Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous découvrirez comment entraîner plusieurs modèles Machine Learning afin de sélectionner le meilleur capable de prédire l’attrition des clients d’une banque.
Dans ce didacticiel, vous allez :
- Entraînez des modèles de forêts d’arbres décisionnels et LightGBM.
- Utilisez l’intégration native de Microsoft Fabric à l’infrastructure MLflow pour journaliser les modèles Machine Learning entraînés, les hyperparamètres utilisés et les métriques d’évaluation.
- Enregistrez le modèle Machine Learning entraîné.
- Évaluez les performances des modèles Machine Learning entraînés sur le jeu de données de validation.
MLflow est une plateforme open source qui permet de gérer le cycle de vie du Machine Learning et comprend des fonctionnalités telles que Suivi, Modèles et Registre de modèles. MLflow est intégrée en mode natif à l’expérience Fabric Data Science.
Prérequis
Obtenir un abonnement Microsoft Fabric. Ou, inscrivez-vous pour un essai gratuit de Microsoft Fabric.
Connectez-vous à Microsoft Fabric.
Basculez vers Fabric à l’aide du sélecteur d’expérience situé en bas à gauche de votre page d’accueil.
Il s’agit de la partie 3 sur 5 de la série de tutoriels. Pour suivre ce didacticiel, commencez par les étapes ci-dessous :
- Partie 1 : Ingérer des données dans un lakehouse Microsoft Fabric à l’aide d’Apache Spark.
- Partie 2 : Explorer et visualiser les données à l’aide des notebooks Microsoft Fabric pour en savoir plus sur les données.
Suivez dans le notebook
3-train-evaluate.ipynb est le notebook qui accompagne ce tutoriel.
Pour ouvrir le bloc-notes associé pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données pour importer le bloc-notes dans votre espace de travail.
Si vous préférez copier et coller le code de cette page, vous pouvez créer un nouveau notebook.
Assurez-vous d’attacher un lakehouse au notebook avant de commencer à exécuter du code.
Important
Attachez le même lakehouse que vous avez utilisé dans les parties 1 et 2.
Installer des bibliothèques personnalisées
Pour ce notebook, vous installerez imbalanced-learn (importé en tant que imblearn) à l’aide de %pip install. imbalanced-learn est une bibliothèque pour la technique SMOTE (Synthetic Minority Oversampling Technique), utilisée pour traiter les jeux de données déséquilibrés. Le noyau PySpark est redémarré après %pip install. Par conséquent, nous devons installer la bibliothèque avant d’exécuter d’autres cellules.
Vous accéderez à SMOTE à l’aide de la bibliothèque imblearn. Installez-la maintenant à l’aide des fonctionnalités d’installation en ligne (par exemple %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Important
Effectuez cette installation chaque fois que vous redémarrez le notebook.
Lorsque vous installez une bibliothèque dans un notebook, elle est disponible uniquement pendant la durée de la session de notebook et non dans l’espace de travail. Si vous redémarrez le notebook, vous devez réinstaller la bibliothèque.
Si vous disposez d’une bibliothèque que vous utilisez souvent et que vous souhaitez la rendre disponible pour tous les notebooks de votre espace de travail, vous pouvez utiliser un environnement Fabric à cet effet. Vous pouvez créer un environnement et y installer la bibliothèque. Ensuite, l’administrateur de votre espace de travail peut attacher l’environnement à l’espace de travail en tant qu’environnement par défaut. Pour plus d’informations sur la définition d’un environnement en tant qu’environnement par défaut de l’espace de travail, consultez L’administrateur définit les bibliothèques par défaut de l’espace de travail.
Pour plus d’informations sur la migration des bibliothèques d’espace de travail existantes et des propriétés Spark vers un environnement, consultez Migrer des bibliothèques d’espace de travail et des propriétés Spark vers un environnement par défaut.
Chargement des données
Avant d’entraîner un modèle Machine Learning, vous devez charger la table delta à partir du lakehouse afin de lire les données nettoyées que vous avez créées dans le notebook précédent.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Générer une expérience pour le suivi et la journalisation du modèle à l’aide de MLflow
Cette section montre comment générer une expérience, spécifier les paramètres de modèles Machine Learning et d’entraînement ainsi que les métriques de scoring, entraîner les modèles Machine Learning, les journaliser et enregistrer les modèles ainsi entraînés pour une utilisation ultérieure.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
L’extension des fonctionnalités de synchronisation automatique MLflow fonctionne en capturant automatiquement les valeurs des paramètres d’entrée et des métriques de sortie d’un modèle Machine Learning tel qu’il est entraîné. Ces informations sont ensuite consignées dans votre espace de travail, où elles sont accessibles et visualisées à l’aide des API MLflow ou de l’expérience correspondante dans votre espace de travail.
Toutes les expériences avec leurs noms respectifs sont journalisées et vous serez en mesure de suivre leurs paramètres et métriques de performances. Pour en savoir plus sur l’autologging, consultez Autologging dans Microsoft Fabric.
Définir des spécifications d’expérience et d’autologging
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Importer scikit-learn et LightGBM
Avec vos données en place, vous pouvez maintenant définir les modèles Machine Learning. Vous allez appliquer des modèles de forêt aléatoire et LightGBM dans ce notebook. Utilisez scikit-learn et lightgbm pour implémenter les modèles dans quelques lignes de code.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Préparer des jeux de données d’entraînement, de validation et de test
Utilisez la fonction train_test_split de scikit-learn pour fractionner les données en jeux de données d’entraînement, de validation et de test.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Enregistrer des données de test dans une table delta
Enregistrez les données de test dans la table delta en vue de les utiliser dans le notebook suivant.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Appliquer SMOTE aux données d’apprentissage pour synthétiser de nouveaux échantillons pour la classe minoritaire
L’exploration des données dans la partie 2 a montré que sur les 10 000 points de données correspondant à 10 000 clients, seuls 2 037 clients (environ 20 %) ont quitté la banque. Cela signifie que le jeu de données est très déséquilibré. Le problème avec la classification déséquilibrée est qu’il y a trop peu d’exemples de la classe minoritaire pour qu’un modèle apprenne efficacement la limite de décision. La SMOTE est l’approche la plus largement utilisée pour synthétiser de nouveaux échantillons pour la classe minoritaire. En savoir plus sur SMOTE ici et ici.
Conseil
Notez que la technique SMOTE ne doit être appliquée qu’au jeu de données d’entraînement. Vous devez laisser le jeu de données de test dans sa distribution déséquilibrée d’origine afin d’obtenir une approximation valide du comportement du modèle Machine Learning sur les données d’origine, ce qui représente la situation en production.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Conseil
Vous pouvez ignorer sans risque le message d’avertissement MLflow qui s’affiche lorsque vous exécutez cette cellule.
Si vous voyez un message ModuleNotFoundError, vous avez oublié d’exécuter la première cellule de ce notebook, qui installe la bibliothèque imblearn. Vous devez réinstaller cette bibliothèque chaque fois que vous redémarrez le notebook. Revenez en arrière et réexécutez toutes les cellules à partir de la première de ce notebook.
Apprentissage du modèle
- Entraîner le modèle à l’aide de la forêt d’arbres décisionnels avec une profondeur maximale de 4 et 4 caractéristiques
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Entraîner le modèle à l’aide de la forêt d’arbres décisionnels avec une profondeur maximale de 8 et 6 caractéristiques
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Entraîner le modèle à l’aide de LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Artefact d’expérience pour le suivi des performances du modèle
Les exécutions de l’expérience sont automatiquement enregistrées dans l’artefact d’expérience qui peut être trouvé à partir de l’espace de travail. Elles sont nommées en fonction du nom utilisé pour définir l’expérience. Tous les modèles Machine Learning entraînés sont journalisés, de même que leurs exécutions, leurs métriques de performances et leurs paramètres de modèles.
Pour afficher vos expériences :
Dans le volet gauche, sélectionnez votre espace de travail.
En haut à droite, filtrez pour afficher uniquement les expériences, afin de faciliter la recherche de celle que vous recherchez.
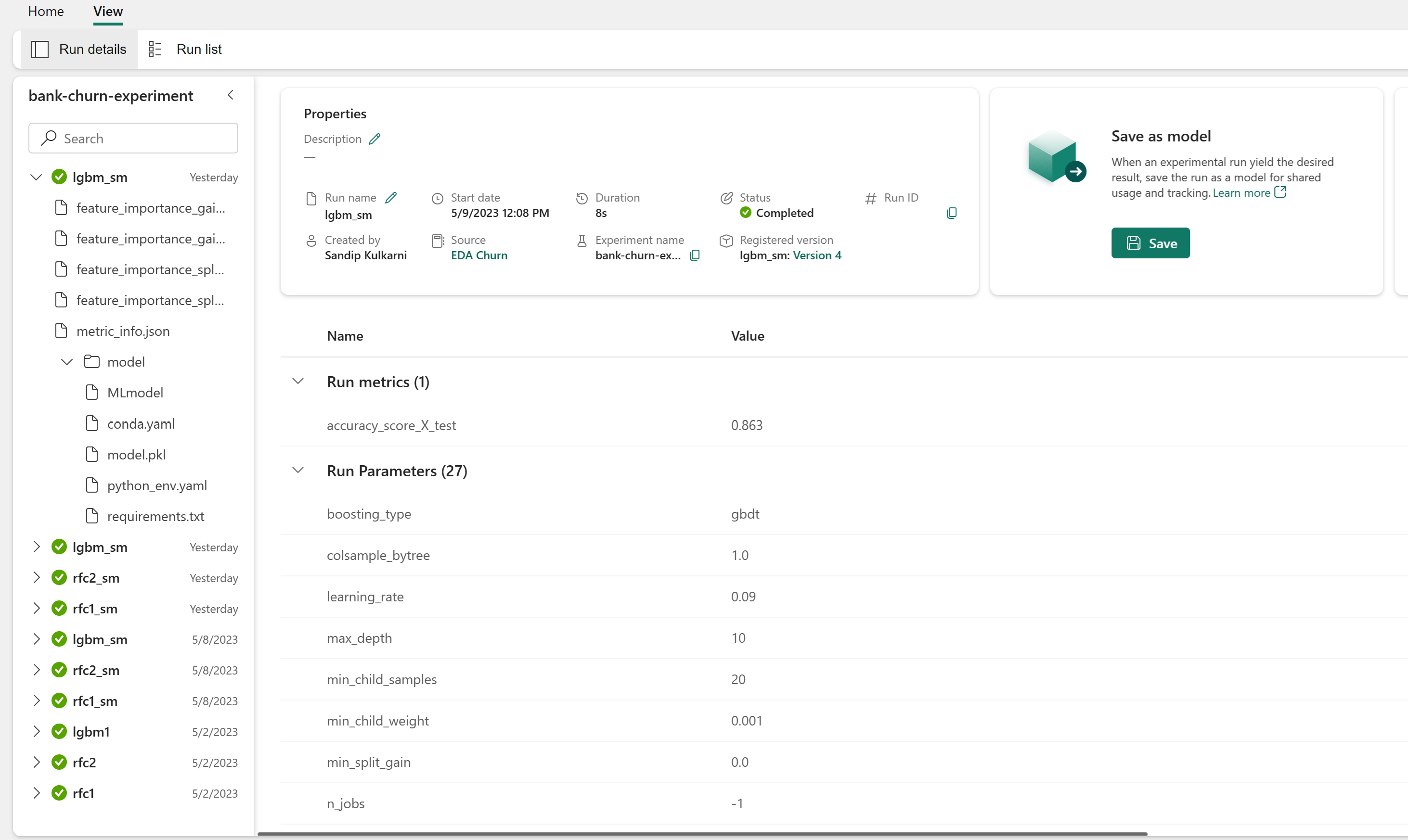
Recherchez et sélectionnez le nom de l’expérience. Dans ce cas bank-churn-experiment. Si l’expérience n’apparaît pas dans votre espace de travail, actualisez votre navigateur.


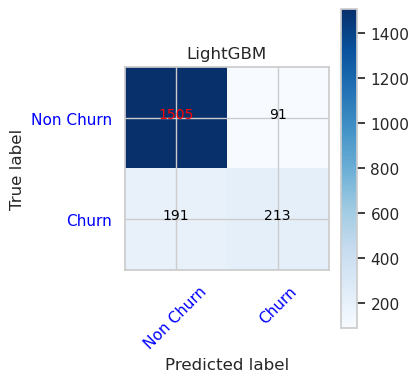
Évaluer les performances des modèles entraînés sur le jeu de données de validation
Une fois l’apprentissage de modèles Machine Learning terminé, vous pouvez évaluer les performances des modèles entraînés de deux manières.
Ouvrez l’expérience enregistrée à partir de l’espace de travail, chargez les modèles Machine Learning, puis évaluez les performances des modèles ainsi chargés sur le jeu de données de validation.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMÉvaluez directement les performances des modèles Machine Learning entraînés sur le jeu de données de validation.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Selon vos préférences, l’une ou l’autre approche est correcte et doit fournir des performances identiques. Dans ce notebook, vous allez choisir la première approche afin de mieux illustrer les fonctionnalités de journalisation automatique MLflow dans Microsoft Fabric.
Afficher les valeurs Vrais/Faux positifs/Négatifs à l’aide de la matrice de confusion
Ensuite, vous développerez un script pour tracer la matrice de confusion afin d’évaluer la précision de la classification à l’aide du jeu de données de validation. La matrice de confusion peut également être tracée à l’aide d’outils SynapseML. Cela est illustré dans l’exemple Détection des fraudes disponible ici.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
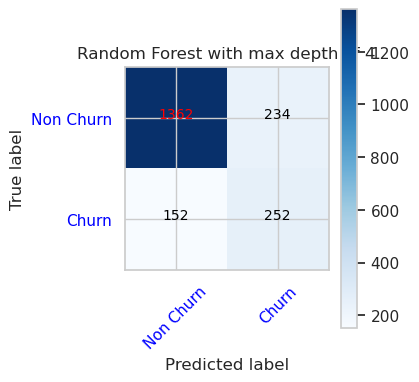
- Matrice de confusion pour l’outil de classification de la forêt d’arbres décisionnels avec une profondeur maximale de 4 et 4 caractéristiques
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
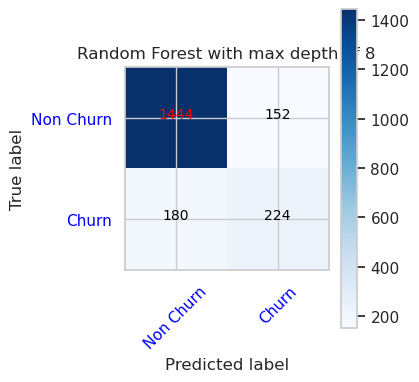
- Matrice de confusion pour l’outil de classification de la forêt d’arbres décisionnels avec une profondeur maximale de 8 et 6 caractéristiques
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
- Matrice de confusion pour LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()