Obtenir des données à partir d’Azure Event Hubs
Dans cet article, vous allez apprendre à obtenir des données d’Event Hubs vers votre base de données KQL dans Microsoft Fabric. Azure Event Hubs est une plateforme de streaming Big Data et un service d’ingestion d’événements, capable de recevoir et de traiter des millions d’événements par seconde.
Pour diffuser des données d’Event Hubs en continu vers Real-Time Intelligence, vous effectuez deux étapes principales. La première étape est effectuée dans le portail Azure, où vous définissez la stratégie d’accès partagé sur votre instance Event Hub et capturez les détails nécessaires pour vous connecter ultérieurement via cette stratégie.
La seconde étape a lieu dans Real-Time Intelligence dans Fabric, où vous connectez une base de données KQL au Event Hub et configurez le schéma pour les données entrantes. Cette étape crée deux connexions. La première connexion, appelée « connexion cloud », connecte Microsoft Fabric à l’instance Event Hub. La seconde connexion connecte la « connexion cloud » à votre base de données KQL. Une fois que vous avez terminé de configurer les données d’événement et le schéma, les données diffusées en continu sont disponibles pour être interrogées à l’aide d’un ensemble de requêtes KQL.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit
- Un Event Hub
- Un espace de travail avec une capacité compatible Microsoft Azure Fabric
- Une base de données KQL avec des autorisations de modification
Avertissement
Votre Event Hub ne peut pas se trouver derrière un pare-feu.
Définir une stratégie d’accès partagé sur votre Event Hub
Avant de pouvoir créer une connexion à vos données Event Hubs, vous devez définir une stratégie d’accès partagé (SAP) sur le Event Hub et collecter des informations à utiliser ultérieurement pour configurer la connexion. Pour plus d’informations sur l’autorisation de l’accès aux ressources Event Hubs, consultez l’article Signatures d’accès partagé.
Dans le portail Azure, accédez à l’instance Event Hubs que vous souhaitez connecter.
Sous Paramètres, sélectionnez Stratégies d’accès partagé.
Sélectionnez + Ajouter pour ajouter une nouvelle stratégie SAP ou sélectionnez une stratégie existante avec les autorisations Gérer.

Entrez un nom de stratégie.
Sélectionnez Gérer, puis Créer.

Collecter des informations pour la connexion cloud
Dans le volet de la stratégie SAP, notez les quatre champs suivants. Vous pouvez copier ces champs et les coller quelque part, comme un bloc-notes, pour pouvoir les utiliser ultérieurement.

| Référence de champ | Champ | Description | Exemple : |
|---|---|---|---|
| a | Instance Event Hubs | Nom de l’instance Event Hub. | iotdata |
| b | Stratégie SAP | Nom de la stratégie SAP créée à l’étape précédente. | DocsTest |
| c | Clé primaire | Clé associée à la stratégie SAP. | Dans cet exemple, la clé commence par PGGIISb009... |
| d | Chaîne de connexion—clé primaire | Dans ce champ, vous ne pouvez copier que l’espace de noms Event Hub, qui se trouve dans la chaîne de connexion. | eventhubpm15910.servicebus.windows.net |
Source
Dans le ruban inférieur de votre base de données KQL, sélectionnez Obtenir des données.
Dans la fenêtre Obtenir des données, l’onglet Source est sélectionné.
Sélectionnez la source de données dans la liste disponible. Dans cet exemple, vous ingérez des données à partir d’Events Hubs.


Configurer
Sélectionner la table cible. Si vous souhaitez ingérer des données dans une nouvelle table, sélectionnez +Nouvelle table et entrez un nom de table.
Remarque
Les noms de tables peuvent comporter jusqu’à 1024 caractères, y compris des espaces, des caractères alphanumériques, des traits d’union et des traits de soulignement. Les caractères spéciaux ne sont pas pris en charge.
Sélectionnez Créer une nouvelle connexion, ou sélectionnez une Connexion existante et passez à l’étape suivante.
Créer une connexion
Entrez les paramètres de connexion en fonction du tableau suivant :
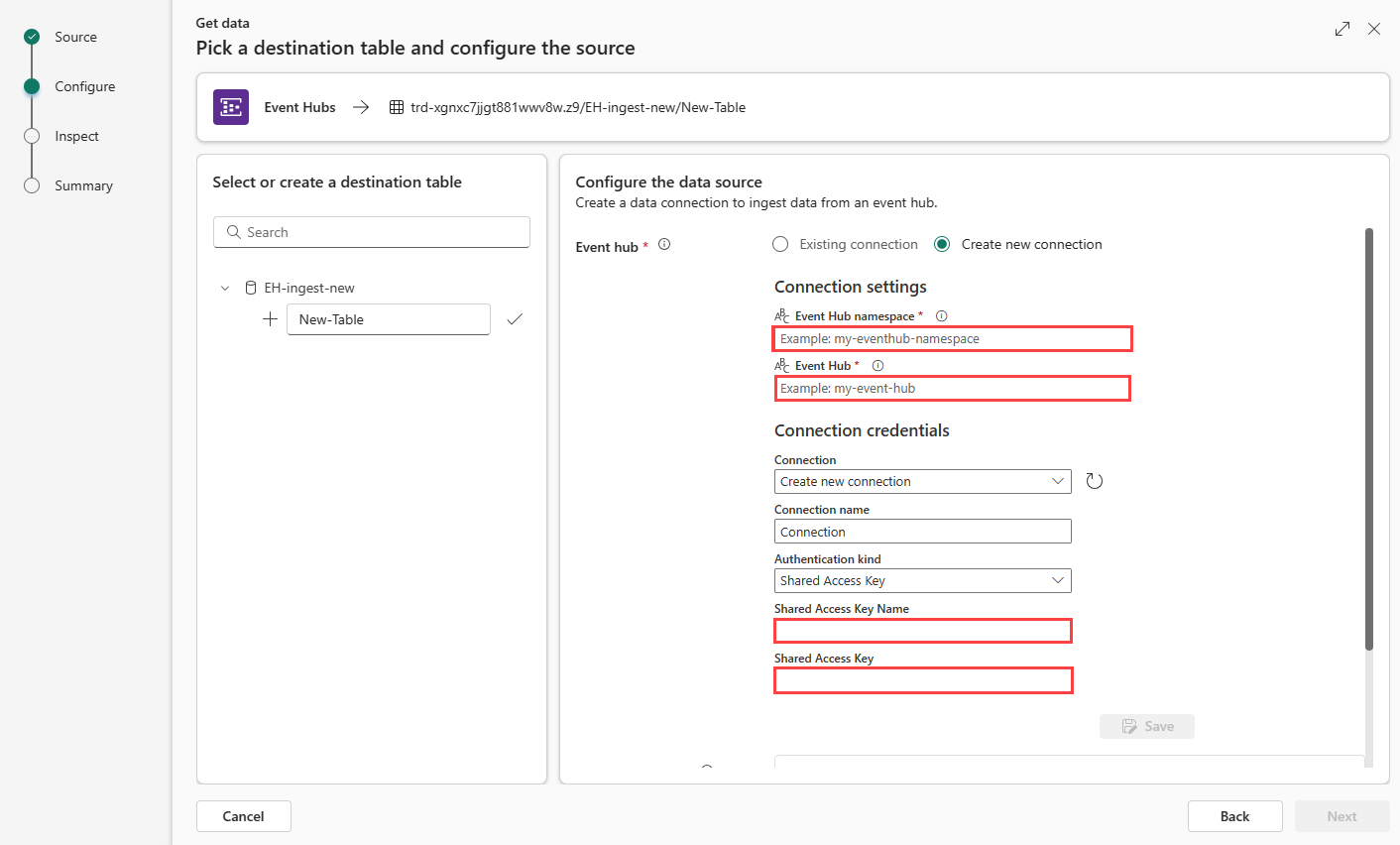
Paramètre Description Exemple de valeur Espace de noms du hub d’événements Champ d du tableau ci-dessus. eventhubpm15910.servicebus.windows.net Hub d’événements Champ a du tableau ci-dessus. Nom de l’instance Event Hub. iotdata Connexion Pour utiliser une connexion cloud existante entre Fabric et Event Hubs, sélectionnez le nom de cette connexion. Sinon, sélectionnez Créer une connexion. Créer une connexion Nom de la connexion Nom de votre nouvelle connexion cloud. Ce nom est généré automatiquement, mais vous pouvez le remplacer. Il doit être unique au sein du locataire Fabric. Connection Type d'authentification Rempli automatiquement. Actuellement, seule la valeur Clé d’accès partagé est prise en charge. Clé d’accès partagé Nom de la clé d’accès partagé Champ b du tableau ci-dessus. Nom que vous avez donné à la stratégie d’accès partagé. DocsTest Clé d’accès partagé Champ c du tableau ci-dessus. Clé primaire de la stratégie SAP. Cliquez sur Enregistrer. Une connexion de données cloud entre Fabric et Event Hubs est créée.

