Rapprochement entre les noms DNS Active Directory et Kubernetes dans les déploiements Clusters Big Data
Cet article décrit quelques problématiques et solutions relatives à la gestion de l’intégration Active Directory lors du déploiement de clusters Big Data.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Vue d’ensemble
Lorsque le cluster Big Data n’est pas déployé avec l’intégration Active Directory, les résolutions DNS internes s’appuient sur le service Kubernetes CoreDNS. Kubernetes utilise un domaine interne du type <namespace>.svc.cluster.local. Il crée des enregistrements A (recherche directe) et PTR (recherche inversée) dans le serveur DNS avec les noms de ce domaine.
Lorsque le mode de Active Directory est activé, en revanche, un nouveau domaine entre en jeu avec son propre ensemble de serveurs DNS. Lors de la résolution de noms interne, cela peut entraîner une confusion concernant l’ensemble de serveurs DNS à atteindre pour les recherches directes et inversées.
Défis
- Lors du déploiement de nouveaux pods Kubernetes, les entrées DNS doivent être ajoutées dans les deux ensembles de serveurs DNS. Kubernetes prend en charge l’enregistrement des entrées dans son service CoreDNS. Toutefois, le workflow de déploiement de cluster Big Data est chargé d’ajouter les entrées nécessaires dans les serveurs DNS du contrôleur de domaine Active Directory. De même, en cas de suppression d’un cluster Big Data, le flux de travail doit veiller à ce que ces entrées soient supprimées.
- Les serveurs DNS Active Directory sont extérieurs au cluster Kubernetes. Cependant, le cluster Big Data possède son propre espace IP dans Kubernetes et ne peut pas créer d’enregistrements pour cet espace IP sur un serveur DNS externe, car cet espace IP n’est pas visible en dehors des limites du cluster.
- Lorsque des événements de basculement se produisent au sein du cluster Kubernetes, les enregistrements des serveurs DNS AD doivent également être mis à jour.
- Les noms du service Kubernetes comme ceux des pods doivent être adressables au moyen de recherches de nom de domaine AD, ce qui crée une difficulté supplémentaire dans les noms DNS Active Directory. En effet, un nom de service peut correspondre à plusieurs adresses IP de pods.
- L’enregistrement des retards de propagation et de réplication des mises à jour dans les serveurs DNS Active Directory de l’organisation peut être volumineux et échapper au contrôle des flux de travail de gestion Clusters Big Data, ce qui risque d’avoir un impact sur la fonctionnalité Clusters Big Data juste après le déploiement et le basculement. Kubernetes CoreDNS est plus rapide et plus efficace en raison de sa localité.
Solution
Pour contourner les problématiques mentionnées plus haut, la solution implémentée dans Clusters Big Data implique un nouveau service CoreDNS interne, géré dans l’espace de noms Clusters Big Data. Il s’agit du seul service DNS auquel s’adressent les pods de l’espace de noms de cluster Big Data pour les résolutions de noms. La complexité liée aux domaines multiples est cachée derrière le nouveau service CoreDNS.
Par exemple, dans le diagramme suivant, les pods utilisent le serveur CoreDNS Clusters Big Data pour résoudre les noms. Ils n’interagissent directement ni avec le serveur Kubernetes CoreDNS, ni avec le serveur DNS AD.
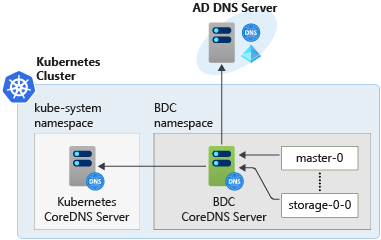
Voici quelques aspects de l’implémentation qui clarifient le fonctionnement de cette conception dans Clusters Big Data :
Gestion centralisée de plusieurs domaines
La complexité des processus de recherches de noms reste cachée derrière le service DNS interne de manière centralisée, ce qui évite aux différents pods d’avoir à gérer plusieurs domaines et simplifie la conception.
Aucun enregistrement pour les pods internes des serveurs DNS externes
En conséquence de ce principe de conception, Clusters Big Data n’a pas à créer ni à gérer les enregistrements A et PTR des pods qui se trouvent dans l’espace IP Kubernetes des serveurs DNS externes.
Aucune duplication des enregistrements
Les enregistrements DNS internes ne sont stockés que dans Kubernetes CoreDNS. Le service CoreDNS interne Clusters Big Data effectue une réécriture et un transfert computationnels des requêtes DNS vers Kubernetes CoreDNS.
Réécriture computationnelle
Comme le cluster Big Data ne stocke pas d’enregistrements, il est chargé de traduire, dans une requête de recherche directe entrante, les noms avec un domaine AD en noms avec un domaine Kubernetes. Ensuite, il transfère cette requête à Kubernetes CoreDNS.
Par exemple, une requête entrante pour compute-0-0.contoso.local est réécrite en compute-0-0.compute-0-svc.contoso.svc.cluster.local. Cette demande est transférée à Kubernetes CoreDNS.
Dans le cas de recherches inversées, la demande est transmise avec des adresses IP internes, car elles sont destinées à Kubernetes CoreDNS. Ensuite, elle réécrit la réponse avec le nom de domaine AD avant de répondre au client.
Simplicité dans les configurations de pods
Le fait que seul le nom CoreDNS Clusters Big Data interne soit référencé dans /etc/resolv.conf pour tous les pods simplifie la vue réseau à partir des pods. La complexité est cachée dans le service CoreDNS interne.
Adresse IP statique et fiable pour le service DNS
Le service CoreDNS déployé par Clusters Big Data comporte une adresse IP interne statique inscrite, accessible à partir de tous les pods, ce qui évite d’avoir à mettre à jour les valeurs de /etc/resolv.conf.
Gestion de l’équilibrage de charge de service conservée par Kubernetes
Les recherches effectuées pour des services plutôt que des pods individuels restent adressées à Kubernetes CoreDNS. Ainsi, Clusters Big Data n’est pas responsable de l’implémentation de l’équilibrage de charge spécialement pour le domaine AD.
Par exemple, si une demande de recherche directe est fournie pour compute-0-svc.contoso.local, elle est réécrite en compute-0-svc.contoso.svc.cluster.local. Elle sera transférée à Kubernetes CoreDNS, où se produira l’équilibrage de charge. La réponse sera l’adresse IP de l’une des instances de pools de calcul multiples (réplicas de pods).
Extensibilité
Dans la mesure où Clusters Big Data ne stocke pas d’enregistrements, le service CoreDNS Clusters Big Data interne peut être mis à l’échelle sans rétention d’état ni réplication d’enregistrements sur plusieurs réplicas. Si les enregistrements DNS sont stockés dans Clusters Big Data, la réplication de l’état sur tous les pods doit également être prise en charge par Clusters Big Data.
Maintien des entrées de service visibles de l’extérieur dans le nom DNS AD
En ce qui concerne les points de terminaison de service qui doivent être accessibles aux clients en dehors du cluster Kubernetes, les entrées DNS sont créées dans le serveur DNS AD lors du déploiement Clusters Big Data. L’utilisateur entre les noms DNS servant de base à l’inscription à travers les profils de configuration du déploiement.
Déprovisionnement automatique
Une fois le cluster Big Data supprimé et lors de son déprovisionnement, il n’existe aucun travail dynamique supplémentaire à effectuer pour supprimer les entrées DNS. Les seules entrées des noms DNS Active Directory distants qui doivent être nettoyées concernent les services externes ; leur nombre est statique. Les entrées DNS internes seront automatiquement supprimées avec le cluster.
Étapes suivantes
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour