Tutoriel Lakehouse : Préparer et transformer des données dans le lakehouse
Dans ce tutoriel, vous utilisez des notebooks avec le runtime Spark pour transformer et préparer les données brutes dans votre lakehouse.
Prérequis
Si vous n’avez pas de lakehouse qui contient des données, vous devez :
Préparer les données
À partir des étapes précédentes du tutoriel, nous avons ingéré des données brutes de la source vers la section Fichiers du lakehouse. Vous pouvez maintenant transformer ces données et les préparer pour la création de tables Delta.
Téléchargez les notebooks à partir du dossier Code source du didacticiel Lakehouse.
Dans le sélecteur situé en bas à gauche de l’écran, sélectionnez Ingénieurs de données.

Sélectionnez Importer un notebook dans la section Nouveau en haut de la page d’accueil.
Sélectionnez Charger dans le volet Importer l’état qui s’ouvre sur le côté droit de l’écran.
Sélectionnez tous les notebooks que vous avez téléchargés à la première étape de cette section.
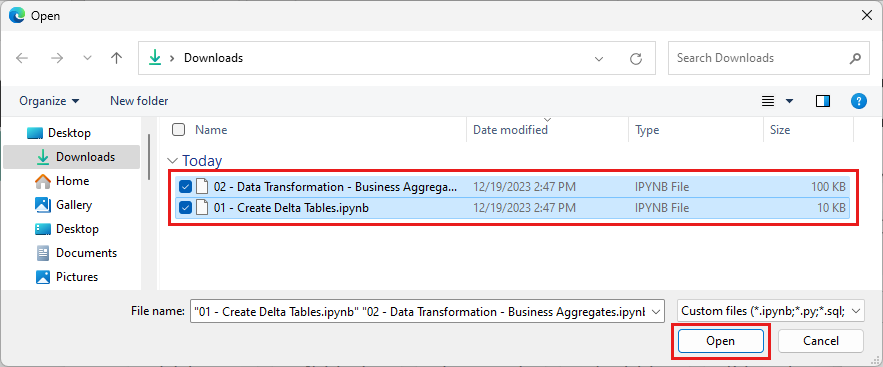
Sélectionnez Ouvrir. Une notification indiquant l’état de l’importation s’affiche dans le coin supérieur droit de la fenêtre du navigateur.
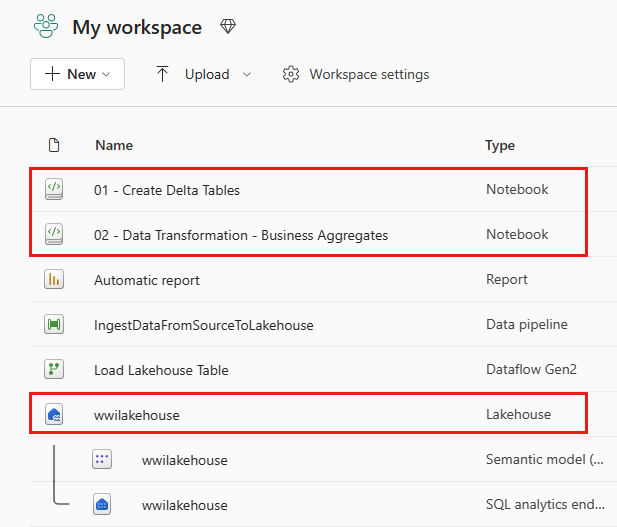
Une fois l’importation réussie, accéder à la vue Éléments de l’espace de travail et voir les notebooks nouvellement importés. Sélectionnez le lakehouse wwilakehouse pour l’ouvrir.
Une fois le lakehouse wwilakehouse ouvert, sélectionnez Ouvrir le notebook>existant dans le menu de navigation supérieur.
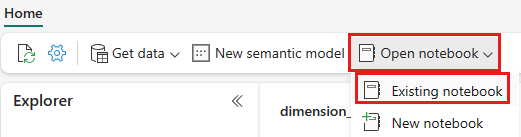
Dans la liste des notebooks existants, sélectionnez le notebook 01 - Créer des tables Delta , puis sélectionnez Ouvrir.
Dans le notebook ouvert dans l’explorateur lakehouse, vous voyez que le notebook est déjà lié à votre lakehouse ouvert.
Remarque
Fabric fournit la fonctionnalité de commande en V pour écrire des fichiers Delta lake optimisés. La commande en V améliore souvent la compression de trois à quatre fois et jusqu’à 10 fois l’accélération des performances sur les fichiers Delta Lake qui ne sont pas optimisés. Spark dans Fabric optimise dynamiquement les partitions tout en générant des fichiers avec une taille par défaut de 128 Mo. La taille de fichier cible peut être modifiée par spécification de charge de travail à l’aide de configurations.
Avec la fonctionnalité d’optimisation de l’écriture, le moteur Apache Spark qui réduit le nombre de fichiers écrits et vise à augmenter la taille des fichiers individuels des données écrites.
Avant d’écrire des données sous forme de tables Delta lake dans la section Tables du lakehouse, vous utilisez deux fonctionnalités Fabric (commande en V et Optimiser l’écriture) pour optimiser l’écriture des données et améliorer les performances de lecture. Pour activer ces fonctionnalités dans votre session, définissez ces configurations dans la première cellule de votre notebook.
Pour démarrer le notebook et exécuter toutes les cellules dans l’ordre, sélectionnez Exécuter tout dans le ruban supérieur (sous Accueil). Ou, pour exécuter uniquement du code à partir d’une cellule spécifique, sélectionnez l’icône Exécuter qui apparaît à gauche de la cellule lors du pointage, ou appuyez sur MAJ + ENTRÉE sur votre clavier pendant que le contrôle se trouve dans la cellule.
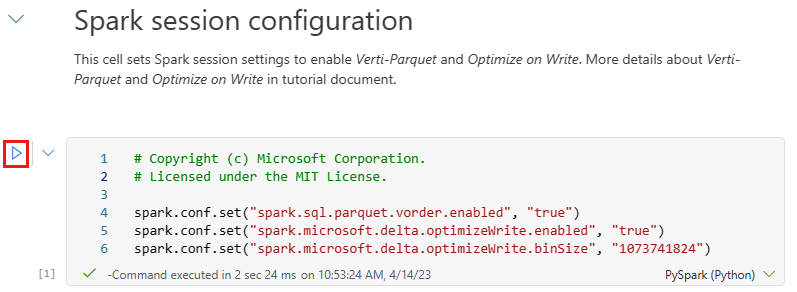
Lors de l’exécution d’une cellule, vous n’avez pas eu à spécifier les détails du pool ou du cluster Spark sous-jacents, car Fabric les fournit via Live pool. Chaque espace de travail Fabric est fourni avec un pool Spark par défaut, appelé Live Pool. Cela signifie que lorsque vous créez des notebooks, vous n’avez pas à vous soucier de spécifier des configurations Spark ou des détails de cluster. Lorsque vous exécutez la première commande de notebook, le pool dynamique est opérationnel en quelques secondes. Et la session Spark est établie et elle commence à exécuter le code. L’exécution du code suivante est presque instantanée dans ce notebook pendant que la session Spark est active.
Ensuite, vous lisez les données brutes de la section Fichiers du lakehouse et ajoutez d’autres colonnes pour différentes parties de date dans le cadre de la transformation. Enfin, vous utilisez l’API partitionBy Spark pour partitionner les données avant de les écrire au format de table Delta en fonction des colonnes de partie de données nouvellement créées (Année et Trimestre).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Une fois les tables de faits chargées, vous pouvez passer au chargement des données pour le reste des dimensions. La cellule suivante crée une fonction pour lire les données brutes de la section Fichiers du lakehouse pour chacun des noms de table passés en tant que paramètre. Ensuite, il crée une liste de tables de dimension. Enfin, il effectue une boucle dans la liste des tables et crée une table Delta pour chaque nom de table lu à partir du paramètre d’entrée. Notez que le script supprime la colonne nommée
Photodans cet exemple puisque la colonne n’est pas utilisée.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Pour valider les tables créées, cliquez avec le bouton droit et sélectionnez Actualiser sur le lakehouse wwilakehouse. Les tables s’affichent.
Revenez à la vue des éléments de l’espace de travail et sélectionnez le lakehouse wwilakehouse pour l’ouvrir.
Maintenant, ouvrez le deuxième notebook. Dans la vue lakehouse, sélectionnez Ouvrir le notebook>existant dans le ruban.
Dans la liste des notebooks existants, sélectionnez le notebook 02 - Transformation des données - Entreprise pour l’ouvrir.
Dans le notebook ouvert dans l’explorateur lakehouse, vous voyez que le notebook est déjà lié à votre lakehouse ouvert.
Une organisation peut avoir des ingénieurs de données travaillant avec Scala/Python et d’autres ingénieurs données travaillant avec SQL (Spark SQL ou T-SQL), tous travaillant sur la même copie des données. Fabric permet à ces différents groupes, avec une expérience et des préférences variées, de travailler et de collaborer. Les deux approches différentes transforment et génèrent des agrégats métier. Vous pouvez choisir celle qui vous convient ou combiner ces approches en fonction de vos préférences sans compromettre les performances :
Approche 1 : Utilisez PySpark pour joindre et agréger des données pour générer des agrégats d’entreprise. Cette approche est préférable à une personne ayant un arrière-plan de programmation (Python ou PySpark).
Approche 2 : Utilisez Spark SQL pour joindre et agréger des données pour générer des agrégats d’entreprise. Cette approche est préférable à une personne ayant l’arrière-plan SQL, qui passe à Spark.
Approche 1 (sale_by_date_city) : utilisez PySpark pour joindre et agréger des données pour générer des agrégats d’entreprise. Avec le code suivant, vous créez trois dataframes Spark différentes, chacune référençant une table Delta existante. Vous joignez ensuite ces tables à l’aide des cadres de données, vous effectuez des regroupements pour générer des agrégations, vous renommez quelques colonnes et vous écrivez enfin une table Delta dans la section Tables de la base de données pour qu’elle persiste avec les données.
Dans cette cellule, vous créez trois dataframes Spark différentes, chacune référençant une table Delta existante.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Dans cette cellule, vous joignez ces tables à l’aide des cadres de données créés précédemment, vous effectuez un regroupement par pour générer une agrégation, vous renommez quelques colonnes et enfin vous l’écrivez en tant que table Delta dans la section Tables du lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Approche 2 (sale_by_date_employee) : utilisez Spark SQL pour joindre et agréger des données pour générer des agrégats d’entreprise. Avec le code suivant, vous créez une vue Spark temporaire en joignant trois tables, en effectuant un Regrouper par pour générer une agrégation et en renommant quelques colonnes. Enfin, vous lisez à partir de la vue Spark temporaire et vous l’écrivez enfin sous la forme d’une table Delta dans la section Tables du lakehouse pour conserver les données.
Dans cette cellule, vous créez une vue Spark temporaire en joignant trois tables, effectuez un Regrouper par pour générer l’agrégation et renommez quelques-unes des colonnes.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCDans cette cellule, vous lisez à partir de la vue Spark temporaire créée dans la cellule précédente, puis vous l’écrivez en tant que table Delta dans la section Tables du lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Pour valider les tables créées, cliquez avec le bouton droit et sélectionnez Actualiser sur le lakehouse wwilakehouse. Les tables d’agrégation s’affichent.
Les deux approches produisent un résultat similaire. Afin de réduire le besoin d’apprendre une nouvelle technologie ou de compromettre les performances, choisissez l’approche qui correspond au mieux à votre arrière-plan et à vos préférences,
Vous pouvez remarquer que vous écrivez des données sous forme de fichiers Delta lake. La fonctionnalité automatique de découverte et d’inscription de tables de Fabric les récupère et les inscrit dans le metastore. Vous n’avez pas besoin d’appeler CREATE TABLE explicitement des instructions pour créer des tables à utiliser avec SQL.