Ingérer des données Dataverse exportées avec Azure Data Factory
Après avoir exporté les données de Microsoft Dataverse à Azure Data Lake Storage Gen2 avec Azure Synapse Link for Dataverse, vous pouvez utiliser Azure Data Factory pour créer des Dataflows, transformer vos données et exécuter une analyse.
Notes
Azure Synapse Link for Dataverse était auparavant connu sous le nom d’exportation vers le lac de données. Ce service a été renommé en mai 2021 et continuera d’exporter des données vers Azure Data Lake ainsi que vers Azure Synapse Analytics.
Cet article vous explique comment réaliser les tâches suivantes :
Définissez le compte de stockage Data Lake Storage Gen2 avec les données Dataverse en tant que source dans un dataflow Data Factory.
Transformez les données Dataverse dans Data Factory avec un dataflow.
Définissez le compte de stockage Data Lake Storage Gen2 avec les données Dataverse en tant que réception dans un dataflow Data Factory.
Exécutez votre dataflow en créant un pipeline.
Conditions préalables
Cette section décrit les conditions préalables nécessaires à l’ingestion de données Dataverse avec Data Factory.
Rôles Azure. Le compte d’utilisateur utilisé pour se connecter à Azure doit être membre du rôle collaborateur ou propriétaire, ou un administrateur de l’abonnement Azure. Pour afficher les autorisations dont vous disposez dans l’abonnement, accédez au portail Azure, sélectionnez votre nom d’utilisateur dans le coin supérieur droit, sélectionnez ..., puis Mes autorisations. Si vous avez accès à plusieurs abonnements, sélectionnez celui qui convient. Pour créer et gérer des ressources enfants pour Data Factory dans le portail Azure, y compris les jeux de données, les services liés, les pipelines, les déclencheurs et les environnements d’exécution d’intégration, vous devez appartenir au rôle Contributeur de Data Factory au niveau du groupe de ressources ou supérieur.
Azure Synapse Link for Dataverse. Ce guide suppose que vous avez déjà exporté des données Dataverse en utilisant Azure Synapse Link for Dataverse. Dans cet exemple, les données de la table de comptes sont exportées vers le lac de données.
Azure Data Factory. Ce guide suppose que vous avez déjà créé une fabrique de données sous le même abonnement et le même groupe de ressources que le compte de stockage contenant les données Dataverse exportées.
Définir le compte de stockage Data Lake Storage Gen2 comme source
Ouvrez Azure Data Factory et sélectionnez la fabrique de données qui se trouve sous le même abonnement et le même groupe de ressources que le compte de stockage contenant vos données Dataverse exportées. Sélectionnez ensuite Créer un flux de données depuis la page d’accueil.
Activez le mode Débogage du flux de données et sélectionnez votre heure préférée. Cela peut prendre jusqu’à 10 minutes, mais vous pouvez suivre les étapes suivantes.

Sélectionnez Ajouter une source.

Sous Paramètres de la source, procédez comme suit :
- Nom du flux de sortie : Saisissez le nom souhaité.
- Type de source : sélectionnez En ligne.
- Type jeu de données en ligne : sélectionnez Common Data Model.
- Service lié : Sélectionnez le compte de stockage dans le menu déroulant, puis associez un nouveau service en fournissant les détails de votre abonnement et en laissant toutes les configurations par défaut.
- Échantillonnage : Si vous souhaitez utiliser toutes vos données, sélectionnez Désactiver.
Sous Options de la source, procédez comme suit :
Format des métadonnées : sélectionnez Model.json.
Emplacement racine : saisissez le nom du conteneur dans la première case (Conteneur) ou Parcourir pour le nom du conteneur et sélectionnez OK.
Entité : saisissez le nom de la table ou Parcourir pour la table.

