Bonnes pratiques de classification dans le portail de gouvernance Microsoft Purview
La classification des données dans le portail de gouvernance Microsoft Purview est un moyen de catégoriser les ressources de données en affectant des étiquettes logiques ou des classes uniques aux ressources de données. La classification est basée sur le contexte métier des données. Par exemple, vous pouvez classifier les ressources par numéro de passeport, numéro de permis de conduire, numéro de carte de crédit, code SWIFT, nom de la personne, etc. Pour en savoir plus sur la classification elle-même, consultez notre article sur la classification.
Cet article décrit les meilleures pratiques à adopter lors de la classification des ressources de données, afin que vos analyses soient plus efficaces et que vous disposiez des informations les plus complètes possibles sur l’ensemble de votre patrimoine de données.
Ensemble de règles d’analyse
À l’aide d’un ensemble de règles d’analyse, vous pouvez configurer les classifications pertinentes qui doivent être appliquées à l’analyse particulière de la source de données. Sélectionnez les classifications système appropriées, ou sélectionnez des classifications personnalisées si vous en avez créé une pour les données que vous analysez.
Par exemple, dans l’image suivante, seules les classifications système et personnalisées spécifiques sélectionnées sont appliquées à la source de données que vous analysez (par exemple, les données financières).

Gestion des annotations
Pendant que vous décidez des classifications à appliquer, nous vous recommandons de :
Accédez au volet Classificationsde gestion des>annotations data map>.
Passez en revue les classifications système disponibles à appliquer aux ressources de données que vous analysez. Les noms formels des classifications système ont un préfixe MICROSOFT .
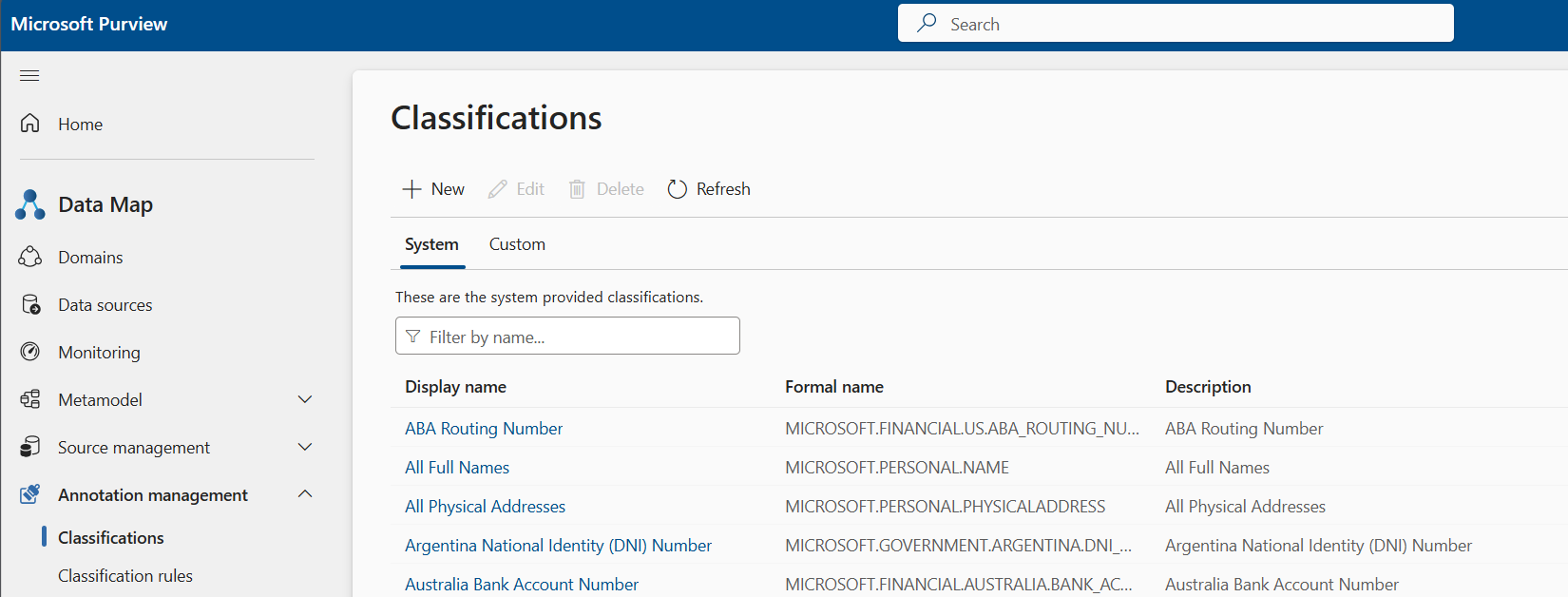
Si nécessaire, créez un nom de classification personnalisé. Démarrez dans ce volet, puis accédez à Gestiondes annotations data>map>. Règles de classification. Ici, vous pouvez créer la règle de classification pour le nom de classification personnalisé que vous avez créé à l’étape précédente.
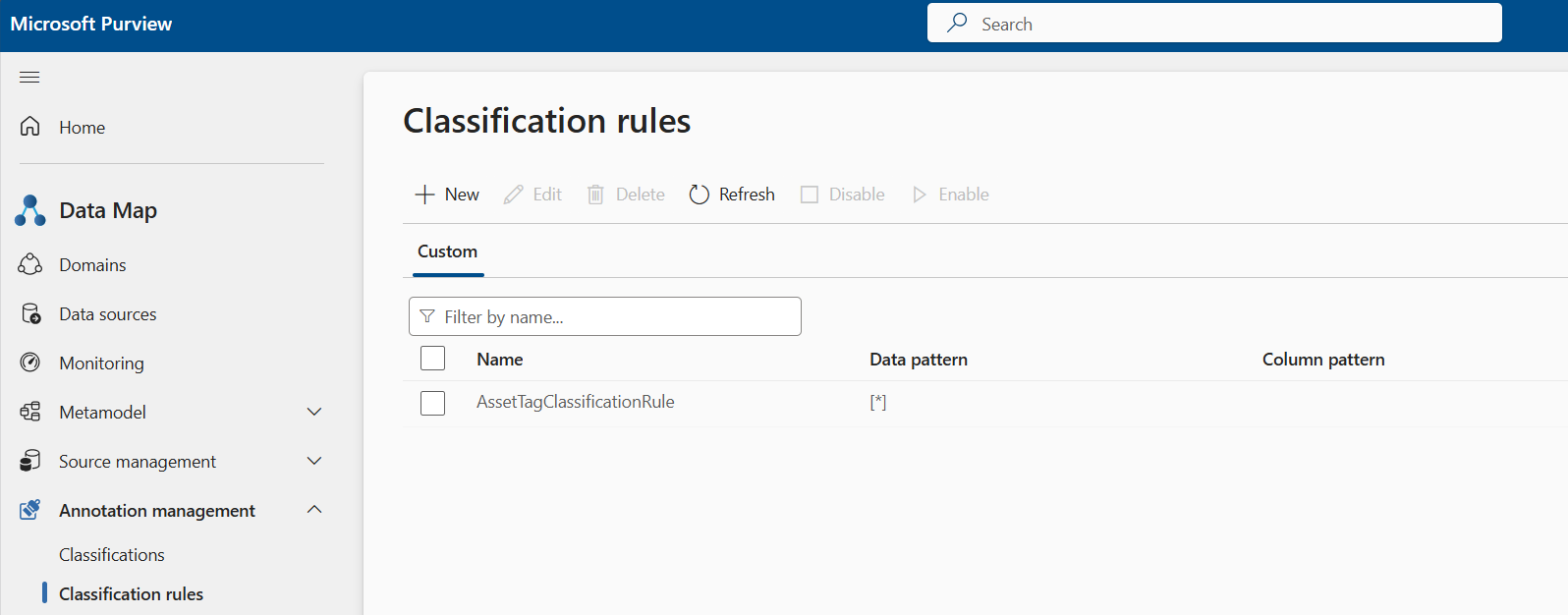


Classifications personnalisées
Créez des classifications personnalisées uniquement si les classifications système disponibles ne répondent pas à vos besoins.
Pour le nom de la classification personnalisée, il est recommandé d’utiliser une convention d’espace de noms (par exemple, <le nom> de la société).<unité commerciale>.<nom> de la classification personnalisée).
Par exemple, pour la classification de EMPLOYEE_ID personnalisée pour la société fictive Contoso, le nom de votre classification personnalisée est CONTOSO.HR. EMPLOYEE_ID, et le nom convivial est stocké dans le système en tant que HR. ID D’EMPLOYÉ.