Connecter la connexion cloud à votre base de données KQL
Que vous ayez créé une connexion cloud ou que vous utilisiez une connexion existante, vous devez définir le groupe de consommateurs. Vous pouvez éventuellement définir des paramètres qui définissent davantage les aspects de la connexion entre la base de données KQL et la connexion cloud.
Renseignez les champs suivants en fonction du tableau :
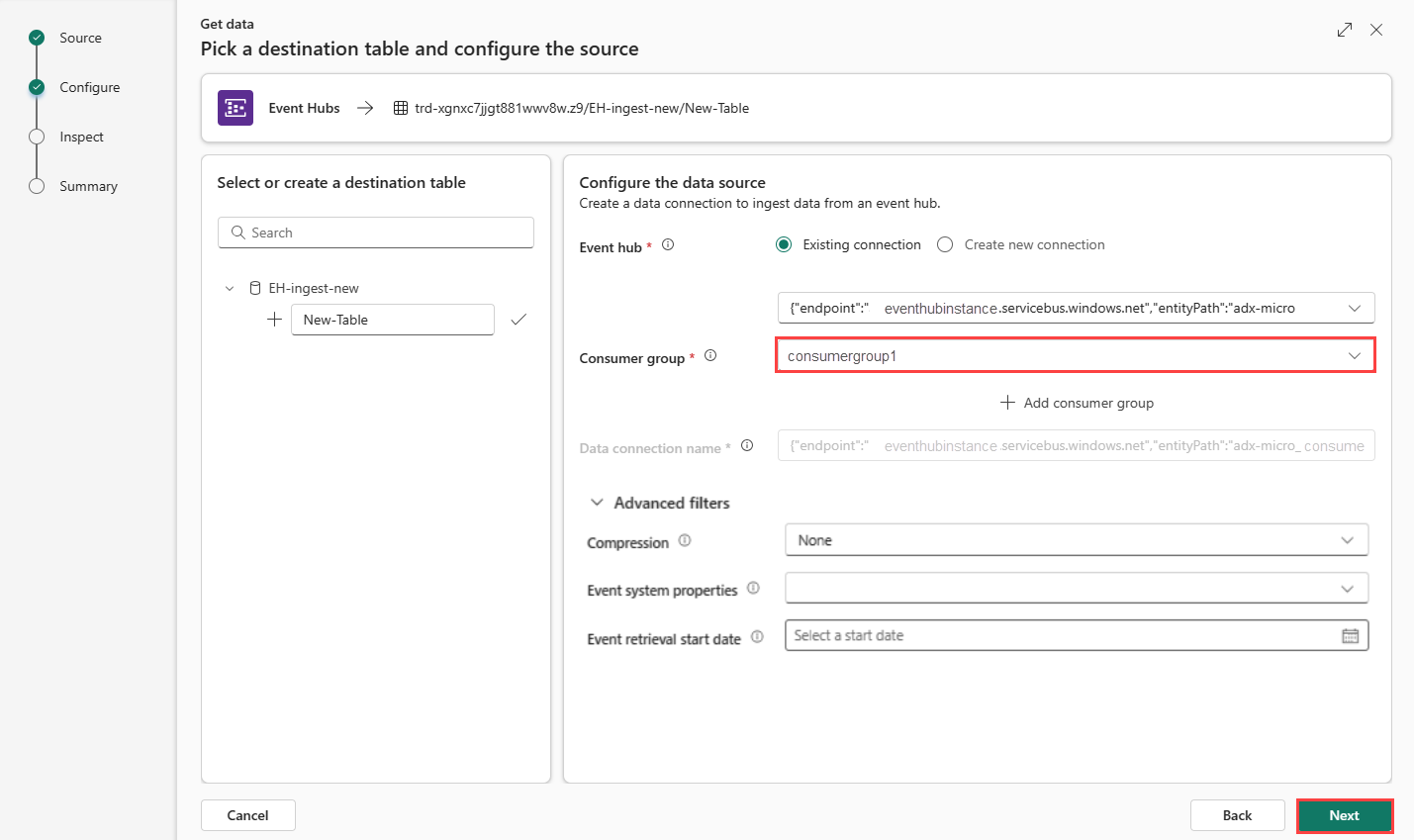
Paramètre Description Exemple de valeur Groupe de consommateurs Groupe de consommateurs pertinent défini dans votre Event Hub. Pour plus d’informations, consultez la section sur les groupes de consommateurs. Après avoir ajouté un nouveau groupe de consommateurs, vous devez sélectionner ce groupe dans la liste déroulante. NewConsumer Autres paramètres Compression Compression des données des événements provenant du Event Hub. Les options sont Aucune (valeur par défaut) ou GZip. Aucun Propriétés du système d’événements Pour plus d’informations, consultez les propriétés du système Event Hub. S’il existe plusieurs enregistrements par message d’événement, les propriétés système sont ajoutées au premier enregistrement. Consultez la section Propriétés du système d’événements. Date de début de la récupération d’événement La connexion de données récupère les événements Event Hub existants créés depuis la date de début de la récupération d’événements. Elle peut uniquement récupérer les événements conservés par le Event Hub en fonction de sa période de rétention. Le fuseau horaire est UTC. Si aucune heure n’est spécifiée, l’heure par défaut correspond à l’heure de création de la connexion de données. Sélectionnez Suivant pour passer à l’onglet Inspecter l’onglet.
Propriétés du système d’événements
Les propriétés système stockent les propriétés définies par le service Event Hubs au moment de la mise en file d’attente de l’événement. La connexion de données au hub d’événements peut incorporer un ensemble sélectionné de propriétés système dans les données ingérées dans une table en fonction d’un mappage donné.
| Propriété | Type de données | Description |
|---|---|---|
| x-opt-enqueued-time | datetime | Heure UTC à laquelle l’événement a été mis en file d’attente. |
| x-opt-sequence-number | long | Numéro de séquence logique de l’événement dans le flux de partition du Event Hub. |
| x-opt-offset | string | Décalage de l’événement par rapport au flux de partition du hub d’événements. L’identificateur de décalage est unique au sein d’une partition du flux du Event Hub. |
| x-opt-publisher | string | Nom de l’éditeur, si le message a été envoyé à un point de terminaison d’éditeur. |
| x-opt-partition-key | string | Clé de partition de la partition correspondante qui a stocké l’événement. |
Inspecter
Pour terminer le processus d’ingestion, sélectionnez Terminer.

Si vous le souhaitez :
Sélectionnez Visionneuse de commandes pour afficher et copier les commandes automatiques générées à partir de vos entrées.
Modifiez le format de données déduit automatiquement en sélectionnant le format souhaité dans la liste déroulante. Les données sont lues à partir du hub d’événements sous forme d’objets EventData. Les formats pris en charge sont CSV, JSON, PSV, SCsv, SOHsv TSV, TXT et TSVE.
Explorez les options avancées basées sur le type de données.
Si les données que vous voyez dans la fenêtre d’aperçu sont incomplètes, il est possible que vous ayez besoin de davantage de données pour créer une table avec tous les champs de données nécessaires. Utilisez les commandes suivantes pour récupérer de nouvelles données auprès de votre hub d’événements :
- Ignorer et récupérer de nouvelles données : ignore les données présentées et recherche les nouveaux événements.
- Récupérer plus de données : recherche d’autres événements, en plus de ceux déjà trouvés.
Modifier les colonnes
Remarque
- Pour les formats tabulaires (CSV, TSV, PSV), vous ne pouvez pas mapper deux fois une même colonne. Pour effectuer un mappage à une colonne existante, commencez par supprimer la nouvelle colonne.
- Vous ne pouvez pas changer un type de colonne existant. Si vous essayez de mapper à une colonne avec un format différent, vous risquez de vous retrouver avec des colonnes vides.
Les modifications que vous pouvez apporter dans une table dépendent des paramètres suivants :
- Si le type de la table est nouveau ou existant
- Si le type du mappage est nouveau ou existant
| Type de la table | Type de mappage | Ajustements disponibles |
|---|---|---|
| Nouvelle table | Nouveau mappage | Renommer une colonne, modifier le type de données, modifier la source de données, transformation de mappage, ajouter une colonne, supprimer une colonne |
| Table existante | Nouveau mappage | Ajoutez une colonne (vous pourrez ensuite modifier le type de données, la renommer ou la mettre à jour) |
| Table existante | Mappage existant | Aucune |

Mappage des transformations
Certains mappages de format de données (Parquet, JSON et Avro) prennent en charge des transformations simples au moment de l’ingestion. Pour appliquer des transformations de mappage, créez ou mettez à jour une colonne dans la fenêtre Modifier les colonnes.
Les transformations de mappage peuvent être effectuées sur une colonne de type string ou datetime, avec la source dont le type de données est int ou long. Les transformations de mappage prises en charge sont :
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Mise en correspondance du schéma pour les fichiers Event Hub Capture Avro
Une façon de consommer des données Event Hubs consiste à capturer des événements via Azure Event Hubs dans Stockage Blob Azure ou Azure Data Lake Storage. Vous pouvez ensuite ingérer les fichiers de capture au fur et à mesure qu’ils sont écrits à l’aide d’une connexion de données Event Grid.
Le schéma des fichiers de capture est différent du schéma de l’événement d’origine envoyé à Event Hubs. Vous devez concevoir le schéma de table de destination en gardant à l’esprit cette différence. Plus précisément, la charge utile d’événement est représentée dans le fichier de capture en tant que tableau d’octets et ce tableau n’est pas décodé automatiquement par la connexion de données Azure Data Explorer Event Grid. Pour plus d’informations sur le schéma de fichier pour les données de capture Event Hubs Avro, consultez Explorer les fichiers Avro capturés dans Azure Event Hubs.
Pour décoder correctement la charge utile de l’événement :
- Mappez le champ
Bodyde l’événement capturé à une colonne de typedynamicdans la table de destination. - Appliquez une stratégie de mise à jour qui convertit le tableau d’octets en chaîne lisible à l’aide de la fonction unicode_codepoints_to_string().
Options avancées basées sur le type de données
Tabulaire (CSV, TSV, PSV) :
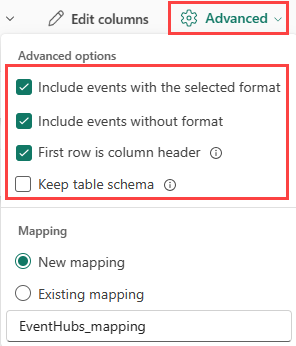
Si vous ingérez des formats tabulaires dans une table existante, vous pouvez sélectionner Avancé>Conserver le schéma de table. Les données tabulaires n’incluent pas nécessairement les noms de colonnes utilisés pour mapper les données sources aux colonnes existantes. Quand cette option est activée, le mappage est effectué dans l’ordre et le schéma de la table reste le même. Si cette option est désactivée, des colonnes sont créées pour les données entrantes, quelle que soit la structure de données.
Pour utiliser la première ligne comme noms de colonnes, sélectionnez Avancé>La première ligne est l’en-tête de colonne.
JSON :
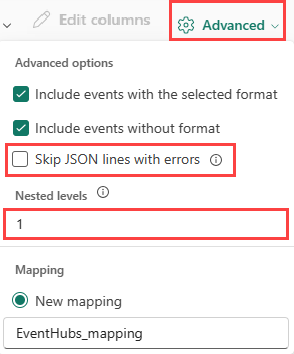
Pour déterminer la division de colonnes des données JSON, sélectionnez Avancé>Niveaux imbriqués, de 1 à 100.
Si vous sélectionnez Avancé>Ignorer les lignes contenant des erreurs, les données sont ingérées au format JSON. Si vous laissez cette case à cocher désactivée, les données sont ingérées au format multijson.
Résumé
Dans la fenêtre Préparation des données, les trois étapes sont signalées par des coches vertes quand l’ingestion des données s’est terminée avec succès. Vous pouvez sélectionner une carte à interroger, supprimer les données ingérées ou afficher un tableau de bord de votre résumé d’ingestion.