Consultez l’onglet Projection pour vous assurer que votre schéma a bien été importé. Si vous ne voyez aucune colonne, sélectionnez Options de schéma et cochez l’option Déduire les types de colonnes dérivés. Configurez les options de mise en forme pour qu’elles correspondent à votre jeu de données, puis sélectionnez Appliquer.
Vous pouvez consulter vos données dans l’onglet Aperçu des données pour vous assurer que la création de la source était complète et précise.
Transformer vos données Dataverse
Après avoir défini les données Dataverse exportées dans le compte Azure Data Lake Storage Gen2 comme source dans le dataflow Data Factory, il existe de nombreuses possibilités pour transformer vos données. Plus d’information : Azure Data Factory
Suivez ces instructions pour créer un classement pour chaque ligne en fonction du champ revenu de la table du compte.
Sélectionnez + dans le coin inférieur droit de la transformation précédente, puis recherchez et sélectionnez Classement.
Sous l’onglet Paramètres du classement, entrez les informations suivantes :
Nom du flux de sortie : saisissez le nom souhaité, par exemple Classement1.
Flux entrant : sélectionnez le nom de la source souhaitée. Dans ce cas, le nom de la source de l’étape précédente.
Options : laissez les options décochées.
Colonne de classement : saisissez le nom de la colonne de classement générée.
Conditions de tri : sélectionnez la colonne Revenu et triez par ordre Décroissant.

Vous pouvez consulter vos données dans l’onglet aperçu des données où vous trouverez la nouvelle colonne revenuRank à la position la plus à droite.
Définir le compte de stockage Data Lake Storage Gen2 en tant que récepteur
Au final, vous devez définir un récepteur pour votre dataflow. Suivez ces instructions pour placer vos données transformées dans un fichier texte délimité dans le lac de données.
Sélectionnez + dans le coin inférieur droit de la transformation précédente, puis recherchez et sélectionnez Récepteur.
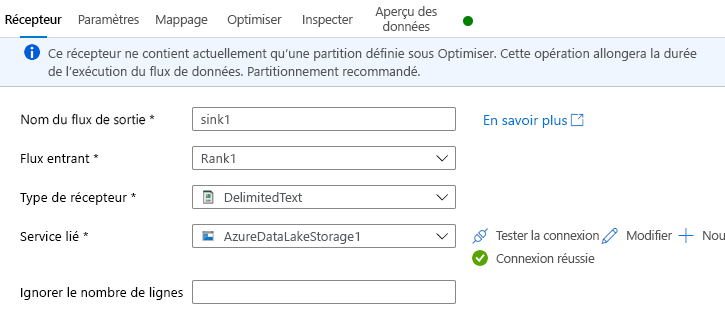
Sous l’onglet Récepteur, effectuez une des opérations ci-dessous :
Nom du flux de sortie : Saisissez le nom souhaité, comme Sink1.
Flux entrant : Sélectionnez le nom de la source souhaité. Dans ce cas, le nom de la source de l’étape précédente.
Type de récepteur : sélectionnez DelimitedText.
Service lié : sélectionnez votre conteneur de stockage Data Lake Storage Gen2 qui contient les données que vous avez exportées à l’aide du service Azure Synapse Link for Dataverse.
Sous l’onglet Paramètres, vous pouvez effectuer les opérations suivantes :
Chemin d’accès du dossier : saisissez le nom du conteneur dans la première case (Système de fichiers) ou Parcourir pour le nom du conteneur et sélectionnez OK.
Option de nom de fichier : sélectionnez sortie dans un seul fichier.
Sortie dans un seul fichier : saisissez un nom de fichier, tel que ADFOutput
Laissez tous les autres paramètres par défaut.

Dans l’onglet Optimiser, définissez l’Option de partition sur Partition unique.
Vous pouvez consulter vos données dans l’onglet Aperçu des données.
Exécuter votre dataflow
Dans le volet gauche sous Ressources Factory, sélectionnez +, puis Pipeline.

Sous Activités, sélectionnez Déplacer et transformer, puis faites glisser Dataflow vers l’espace de travail.
Sélectionnez Utiliser le dataflow existant, puis sélectionnez le dataflow créé aux étapes précédentes.
Sélectionnez Déboguer dans la barre de commandes.
Laissez le dataflow s’exécuter jusqu’à ce que la vue de dessous montre que c’est terminé. Cette opération peut prendre quelques minutes.
Accédez au conteneur de stockage de destination finale et recherchez le fichier de données de table transformé.
Voir aussi
Configurer Azure Synapse Link for Dataverse avec Azure Data Lake
Analyser des données Dataverse dans Azure Data Lake Storage Gen2 avec Power BI
Notes
Pouvez-vous nous indiquer vos préférences de langue pour la documentation ? Répondez à un court questionnaire. (veuillez noter que ce questionnaire est en anglais)
Le questionnaire vous prendra environ sept minutes. Aucune donnée personnelle n’est collectée (déclaration de confidentialité).