Tutoriel : utiliser un notebook avec Apache Spark pour interroger une base de données KQL
Les notebooks sont à la fois des documents lisibles contenant des descriptions et des résultats d’analyse des données, ainsi que des documents exécutables qui peuvent être exécutés pour effectuer une analyse des données. Dans cet article, vous allez apprendre à utiliser un notebook Microsoft Fabric pour lire et écrire des données dans une base de données KQL à l’aide d’Apache Spark. Ce tutoriel utilise des jeux de données et des notebooks précréés dans les environnements Real-Time Intelligence et Ingénieurs de données dans Microsoft Fabric. Pour plus d’informations sur les notebooks, consultez Utilisation des notebooks Microsoft Fabric.
Plus précisément, vous allez découvrir comment :
- Créer une base de données KQL
- Importer un notebook
- Écrire des données dans une base de données KQL à l’aide d’Apache Spark
- Interroger des données à partir d’une base de données KQL
Prérequis
- Un espace de travail avec une capacité compatible Microsoft Fabric
1- Créer une base de données KQL
Sélectionnez votre espace de travail dans la barre de navigation de gauche.
Suivez l’une des étapes suivantes pour commencer à créer un flux d’événements :
- Sélectionnez Nouvel élément, puis Eventhouse. Dans le champ nom de Eventhouse, entrez nycGreenTaxi, puis sélectionnez Créer. Une base de données KQL est générée avec le même nom.
- Dans un lieu d'événement existant, sélectionnez Bases de données. Sous bases de données KQL, sélectionnez +, dans le champ nom de la base de données KQL, entrez nycGreenTaxi, puis sélectionnez Créer.
Copiez l’URI de requête à partir des détails de la base de données carte dans le tableau de bord de la base de données et collez-le quelque part, comme un bloc-notes, pour l’utiliser dans une étape ultérieure.

2- Télécharger le notebook NYC GreenTaxi
Nous avons créé un exemple de notebook qui vous guide tout au long des étapes nécessaires pour charger des données dans votre base de données à l’aide du connecteur Spark.
Ouvrez le référentiel d’exemples Fabric sur GitHub pour télécharger le notebook NYC GreenTaxi KQL.
Enregistrez le notebook localement sur votre appareil.
Remarque
Le notebook doit être enregistré au format de fichier
.ipynb.

3- Importer le notebook
Le reste de ce workflow se produit dans la section Engineering données du produit et utilise un notebook Spark pour charger et interroger des données dans votre base de données KQL.
Dans votre espace de travail, sélectionnez Importer>Notebook>À partir de cet ordinateur>Téléverser, puis choisissez le notebook NYC GreenTaxi que vous avez téléchargé à l’étape précédente.

Une fois l’importation terminée, ouvrez le bloc-notes importé depuis votre espace de travail.
4- Obtenir des données
Pour interroger votre base de données à l’aide du connecteur Spark, vous devez accorder un accès en lecture et en écriture au conteneur d’objets blob NYC GreenTaxi.
Sélectionnez le bouton lecture pour exécuter les cellules suivantes, ou sélectionnez la cellule et appuyez sur Maj + Entrée. Répétez cette étape pour chaque cellule de code.
Remarque
Attendez que la coche d'achèvement apparaisse avant d'exécuter la cellule suivante.
Exécutez la cellule suivante pour activer l’accès au conteneur d’objets blob NYC GreenTaxi.
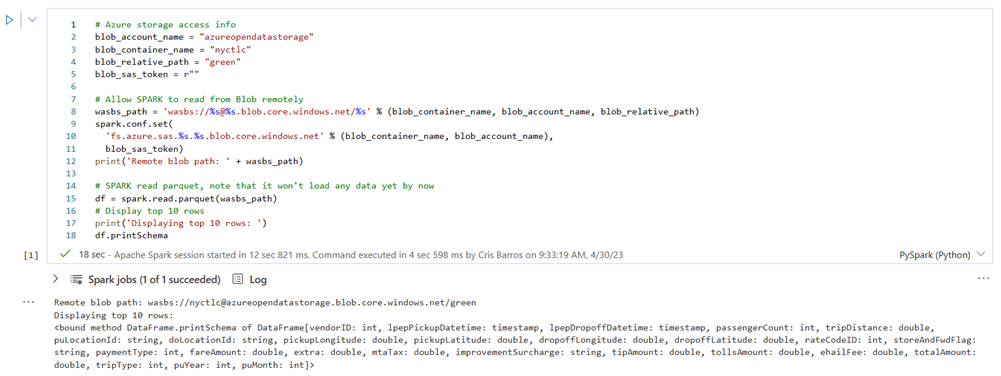
Dans KustoURI, collez l’URI de requête que vous avez copié précédemment au lieu du texte de l’espace réservé.
Remplacez le nom de l’espace réservé de base de données par nycGreenTaxi.
Remplacez le nom de l’espace réservé de table par GreenTaxiData.

Exécutez la cellule.
Exécutez la cellule suivante pour écrire des données dans votre base de données. Attendez quelques minutes que cette étape se termine.




Les données de votre base de données sont désormais chargées dans une table nommée GreenTaxiData.
5- Exécuter le notebook
Exécutez les deux cellules restantes séquentiellement pour interroger les données de votre table. Les résultats montrent les 20 premiers prix de course et distances de taxi les plus élevés et les plus bas enregistrés par année.

6- Nettoyer les ressources
Nettoyez les éléments créés en accédant à l’espace de travail dans lequel ils ont été créés.
Dans votre espace de travail, pointez sur le notebook que vous souhaitez supprimer, sélectionnez le Menu Plus [...] >Supprimer.
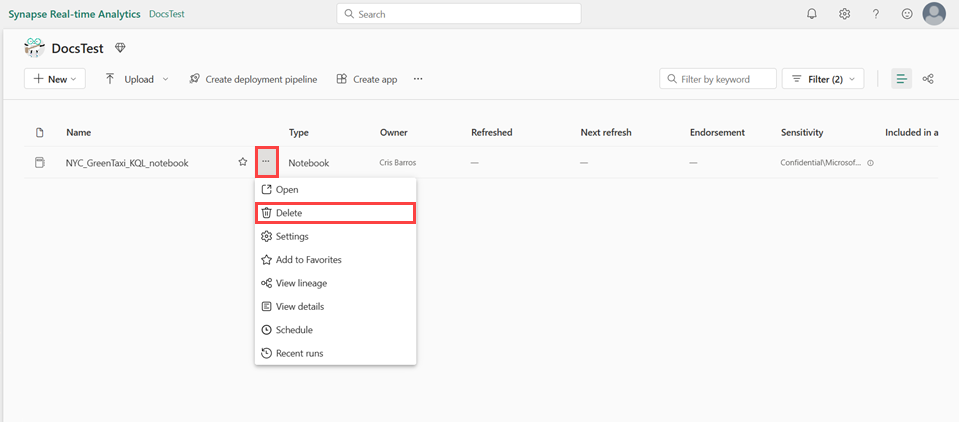
Sélectionnez Supprimer. Vous ne pouvez pas récupérer votre notebook une fois que vous l’avez supprimé.
