TripPin partie 7 - Schéma avancé avec types M
Remarque
Ce contenu fait actuellement référence à celui d’une implémentation héritée pour les tests unitaires dans Visual Studio. Le contenu sera mis à jour dans un futur proche pour couvrir le nouveau cadre de test du Kit de développement logiciel (SDK) Power Query.
Ce tutoriel en plusieurs parties traite de la création d’une extension de source de données pour Power Query. Le tutoriel est destiné à être utilisé de manière séquentielle : chaque leçon s’appuie sur le connecteur créé dans les leçons précédentes, ajoutant de nouvelles fonctionnalités de manière incrémentielle.
Dans cette leçon, vous allez :
- Appliquer un schéma de table à l’aide de Types M
- Définir des types pour les enregistrements et listes imbriqués
- Refactoriser le code pour la réutilisation et les tests unitaires
Dans la leçon précédente, vous avez défini vos schémas de table à l’aide d’un système simple « Table de schémas ». Cette approche de table de schéma fonctionne pour de nombreuses API REST/connecteurs de données, mais les services qui retournent des jeux de données complets ou profondément imbriqués peuvent tirer parti de l’approche de ce didacticiel, qui tire parti du système de type M.
Cette leçon vous guidera à travers les étapes suivantes :
- Ajout de tests unitaires.
- Définition de types M personnalisés.
- Application d’un schéma à l’aide de types.
- Refactorisation du code commun dans des fichiers distincts.
Ajout de tests unitaires
Avant de commencer à utiliser la logique de schéma avancée, vous allez ajouter un ensemble de tests unitaires à votre connecteur pour réduire le risque de rupture accidentelle de quelque chose. Les tests unitaires fonctionnent comme suit :
- Copiez le code commun de l’exemple UnitTest dans votre
TripPin.query.pqfichier. - Ajouter une déclaration de section en haut de votre
TripPin.query.pqfichier. - Créer un enregistrement partagé (appelé
TripPin.UnitTest). - Définir un
Factpour chaque test. - Appel
Facts.Summarize()pour exécuter tous les tests. - Référencez l’appel précédent comme valeur partagée pour vous assurer qu’elle est évaluée lorsque le projet est exécuté dans Visual Studio.
section TripPinUnitTests;
shared TripPin.UnitTest =
[
// Put any common variables here if you only want them to be evaluated once
RootTable = TripPin.Contents(),
Airlines = RootTable{[Name="Airlines"]}[Data],
Airports = RootTable{[Name="Airports"]}[Data],
People = RootTable{[Name="People"]}[Data],
// Fact(<Name of the Test>, <Expected Value>, <Actual Value>)
// <Expected Value> and <Actual Value> can be a literal or let statement
facts =
{
Fact("Check that we have three entries in our nav table", 3, Table.RowCount(RootTable)),
Fact("We have Airline data?", true, not Table.IsEmpty(Airlines)),
Fact("We have People data?", true, not Table.IsEmpty(People)),
Fact("We have Airport data?", true, not Table.IsEmpty(Airports)),
Fact("Airlines only has 2 columns", 2, List.Count(Table.ColumnNames(Airlines))),
Fact("Airline table has the right fields",
{"AirlineCode","Name"},
Record.FieldNames(Type.RecordFields(Type.TableRow(Value.Type(Airlines))))
)
},
report = Facts.Summarize(facts)
][report];
La sélection de l’option Exécuter sur le projet évaluera tous les faits et vous donnera une sortie de rapport qui ressemble à ceci :
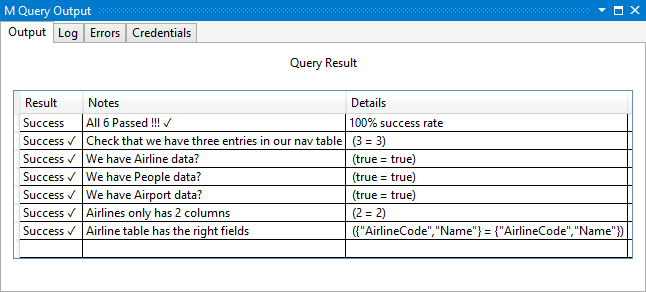
À l’aide de certains principes du développement piloté par les tests, vous allez maintenant ajouter un test qui échoue actuellement, mais sera bientôt réappéré et corrigé (à la fin de ce didacticiel). Plus précisément, vous allez ajouter un test qui vérifie l’un des enregistrements imbriqués (e-mails) que vous revenez dans l’entité Contacts.