Lorsque vous créez et configurez les règles de classification pour une classification personnalisée, procédez comme suit :
Sélectionnez le nom de classification approprié pour lequel la règle de classification doit être créée.
Le portail de gouvernance Microsoft Purview prend en charge les deux méthodes suivantes pour créer des règles de classification personnalisées :
Utilisez la méthode Expression régulière (regex) si vous pouvez exprimer de manière cohérente l’élément de données à l’aide d’un modèle d’expression régulière ou si vous pouvez générer le modèle à l’aide d’un fichier de données. Vérifiez que les exemples de données reflètent la population.
Utilisez la méthode Dictionary uniquement si la liste de valeurs dans le fichier de dictionnaire représente toutes les valeurs possibles des données à classer et qu’elle est censée être conforme à un ensemble de données donné (compte tenu également des valeurs futures).
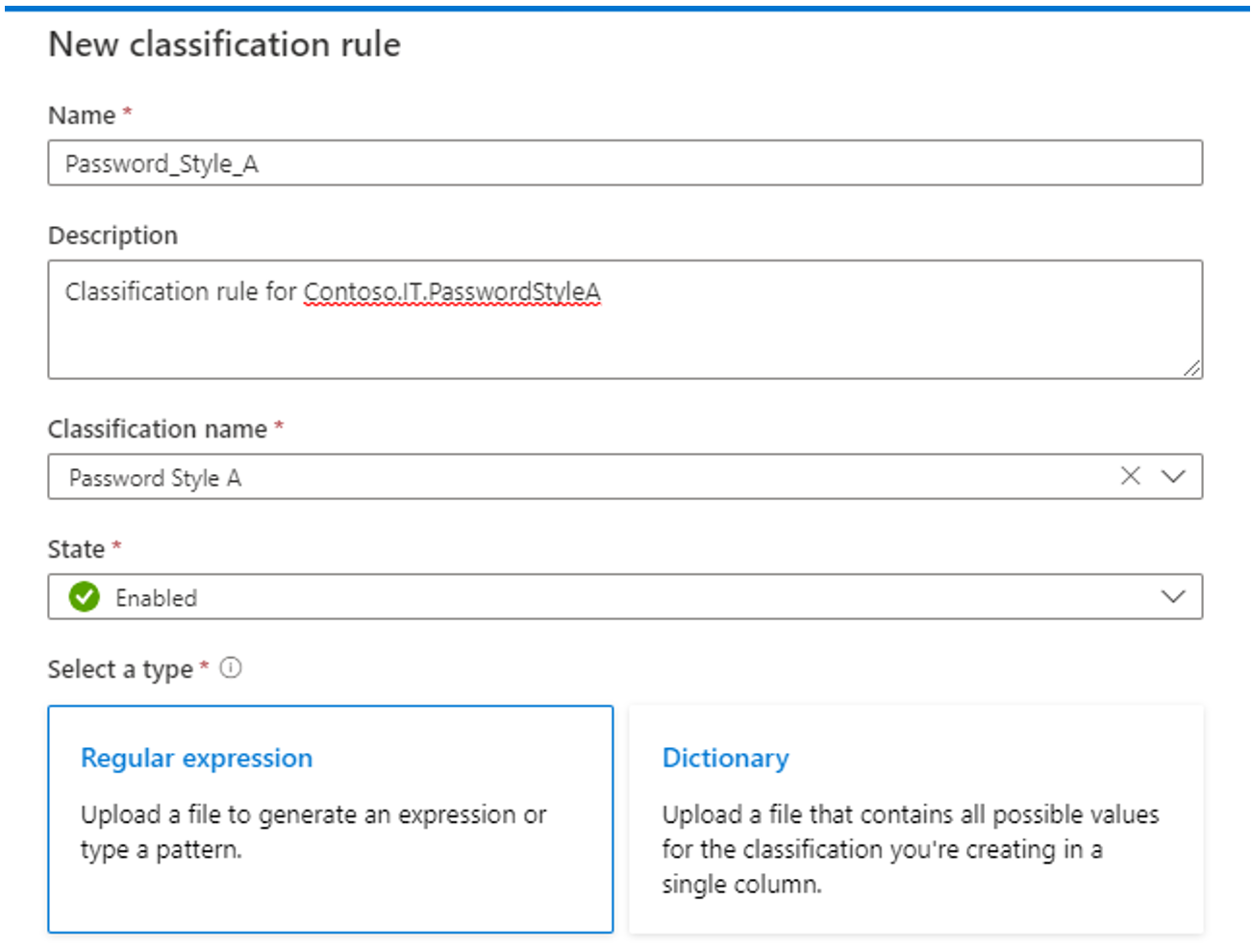
Utilisation de la méthode d’expression régulière :
Configurez le modèle d’expression régulière pour les données à classer. Assurez-vous que le modèle d’expression régulière est suffisamment générique pour répondre aux données classifiées.
Microsoft Purview fournit également une fonctionnalité permettant de générer un modèle d’expression régulière suggérée. Après avoir chargé un exemple de fichier de données, sélectionnez l’un des modèles suggérés, puis sélectionnez Ajouter aux modèles pour utiliser les modèles de données et de colonnes suggérés. Vous pouvez modifier les modèles suggérés ou taper vos propres modèles sans avoir à charger un fichier.
Vous pouvez également configurer le modèle de nom de colonne pour que la colonne soit classifiée afin de réduire les faux positifs.
Configurez le paramètre Seuil de correspondance minimale acceptable pour vos données qui correspondent au modèle de données pour appliquer la classification. Les valeurs de seuil peuvent être comprises entre 1 % et 100 %. Nous suggérons une valeur d’au moins 60 % comme seuil pour éviter les faux positifs. Toutefois, vous pouvez configurer si nécessaire pour vos scénarios de classification spécifiques. Par exemple, votre seuil peut être aussi bas que 1 % si vous souhaitez détecter et appliquer une classification pour n’importe quelle valeur dans les données si elle correspond au modèle.
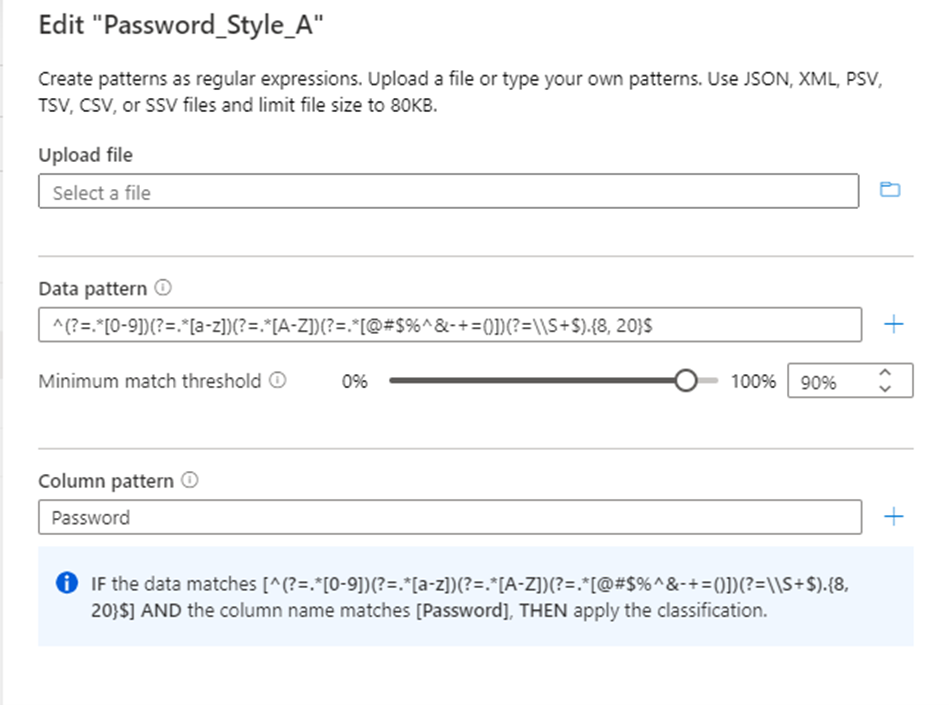
L’option permettant de définir une règle de correspondance minimale est automatiquement désactivée si plusieurs modèles de données sont ajoutés à la règle de classification.
