Connecter Clusters Big Data SQL Server : Mode Active Directory
Cet article explique comment se connecter à des points de terminaison de cluster Big Data SQL Server déployés en mode Active Directory. Les tâches décrites dans cet article nécessitent que vous disposiez d’un cluster Big Data SQL Server déployé en mode Active Directory. Si vous n’avez pas de cluster, consultez Déployer Clusters Big Data SQL Server en mode Active Directory.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Vue d’ensemble
Connectez-vous à l’instance principale SQL Server avec l’authentification AD.
Pour vérifier les connexions AD à l’instance SQL Server, connectez-vous à l’instance principale SQL avec sqlcmd. Les connexions sont automatiquement créées pour les groupes fournis lors du déploiement (clusterUsers et clusterAdmins).
Si vous utilisez Linux, commencez par exécuter kinit en tant qu’utilisateur Active Directory, puis exécutez sqlcmd. Si vous utilisez Windows, connectez-vous simplement en tant qu’utilisateur souhaité à partir d’un ordinateur client joint au domaine.
Se connecter à l’instance principale à partir de Linux/Mac
kinit <username>@<domain name>
sqlcmd -S <DNS name for master instance>,31433 -E
Se connecter à l’instance principale à partir de Windows
sqlcmd -S <DNS name for master instance>,31433 -E
Se connecter à l’instance principale SQL Server à l’aide d’Azure Data Studio ou SSMS
À partir d’un client joint au domaine, vous pouvez ouvrir SSMS ou Azure Data Studio et vous connecter à l’instance principale. Il s’agit de la même expérience que la connexion à n’importe quelle instance SQL Server à l’aide de l’authentification Active Directory.
À partir de SSMS :

À partir d’Azure Data Studio :
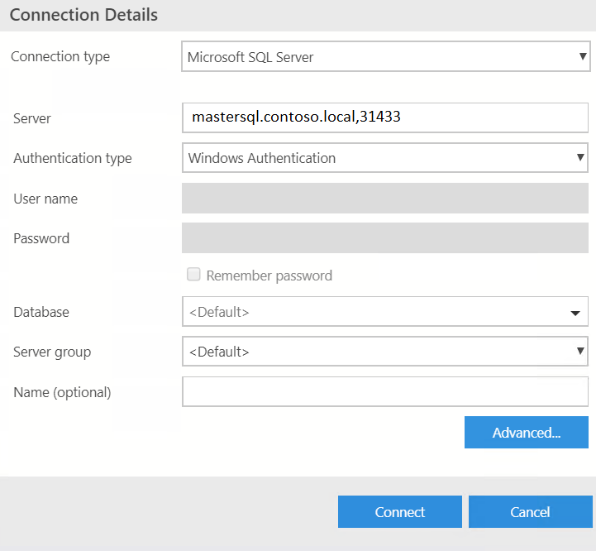 }
}
Se connecter au contrôleur avec l’authentification Active Directory
Se connecter au contrôleur avec l’authentification Active Directory à partir de Linux/Mac
Il existe deux solutions pour se connecter au point de terminaison du contrôleur à l’aide de Azure Data CLI (azdata) et de l’authentification AD. Vous pouvez utiliser le paramètre --endpoint/-e :
kinit <username>@<domain name>
azdata login -e https://<controller DNS name>:30080 --auth ad
Vous pouvez également vous connecter à l’aide du paramètre --namespace/-n, à savoir le nom du cluster Big Data :
kinit <username>@<domain name>
azdata login -n <clusterName> --auth ad
Se connecter au contrôleur avec l’authentification Active Directory à partir de Windows
azdata login -e https://<controller DNS name>:30080 --auth ad
Utiliser l’authentification AD pour la passerelle Knox (webHDFS)
Vous pouvez également émettre des commandes HDFS à l’aide de curl via le point de terminaison de la passerelle Knox. Cela nécessite l’authentification Active Directory pour Knox. La commande curl ci-dessous émet un appel REST webHDFS via la passerelle Knox pour créer un répertoire appelé products
curl -k -v --negotiate -u : https://<Gateway DNS name>:30443/gateway/default/webhdfs/v1/products?op=MKDIRS -X PUT
Étapes suivantes
Résolution des problèmes d’intégration Active Directory Clusters Big Data SQL Server
Concept : Déploiement de Clusters Big Data SQL Server en mode Active Directory