Fact("Emails is properly typed", type text, Type.ListItem(Value.Type(People{0}[Emails])))
Si vous réexécutez le code, vous devriez maintenant voir que vous avez un test défaillant.
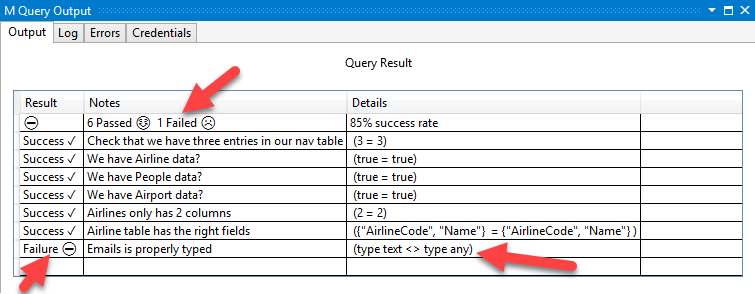
Maintenant, vous devez simplement implémenter les fonctionnalités pour que ce travail fonctionne.
Définition de types M personnalisés
L’approche d’application du schéma dans la leçon précédente a utilisé des « tables de schéma » définies comme paires Nom/Type. Il fonctionne bien lors de l’utilisation de données aplatis/relationnelles, mais ne prend pas en charge les types de paramètres sur les enregistrements/tables/listes imbriqués, ou vous permet de réutiliser les définitions de type entre les tables/entités.
Dans le cas TripPin, les données des entités People and Airports contiennent des colonnes structurées, et partagent même un type (Location) pour représenter les informations d’adresse. Au lieu de définir des paires Nom/Type dans une table de schéma, vous allez définir chacune de ces entités à l’aide de déclarations de type M personnalisées.
Voici une mise à jour rapide sur les types en langage M à partir de la spécification de langage :
Une valeur de type est une valeur qui classifie d’autres valeurs. Une valeur classifiée par un type est dite conforme à ce type. Le système de type M se compose des genres de types suivants :
- Types primitifs, qui classifient des valeurs primitives (
binary,date,datetime,datetimezone,duration,list,logical,null,number,record,text,time,type) et incluent un certain nombre de types abstraits (function,table,any, etnone)- Types d’enregistrements, qui classifient les valeurs d’enregistrement en fonction des noms de champs et des types de valeurs
- Types de listes, qui classifient les listes à l’aide d’un type de base d’élément unique
- Types de fonctions, qui classifient les valeurs de fonction en fonction des types de leurs paramètres et valeurs de retour
- Types de tables, qui classifient les valeurs de table en fonction des noms de colonnes, des types de colonnes et des clés
- Types Nullable, qui classifient la valeur Null en plus de toutes les valeurs classifiées par un type de base
- Types de types, qui classifient les valeurs qui sont des types
En utilisant la sortie JSON brute que vous obtenez (et/ou en recherchant les définitions dans les $metadata du service), vous pouvez définir les types d’enregistrements suivants pour représenter des types complexes OData :
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
Notez comment LocationType référence CityType et LocType pour représenter ses colonnes structurées.
Pour les entités de premier niveau (que vous voulez représenter sous forme de tableaux), vous définissez des types de tableaux :
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency = Int64.Type
];
Vous mettez ensuite à jour votre variable SchemaTable (que vous utilisez comme « table de consultation » pour les mappages entité/type) pour utiliser ces nouvelles définitions de type :
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType },
{"Airports", AirportsType },
{"People", PeopleType}
});
Application d’un schéma à l’aide de types
Vous vous appuierez sur une fonction commune (Table.ChangeType) pour appliquer un schéma à vos données, tout comme vous avez utilisé SchemaTransformTable dans la leçon précédente.
Contrairement à SchemaTransformTable, Table.ChangeType prend un type de table M réel comme argument, et applique votre schéma de manière récursive pour tous les types imbriqués. Sa signature ressemble à ceci :
Table.ChangeType = (table, tableType as type) as nullable table => ...
La liste complète du code de la Table.ChangeType fonction se trouve dans le fichier Table.ChangeType.pqm .
Remarque
Pour des raisons de flexibilité, la fonction peut être utilisée sur des tableaux, ainsi que sur des listes d'enregistrements (c'est ainsi que les tableaux seraient représentés dans un document JSON).
Vous devrez ensuite mettre à jour le code du connecteur pour modifier le paramètre schema de table en type, puis ajouter un appel à Table.ChangeType dans GetEntity.
GetEntity = (url as text, entity as text) as table =>
let
fullUrl = Uri.Combine(url, entity),
schema = GetSchemaForEntity(entity),
result = TripPin.Feed(fullUrl, schema),
appliedSchema = Table.ChangeType(result, schema)
in
appliedSchema;
GetPage est mis à jour pour utiliser la liste des champs du schéma (pour connaître les noms des éléments à développer lorsque vous obtenez les résultats), mais laisse l’application réelle du schéma à GetEntity.
GetPage = (url as text, optional schema as type) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
// If we have no schema, use Table.FromRecords() instead
// (and hope that our results all have the same fields).
// If we have a schema, expand the record using its field names
data =
if (schema <> null) then
Table.FromRecords(body[value])
else
let
// convert the list of records into a table (single column of records)
asTable = Table.FromList(body[value], Splitter.SplitByNothing(), {"Column1"}),
fields = Record.FieldNames(Type.RecordFields(Type.TableRow(schema))),
expanded = Table.ExpandRecordColumn(asTable, fields)
in
expanded
in
data meta [NextLink = nextLink];
Confirmation que les types imbriqués sont définis
La définition de votre PeopleType champ définit désormais le Emails champ sur une liste de texte ({text}).
Si vous appliquez correctement les types, l’appel à Type.ListItem dans votre test unitaire doit maintenant retourner type text plutôt que type any.
L’exécution de vos tests unitaires montre à nouveau qu’ils passent tous.
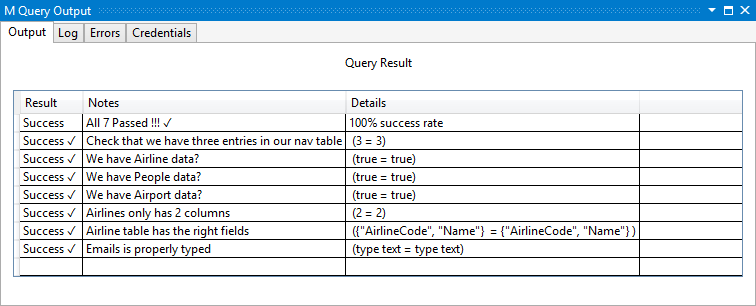
Refactorisation du code commun dans des fichiers distincts
Remarque
Le moteur M aura amélioré la prise en charge du référencement des modules externes/du code commun à l’avenir, mais cette approche devrait vous transporter jusqu’à ce moment-là.
À ce stade, votre extension a presque autant de code « commun » que le code du connecteur TripPin. À l’avenir, ces fonctions courantes feront partie de la bibliothèque de fonctions standard intégrée, ou vous pourrez les référencer à partir d’une autre extension. Pour l’instant, vous refactorisez votre code de la manière suivante :
- Déplacez les fonctions réutilisables vers des fichiers distincts (.pqm).
- Définissez la propriété Action de génération du fichier sur Compiler pour vous assurer qu'il sera inclus dans votre fichier d'extension lors de la génération.
- Définissez une fonction pour charger le code à l’aide d’Expression.Evaluate.
- Chargez chacune des fonctions courantes que vous souhaitez utiliser.
Le code à effectuer est inclus dans l’extrait de code ci-dessous :
Extension.LoadFunction = (fileName as text) =>
let
binary = Extension.Contents(fileName),
asText = Text.FromBinary(binary)
in
try
Expression.Evaluate(asText, #shared)
catch (e) =>
error [
Reason = "Extension.LoadFunction Failure",
Message.Format = "Loading '#{0}' failed - '#{1}': '#{2}'",
Message.Parameters = {fileName, e[Reason], e[Message]},
Detail = [File = fileName, Error = e]
];
Table.ChangeType = Extension.LoadFunction("Table.ChangeType.pqm");
Table.GenerateByPage = Extension.LoadFunction("Table.GenerateByPage.pqm");
Table.ToNavigationTable = Extension.LoadFunction("Table.ToNavigationTable.pqm");
Conclusion
Ce tutoriel a apporté plusieurs améliorations à la façon dont vous appliquez un schéma sur les données que vous obtenez à partir d’une API REST. Le connecteur code actuellement en dur ses informations de schéma, qui présente un avantage en matière de performances lors de l’exécution, mais ne peut pas s’adapter aux modifications apportées aux heures supplémentaires des métadonnées du service. Les didacticiels futurs passeront à une approche purement dynamique qui déduira le schéma du document $metadata du service.
Outre les modifications de schéma, ce didacticiel a ajouté des tests unitaires pour votre code et refactorisé les fonctions d’assistance courantes dans des fichiers distincts afin d’améliorer la lisibilité globale.
Étapes suivantes
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour