Déployer le nœud de nom HDFS et les services Spark partagés dans une configuration à haut niveau de disponibilité
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Outre le déploiement de l’instance maître SQL Server dans une configuration à haut niveau de disponibilité à l’aide de groupes de disponibilité, vous pouvez déployer d’autres services stratégiques dans le cluster Big Data pour garantir un niveau de fiabilité accru. Vous pouvez configurer le HDFS name node et les services Spark partagés regroupés sous sparkhead avec un réplica supplémentaire. Dans ce cas, Zookeeper est également déployé dans le cluster Big Data sur le serveur en tant que coordinateur de cluster et magasin de métadonnées pour les services suivants :
- Nœud de nom HDFS
- Gestionnaire de ressources Yarn et Livy.
L’historique Spark, l’historique des travaux et le service de métadonnées Hive sont des services sans état. Zookeeper n’est pas impliqué dans la vérification de l’intégrité du service pour ces composants.
Le déploiement de plusieurs réplicas pour ces services permet d’améliorer la scalabilité, la fiabilité et l’équilibrage de charge des charges de travail entre les réplicas disponibles.
Notes
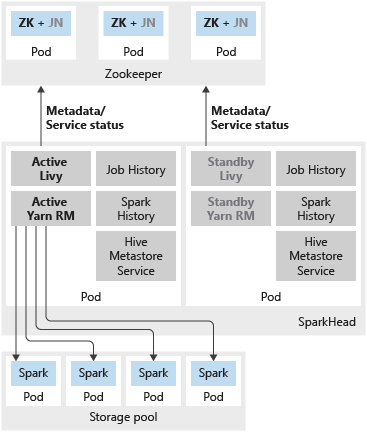
Les services suivants sont déployés en tant que conteneurs dans le pod sparkhead :
- Livy
- Gestionnaire de ressources Yarn
- Historique Spark
- Historique des travaux
- Service de métadonnées Hive
L’illustration suivante montre un déploiement de haute disponibilité Spark dans un cluster Big Data SQL Server :
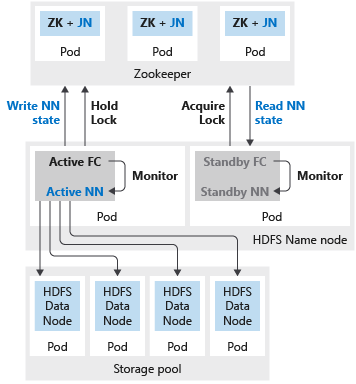
L’illustration suivante montre un déploiement de haute disponibilité HDFS dans un cluster Big Data SQL Server :
Déployer
Si un nœud de nom ou un en-tête Spark est configuré avec deux réplicas, vous devez également configurer la ressource Zookeeper avec trois réplicas. Dans une configuration à haut niveau de disponibilité pour le nœud de nom HDFS, deux pods hébergent les deux réplicas. Les pods sont nmnode-0 et nmnode-1. Cette configuration est active/passive. Un seul nœud de nom est actif à la fois. L’autre est en veille et devient actif à la suite d’un événement de basculement.
Vous pouvez utiliser les profils de configuration intégrés aks-dev-test-ha ou kubeadm-prod pour commencer à personnaliser votre déploiement de cluster Big Data. Ces profils incluent les paramètres requis pour les ressources ; vous pouvez configurer une haute disponibilité supplémentaire. Par exemple, vous trouverez ci-dessous une section dans le fichier config bdc.json qui s’applique au déploiement du nœud de nom HDFS, de Zookeeper et des ressources Spark partagées (sparkhead) avec une haute disponibilité.
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
En guise de bonne pratique, dans un déploiement de production, vous devez également configurer la réplication de blocs HDFS sur 3. Ce paramètre est déjà spécifié dans les profils aks-dev-test-ha et kubeadm-prod. Consultez la section ci-dessous du fichier de configuration bdc.json :
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
Limitations connues
Les problèmes connus et les limitations de la configuration de la haute disponibilité pour les services Hadoop dans les clusters Big Data SQL Server sont notamment les suivants :
- Toutes les configurations doivent être spécifiées au moment du déploiement de cluster Big Data. Avec la version SQL Server 2019 CU1, vous ne pouvez pas activer la configuration de haute disponibilité après le déploiement.
Étapes suivantes
- Pour plus d’informations sur l’utilisation de fichiers de configuration dans le déploiement de clusters Big Data, consultez Guide pratique pour déployer des Clusters Big Data SQL Server sur Kubernetes.
- Pour plus d’informations sur les options de haute disponibilité de l’instance maître SQL Server dans les clusters Big Data, consultez la rubrique Déployer l’instance maître SQL Server avec une haute disponibilité.
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour