Intégrer OneLake à Azure Databricks
Ce scénario montre comment se connecter à OneLake via Azure Databricks. Après avoir terminé ce didacticiel, vous serez en mesure de lire et d’écrire dans un Lakehouse Microsoft Fabric à partir de votre espace de travail Azure Databricks.
Prérequis
Avant de vous connecter, vous devez avoir :
- Un lakehouse et un espace de travail Fabric.
- Un espace de travail Azure Databricks Premium. Seuls les espaces de travail Azure Databricks premium prennent en charge la transmission des informations d’identification Microsoft Entra, dont vous avez besoin pour ce scénario.
Configuration de votre espace de travail Databricks
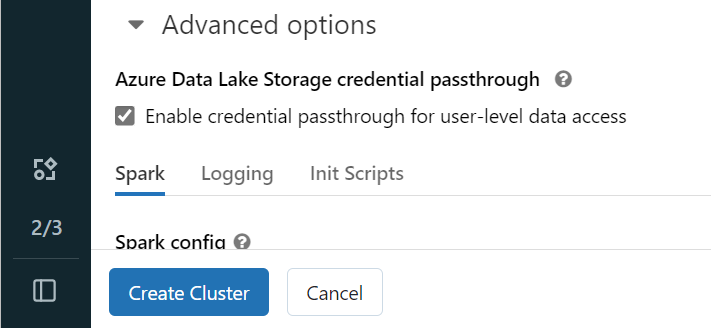
Ouvrez votre espace de travail Azure Databricks et sélectionnez Créer>Cluster.
Pour vous authentifier auprès de OneLake avec votre identité Microsoft Entra, vous devez activer la transmission des informations d'identification Azure Data Lake Storage (ADLS) sur votre cluster dans les options avancées.
Remarque
Vous pouvez également connecter Databricks à OneLake en utilisant un principal de service. Pour obtenir plus d’informations sur l’authentification d’Azure Databricks en utilisant un principal de service, consultez Gérer les principaux de service.
Créer le cluster avec vos paramètres favoris. Si vous souhaitez obtenir plus d’informations sur la création d’un cluster Databricks, consultez Configurer des clusters – Azure Databricks.
Ouvrez un notebook et connectez-le à votre cluster nouvellement créé.
Créer votre notebook
Accédez à votre Lakehouse Fabric et copiez le chemin du système de fichiers Azure Blob (ABFS) vers votre Lakehouse. Vous le trouverez dans le volet Propriétés.
Remarque
Azure Databricks prend uniquement en charge le pilote Azure Blob Filesystem (ABFS) lors de la lecture et de l'écriture sur ADLS Gen2 et OneLake :
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Enregistrez le chemin d’accès à votre instance lakehouse dans votre notebook Databricks. C'est dans cette maison du lac que vous écrivez plus tard vos données traitées :
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Charger des données d’un jeu de données public Databricks dans un DataFrame. Vous pouvez également lire un fichier à partir d’un autre emplacement dans Fabric ou choisir un fichier à partir d’un autre compte ADLS Gen2 que vous possédez déjà.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Filtrez, transformez ou préparez vos données. Pour ce scénario, vous pouvez réduire votre jeu de données pour un chargement plus rapide, joindre d’autres jeux de données ou filtrer des résultats spécifiques.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Écrivez votre trame de données filtrée dans votre Lakehouse Fabric en utilisant votre chemin OneLake.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Vérifiez que vos données ont été correctement écrites en lisant votre fichier nouvellement chargé.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Félicitations ! Vous pouvez désormais lire et écrire des données dans Fabric en utilisant Azure Databricks.