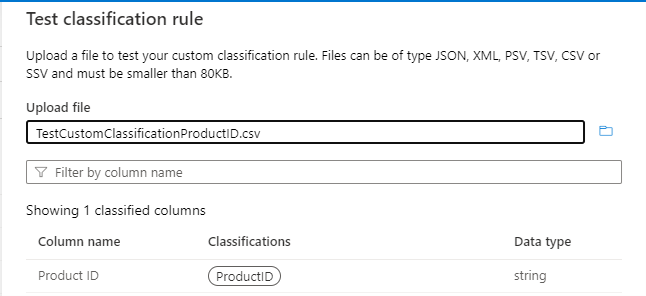
Utilisez la règle de classification de test et testez avec des exemples de données pour vérifier que la règle de classification fonctionne comme prévu. Vérifiez que dans les exemples de données (par exemple, dans un fichier .csv) au moins trois colonnes sont présentes, y compris la colonne sur laquelle la classification doit être appliquée. Si le test réussit, vous devez voir l’étiquette de classification sur la colonne, comme illustré dans l’image suivante :
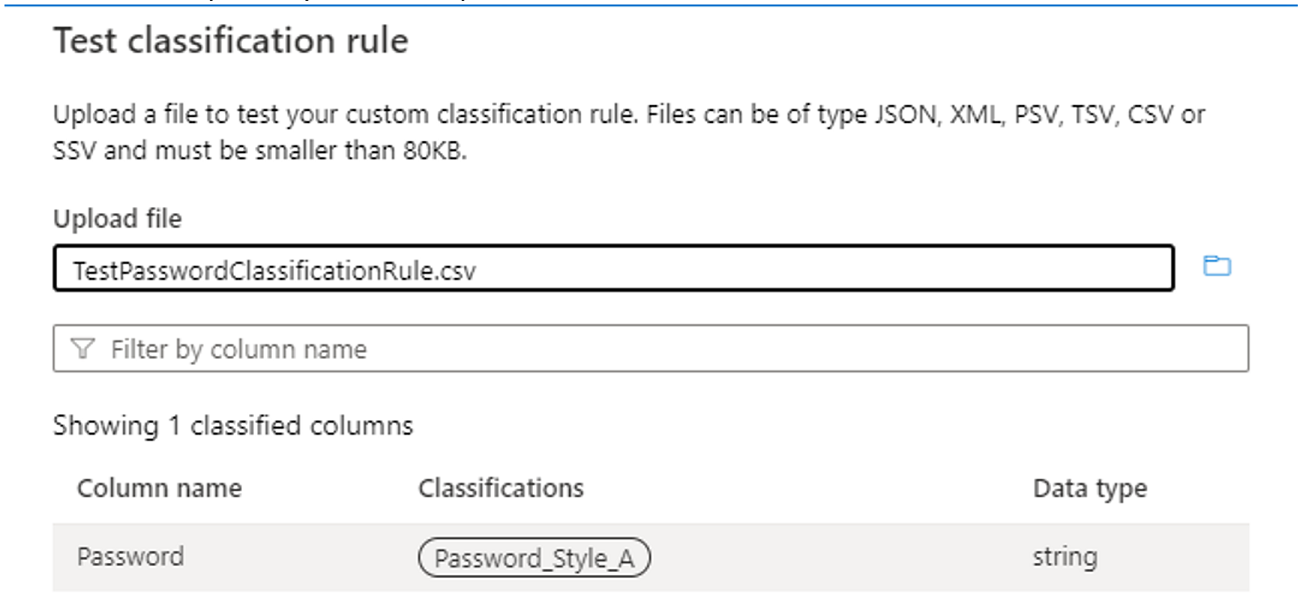
Utilisation de la méthode Dictionary :
Vous pouvez utiliser la méthode Dictionary pour ajuster les données d’énumération ou si la liste de valeurs possibles du dictionnaire est disponible.
Cette méthode prend en charge les fichiers .csv et .tsv, avec une limite de taille de fichier de 30 mégaoctets (Mo).



Archétypes de classification personnalisée
Fonctionnement du paramètre « threshold » dans l’expression régulière
Considérez les exemples de données sources dans l’image suivante. Il existe cinq colonnes, et la règle de classification personnalisée doit être appliquée aux colonnes Sample_col1, Sample_col2 et Sample_col3 pour le modèle de données N{Chiffre}{Chiffre}{Chiffre}{Chiffre}AN.
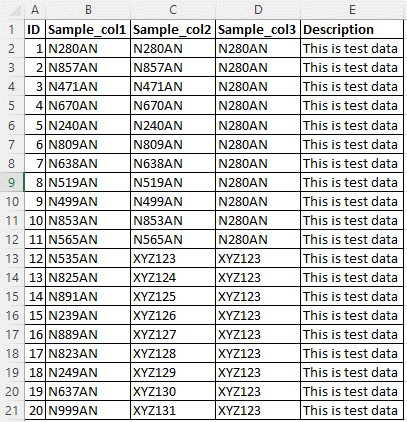
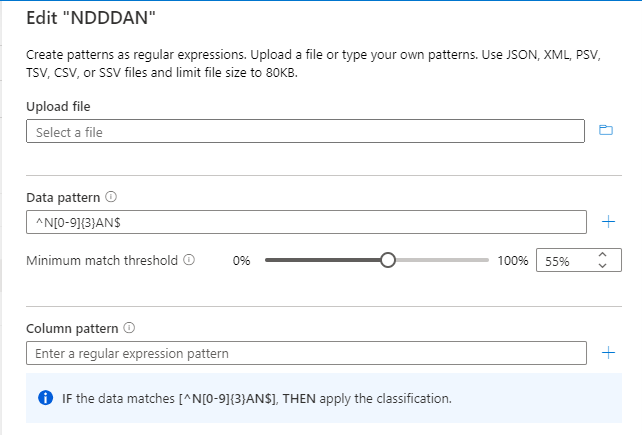
La classification personnalisée est nommée NDDDAN.
La règle de classification (expression régulière pour le modèle de données) est ^N[0-9]{3}AN$.
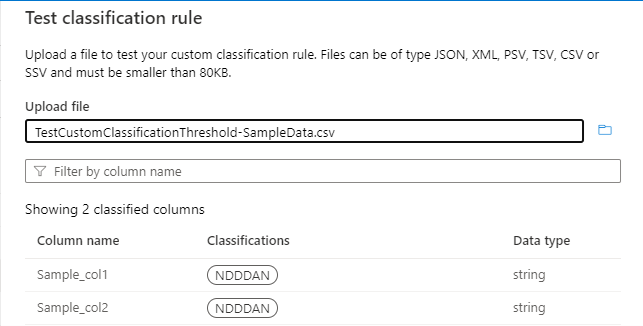
Le seuil est calculé pour le modèle « ^N[0-9]{3}AN$ », comme illustré dans l’image suivante :

Si vous avez un seuil de 55 %, seules les colonnes Sample_col1 et Sample_col2 sont classées. Sample_col3 ne seront pas classifiés, car ils ne répondent pas au critère de seuil de 55 %.




Utilisation des modèles de données et de colonnes
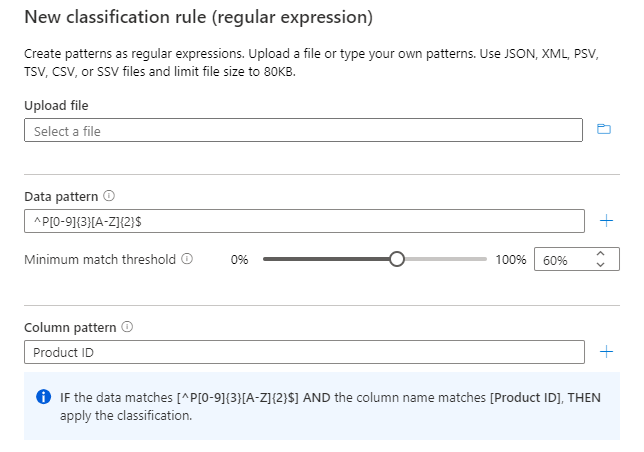
Pour les exemples de données donnés, où les colonnes B et C ont des modèles de données similaires, vous pouvez classifier sur la colonne B en fonction du modèle de données « ^P[0-9]{3}[A-Z]{2}$ ».

Utilisez le modèle de colonne avec le modèle de données pour vous assurer que seule la colonne ID de produit est classifiée.
Remarque
Le modèle de colonne est vérifié en tant que condition AND avec le modèle de données.
Utilisez la règle de classification de test et testez avec des exemples de données pour vérifier que la règle de classification fonctionne comme prévu.



Comment utiliser plusieurs modèles de colonne
S’il existe plusieurs modèles de colonnes à classer pour la même règle de classification, utilisez des noms de colonnes séparées par des caractères (|). Par exemple, pour les colonnes ID de produit, Product_ID, ProductID, et ainsi de suite, écrivez le modèle de colonne comme illustré dans l’image suivante :

Pour plus d’informations, consultez Construction d’alternance regex.
Considérations relatives à la classification
Voici quelques considérations à prendre en compte lorsque vous définissez des classifications :
Pour déterminer quelles classifications doivent être appliquées aux ressources avant l’analyse, réfléchissez à la façon dont vos classifications doivent être utilisées. Les étiquettes de classification inutiles peuvent sembler bruyantes et même trompeuses pour les consommateurs de données. Vous pouvez utiliser des classifications pour :
- Décrire la nature des données qui existent dans la ressource de données ou le schéma analysé. En d’autres termes, les classifications doivent permettre aux clients d’identifier le contenu de la ressource de données ou du schéma à partir des étiquettes de classification lors de la recherche dans le catalogue.
- Définissez les priorités et développez un plan pour répondre aux besoins de sécurité et de conformité d’un organization.
- Décrivez les phases des processus de préparation des données (zone brute, zone d’atterrissage, etc.) et attribuez les classifications à des ressources spécifiques pour marquer la phase du processus.
Vous pouvez attribuer automatiquement des classifications au niveau de la ressource ou de la colonne en incluant des classifications pertinentes dans la règle d’analyse, ou vous pouvez les affecter manuellement après avoir ingéré les métadonnées dans le Mappage de données Microsoft Purview.
Pour l’attribution automatique, consultez magasins de données pris en charge dans le portail de gouvernance Microsoft Purview.
Avant d’analyser vos sources de données dans le Mappage de données Microsoft Purview, il est important de comprendre vos données et de configurer l’ensemble de règles d’analyse approprié pour celles-ci (par exemple, en sélectionnant la classification système appropriée, les classifications personnalisées ou une combinaison des deux), car cela peut affecter vos performances d’analyse. Pour plus d’informations, consultez classifications prises en charge dans le portail de gouvernance Microsoft Purview.
Le scanneur Microsoft Purview applique des règles d’échantillonnage des données pour les analyses approfondies (sous réserve de classification) pour les classifications système et personnalisées. La règle d’échantillonnage est basée sur le type de sources de données. Pour plus d’informations, consultez la section « Échantillonnage dans un fichier » dans Sources de données et types de fichiers pris en charge dans Microsoft Purview.
Remarque
Seuil de données distinctes : il s’agit du nombre total de valeurs de données distinctes qui doivent être trouvées dans une colonne avant que le scanneur exécute le modèle de données sur celle-ci. Le seuil de données distincts n’a rien à voir avec la correspondance de modèle, mais il s’agit d’une condition préalable à la correspondance de modèle. Les règles de classification système exigent qu’il y ait au moins 8 valeurs distinctes dans chaque colonne pour les soumettre à la classification. Le système requiert cette valeur pour s’assurer que la colonne contient suffisamment de données pour que le scanneur la classifie avec précision. Par exemple, une colonne qui contient plusieurs lignes contenant toutes la valeur 1 ne sera pas classifiée. Les colonnes qui contiennent une ligne avec une valeur et le reste des lignes ont des valeurs Null ne seront pas non plus classifiées. Si vous spécifiez plusieurs modèles, cette valeur s’applique à chacun d’eux.
Les règles d’échantillonnage s’appliquent également aux jeux de ressources. Pour plus d’informations, consultez la section « Échantillonnage de fichiers de jeu de ressources » dans sources de données et types de fichiers pris en charge dans le portail de gouvernance Microsoft Purview.
Les classifications personnalisées ne peuvent pas être appliquées sur des ressources de type de document à l’aide de règles de classification personnalisées. Les classifications pour ces types peuvent être appliquées manuellement uniquement.
Les classifications personnalisées ne sont pas incluses dans les règles d’analyse par défaut. Par conséquent, si l’attribution automatique de classifications personnalisées est attendue, vous devez déployer et utiliser une règle d’analyse personnalisée qui inclut la classification personnalisée pour exécuter l’analyse.
Si vous appliquez des classifications manuellement à partir du portail de gouvernance Microsoft Purview, ces classifications sont conservées dans les analyses suivantes.
Les analyses suivantes ne suppriment aucune classification des ressources, si elles ont été détectées précédemment, même si les règles de classification ne sont pas applicables.
Pour les ressources de données sources chiffrées , Microsoft Purview sélectionne uniquement les noms de fichiers, les noms complets, les détails de schéma pour les types de fichiers structurés et les tables de base de données. Pour que la classification fonctionne, déchiffrez les données chiffrées avant d’exécuter des analyses.
Prochaines étapes
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour