Virtualiser des données CSV à partir d’un pool de stockage (clusters Big Data)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Les clusters Big Data SQL Server peuvent virtualiser des données à partir de fichiers CSV dans HDFS. Ce processus permet aux données de rester à leur emplacement d’origine, mais il est possible de les interroger à partir d’une instance de SQL Server au même titre qu’une table. Cette fonctionnalité utilise des connecteurs Polybase et minimise le recours aux processus ETL. Pour plus d’informations sur la virtualisation de données, consultez Présentation de la virtualisation des données avec PolyBase
Prérequis
Sélectionner ou charger un fichier CSV pour la virtualisation des données
Dans Azure Data Studio (ADS), connectez-vous à l’instance maître de SQL Server de votre cluster Big Data. Une fois connecté, développez les éléments HDFS dans l’Explorateur d’objets pour localiser le ou les fichiers CSV dont vous souhaitez virtualiser les données.
Pour les besoins de ce tutoriel, nous allons créer un répertoire nommé Data.
- Cliquez avec le bouton droit sur le menu contextuel du répertoire racine HDFS.
- Sélectionnez Nouveau répertoire.
- Nommez le nouveau répertoire Data.
Chargez l’exemple de données. Pour une procédure pas à pas simple, vous pouvez utiliser un exemple de fichier de données CSV. Cet article utilise les données sur les causes des retards aériens du ministère américain des Transports (USDOT). Téléchargez les données brutes et extrayez-les sur votre ordinateur. Nommez le fichier airline_delay_causes.csv.
Pour charger l’exemple de fichier une fois celui-ci extrait :
- Dans Azure Data Studio, cliquez avec le bouton droit sur le nouveau répertoire que vous avez créé.
- Sélectionnez Charger des fichiers.
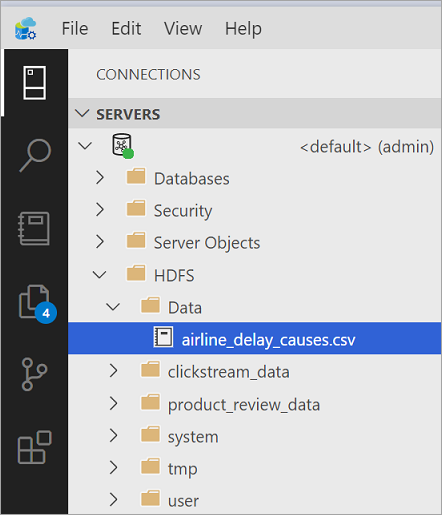
Azure Data Studio charge les fichiers dans HDFS sur le cluster Big Data.
Créer la source de données externe du pool de stockage dans votre base de données cible
La source de données externe du pool de stockage n’est pas créée par défaut dans une base de données au sein de votre cluster Big Data. Avant de pouvoir créer la table externe, créez la source de données externe SqlStoragePool par défaut dans votre base de données cible à l’aide de la requête Transact-SQL suivante. N’oubliez pas de remplacer d’abord le contexte de la requête par votre base de données cible.
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
Créer la table externe
Dans ADS, cliquez avec le bouton droit sur le fichier CSV, puis sélectionnez Créer une table externe à partir d’un fichier CSV dans le menu contextuel. Vous pouvez également créer des tables externes à partir de fichiers CSV d’un répertoire dans HDFS si les fichiers en question respectent le même schéma. Ceci permet la virtualisation des données au niveau des dossiers, sans nécessiter le traitement de chaque fichier ou l’obtention d’un jeu de résultats joints sur les données combinées. Azure Data Studio vous guide tout au long des étapes de création de la table externe.
Spécifiez la base de données, la source de données, un nom de table, le schéma et le nom du format de fichier externe de la table.
Sélectionnez Suivant.
Aperçu des données
Azure Data Studio fournit un aperçu des données importées.
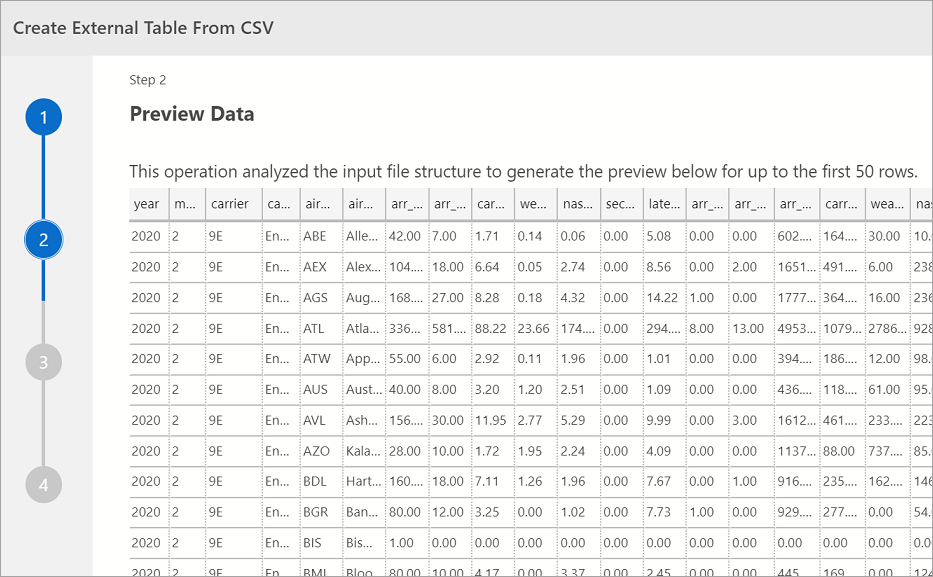
Une fois que vous avez visualisé l’aperçu, sélectionnez Suivant pour continuer.
Modifier les colonnes
Dans la fenêtre suivante, vous pouvez modifier les colonnes de la table externe que vous avez l’intention de créer. Vous pouvez modifier le nom de la colonne, modifier le type des données et autoriser les lignes pouvant accepter la valeur Null.
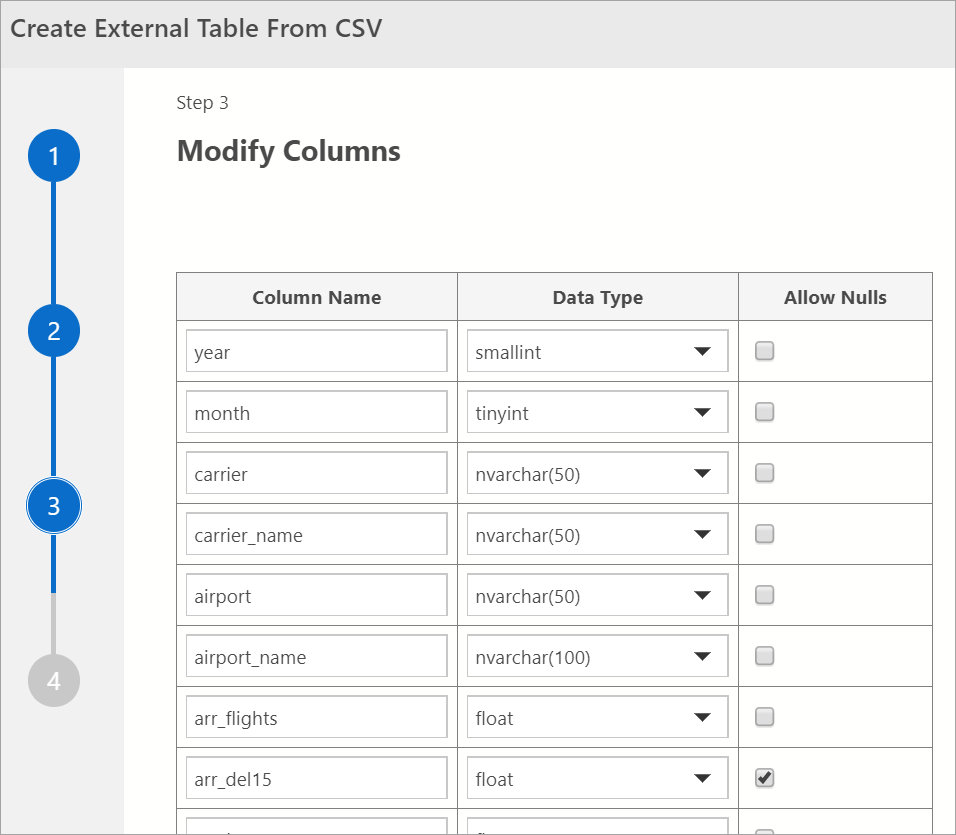
Après avoir vérifié les colonnes de destination, sélectionnez Suivant.
Résumé
Cette étape fournit un récapitulatif de vos sélections. Elle fournit le nom du serveur SQL Server, le nom de la base de données, le nom de la table, le schéma de la table et les informations de la table externe. Dans cette étape, vous pouvez générer un script ou créer une table. Générer un script crée un script en T-SQL pour créer la source de données externe. Créer la table crée la source de données externe.
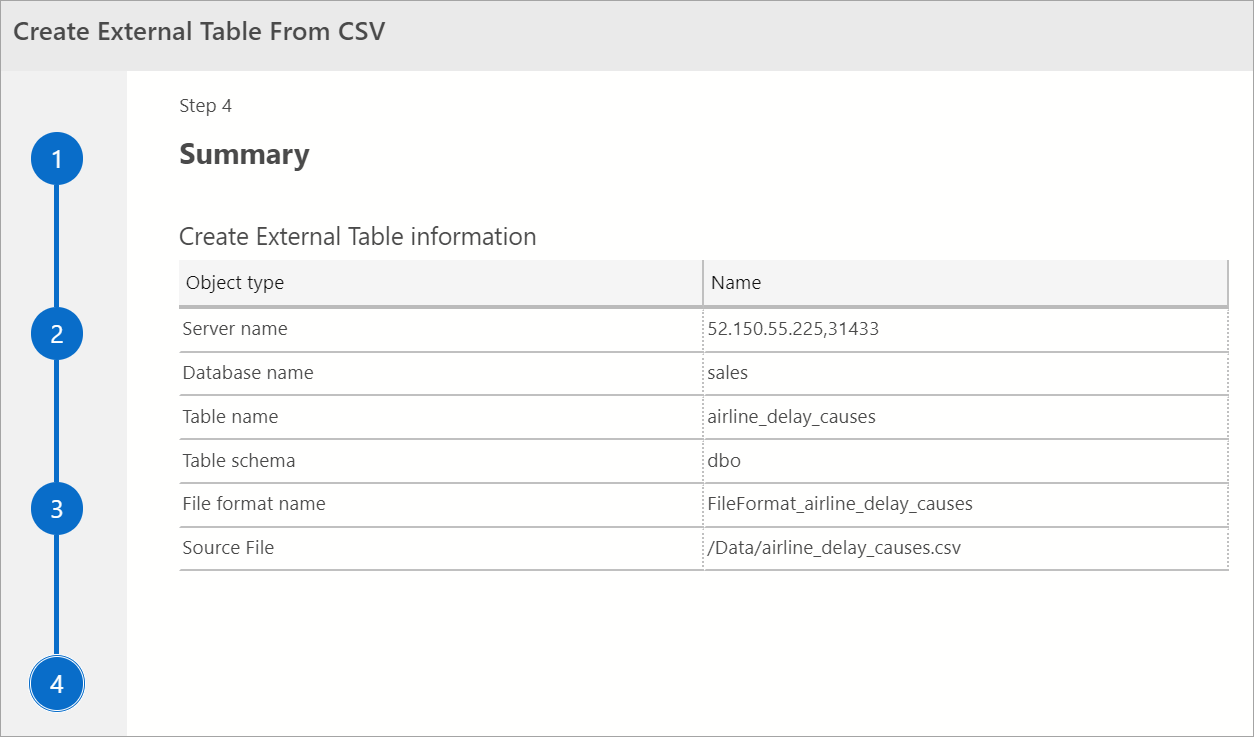
Si vous sélectionnez Créer la table, SQL Server crée la table externe dans la base de données de destination.
Si vous sélectionnez Générer un script, Azure Data Studio crée la requête T-SQL pour créer la table externe.
Une fois la table créée, vous pouvez l’interroger directement en utilisant T-SQL à partir de l’instance de SQL Server.
Étapes suivantes
Pour plus d’informations sur le cluster Big Data SQL Server et les scénarios associés, consultez Présentation des Clusters Big Data SQL Server.
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour