Journaux d’activité
Sous l’onglet Journaux, vous pouvez afficher le journal complet des journaux Livy, du prélancement ou du pilote avec différentes options sélectionnées dans le volet gauche. Vous pouvez également récupérer directement les informations de journal requises en recherchant des mots clés et afficher les journaux en filtrant les états de journal. Cliquez sur Télécharger le journal pour télécharger les informations de journal dans le local.
Parfois, aucun journal n’est disponible, par exemple l’état du travail est mise en file d’attente et la création du cluster a échoué.
Les journaux dynamiques sont disponibles uniquement en cas d’échec de la soumission de l’application, et les journaux des pilotes sont également fournis.

Données
Sous l’onglet Données, vous pouvez copier la liste de données dans le presse-papiers, télécharger la liste de données et les données uniques, et vérifier les propriétés de chaque données.
- Le volet gauche peut être développé ou réduit.
- Le nom, le format de lecture, la taille, la source et le chemin des fichiers d’entrée et de sortie s’affichent dans cette liste.
- Il est possible de télécharger les fichiers d’entrée et de sortie, de copier leur chemin d’accès et d’afficher leurs propriétés.

Éléments connexes
L’onglet Éléments connexes vous permet de parcourir et d’afficher les éléments associés à l’application Apache Spark, notamment les notebooks, la définition de travail Spark et/ou les pipelines. La page des éléments associés affiche l’instantané des valeurs de code et de paramètre au moment de l’exécution pour les notebooks. Il montre également l’instantané de tous les paramètres au moment de la soumission des définitions de travaux Spark. Si l’application Apache Spark est associée à un pipeline, la page d’élément associée présente également le pipeline et l’activité Spark correspondants.
Dans l’écran Éléments connexes, vous pouvez :
- Parcourir les éléments associés dans l’arborescence hiérarchique.
- Cliquer sur l’icône d’ellipse en regard de chaque élément afin d’afficher une liste d’autres actions que vous pouvez effectuer.
- Cliquez sur l’élément instantané pour afficher son contenu.
- Affichez la barre de navigation pour voir le chemin de l’élément sélectionné à la racine.

Diagnostics
Le panneau de diagnostic fournit aux utilisateurs des recommandations en temps réel et une analyse des erreurs, qui sont générées par Spark Advisor via une analyse du code de l’utilisateur. Avec des modèles intégrés, Apache Spark Advisor permet aux utilisateurs d’éviter les erreurs courantes et analyse les échecs pour identifier leur cause racine.

Contenu connexe
L'étape suivante après avoir affiché les détails d'une application Apache Spark consiste à afficher la progression de la tâche Spark sous la cellule Notebook. Vous pouvez vous référer à :
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour