Configurer un groupe de disponibilité distribué Always On
S'applique à : ![]() SQL Server
SQL Server
Pour créer un groupe de disponibilité distribué, vous devez créer deux groupes de disponibilité ayant chacun son propre écouteur. Vous combinez ensuite ces groupes de disponibilité dans un groupe de disponibilité distribué. Les étapes suivantes fournissent un exemple de base dans Transact-SQL. Cet exemple ne couvre pas tous les détails de la création des groupes de disponibilité et des écouteurs. Son but est de mettre en évidence les exigences principales.
Pour obtenir une présentation technique des groupes de disponibilité distribués, consultez Groupes de disponibilité distribués.
Prérequis
Pour configurer un groupe de disponibilité distribué, vous devez disposer des éléments suivants :
- Une version prise en charge de SQL Server
Remarque
Si vous avez configuré l’écouteur de votre groupe de disponibilité sur votre SQL Server sur une machine virtuelle Azure à l’aide d’un nom de réseau distribué (DNN), la configuration d’un groupe de disponibilité distribué au-dessus de votre groupe de disponibilité n’est pas prise en charge. Pour en savoir plus, consultez Interopérabilité de la fonctionnalité de SQL Server sur une machine virtuelle Azure avec un groupe de disponibilité et un écouteur DNN.
Définir les écouteurs de point de terminaison pour écouter toutes les adresses IP
Vérifiez que les points de terminaison peuvent communiquer entre les différents groupes de disponibilité du groupe de disponibilité distribué. Si un groupe de disponibilité est défini sur un réseau spécifique sur le point de terminaison, le groupe de disponibilité distribué ne fonctionne pas correctement. Sur chaque serveur qui héberge un réplica dans le groupe de disponibilité distribué, définissez l’écouteur pour qu’il écoute sur toutes les adresses IP (LISTENER_IP = ALL).
Créer un point de terminaison pour écouter toutes les adresses IP
Par exemple, le script suivant crée un point de terminaison d’écouteur sur le port TCP 5022 qui écoute sur toutes les adresses IP.
CREATE ENDPOINT [aodns-hadr]
STATE=STARTED
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL)
FOR DATA_MIRRORING (
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
)
GO
Modifier un point de terminaison pour écouter toutes les adresses IP
Par exemple, le script suivant modifie un point de terminaison d’écouteur pour qu’il écoute sur toutes les adresses IP.
ALTER ENDPOINT [aodns-hadr]
AS TCP (LISTENER_IP = ALL)
GO
Créer un premier groupe de disponibilité
Créer le groupe de disponibilité principal sur le premier cluster
Créer un groupe de disponibilité sur le premier cluster de basculement Windows Server (WSFC). Dans cet exemple, le groupe de disponibilité est nommé ag1 pour la base de données db1. Le réplica principal du groupe de disponibilité principal est appelé principal global dans un groupe de disponibilité distribué. Dans cet exemple, Server1 est le principal global.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Notes
L’exemple précédent utilise un amorçage automatique, où SEEDING_MODE a la valeur AUTOMATIC pour les réplicas et le groupe de disponibilité distribué. Cette configuration définit les réplicas secondaires et le groupe de disponibilité secondaire pour qu’ils soient renseignés automatiquement sans qu’une sauvegarde manuelle et une restauration de base de données primaire soient nécessaires.
Joindre les réplicas secondaires au groupe de disponibilité principal
Les réplicas secondaires doivent être joints au groupe de disponibilité ALTER AVAILABILITY GROUP avec l’option JOIN . Étant donné que l’amorçage automatique est utilisé dans cet exemple, vous devez également appeler ALTER AVAILABILITY GROUP avec l’option GRANT CREATE ANY DATABASE. Ainsi, le groupe de disponibilité peut créer la base de données et commencer l’amorçage automatique à partir du réplica principal.
Dans cet exemple, les commandes suivantes sont exécutées sur le réplica secondaire server2pour rejoindre le groupe de disponibilité ag1 . Le groupe de disponibilité est ensuite autorisé à créer des bases de données sur le réplica secondaire.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Notes
Quand le groupe de disponibilité crée une base de données sur un réplica secondaire, il définit le propriétaire de la base de données en tant que compte qui a exécuté l’instruction ALTER AVAILABILITY GROUP pour accorder l’autorisation de créer une base de données. Pour plus d’informations, consultez Octroyer l’autorisation de créer une base de données sur un réplica secondaire au groupe de disponibilité.
Créer un écouteur pour le groupe de disponibilité principal
Ajoutez ensuite un écouteur pour le groupe de disponibilité principal sur le premier cluster WSFC. Dans cet exemple, l’écouteur est nommé ag1-listener. Pour obtenir des instructions détaillées sur la création d’un écouteur, consultez Créer ou configurer un écouteur de groupe de disponibilité (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Créer un second groupe de disponibilité
Puis, sur le deuxième cluster WSFC, créez un deuxième groupe de disponibilité ag2. Dans ce cas, la base de données n’est pas spécifiée, car elle est amorcée automatiquement à partir du groupe de disponibilité principal. Le réplica principal du groupe de disponibilité secondaire est appelé redirecteur dans un groupe de disponibilité distribué. Dans cet exemple, server3 est le redirecteur.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Notes
Le groupe de disponibilité secondaire doit utiliser le même point de terminaison de mise en miroir de bases de données (le port 5022 dans l’exemple). Sinon, la réplication s’arrête après un basculement local.
Joindre les réplicas secondaires au groupe de disponibilité secondaire
Dans cet exemple, les commandes suivantes sont exécutées sur le réplica secondaire server4pour rejoindre le groupe de disponibilité ag2 . Le groupe de disponibilité est ensuite autorisé à créer des bases de données sur le réplica secondaire pour prendre en charge l’amorçage automatique.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Créer un écouteur pour le groupe de disponibilité secondaire
Ajoutez ensuite un écouteur au groupe de disponibilité secondaire sur le deuxième cluster WSFC. Dans cet exemple, l’écouteur est nommé ag2-listener. Pour obtenir des instructions détaillées sur la création d’un écouteur, consultez Créer ou configurer un écouteur de groupe de disponibilité (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Créer un groupe de disponibilité distribué sur le premier cluster
Sur le premier cluster WSFC, créez un groupe de disponibilité distribué (nommé distributedag dans cet exemple). Utilisez la commande CREATE AVAILABILITY GROUP avec l’option DISTRIBUTED . Le paramètre AVAILABILITY GROUP ON spécifie les groupes de disponibilité membres ag1 et ag2.
Pour créer votre groupe de disponibilité distribué à l’aide de l’amorçage automatique, utilisez le code Transact-SQL suivant :
CREATE AVAILABILITY GROUP [distributedag]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Notes
LISTENER_URL spécifie l’écouteur pour chaque groupe de disponibilité, ainsi que le point de terminaison de mise en miroir de bases de données du groupe de disponibilité. Dans cet exemple, il s’agit du port 5022 (et non du port 60173 qui a permis de créer l’écouteur). Si vous utilisez un équilibreur de charge, par exemple dans Azure, ajoutez une règle d’équilibrage de charge pour le port du groupe de disponibilité distribué. Ajoutez la règle pour le port d’écoute, en plus du port de l’instance SQL Server.
Annuler l’amorçage automatique du redirecteur
Si, pour une raison ou une autre, il est nécessaire d’annuler l’initialisation du redirecteur avant que les deux groupes de disponibilité soient synchronisés, modifiez le groupe de disponibilité distribué avec ALTER en définissant le paramètre SEEDING_MODE du redirecteur sur MANUAL et annulez immédiatement l’amorçage. Exécutez la commande sur la base de données primaire :
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedag]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Joindre un groupe de disponibilité distribué sur le second cluster
Joignez ensuite le groupe de disponibilité distribué au deuxième cluster WSFC.
Pour rejoindre votre groupe de disponibilité distribué à l’aide de l’amorçage automatique, utilisez le code Transact-SQL suivant :
ALTER AVAILABILITY GROUP [distributedag]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Joindre la base de données sur le réplica secondaire du deuxième groupe de disponibilité
Si le deuxième groupe de disponibilité a été configuré pour utiliser l’amorçage automatique, passez à l’étape 2.
- Si le deuxième groupe de disponibilité utilise l’amorçage manuel, restaurez la sauvegarde que vous avez effectuée sur le principal global sur le secondaire du deuxième groupe de disponibilité :
RESTORE DATABASE [db1]
FROM DISK = '<full backup location>' WITH NORECOVERY
RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY
- Quand la base de données qui se trouve sur le réplica secondaire du deuxième groupe de disponibilité est en restauration, vous devez la joindre manuellement au groupe de disponibilité.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Basculer un groupe de disponibilité distribué
Depuis que SQL Server 2022 (16.x) a introduit la prise en charge des groupes de disponibilité distribuée pour le paramètre REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, les instructions pour basculer sur une disponibilité distribuée sont différentes pour SQL Server 2022 et les versions ultérieures que pour SQL Server 2019 et les versions antérieures.
Pour un groupe de disponibilité distribué, le seul type de basculement pris en charge est un basculement manuel initié par l'utilisateur FORCE_FAILOVER_ALLOW_DATA_LOSS. Par conséquent, pour éviter toute perte de données, vous devez prendre des mesures supplémentaires (décrites en détail dans cette section) pour vous assurer que les données sont synchronisées entre les deux réplicas avant d'initier le basculement.
En cas d'urgence, lorsque la perte de données est acceptable, vous pouvez lancer un basculement sans assurer la synchronisation de données :
ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS
Vous pouvez utiliser la même commande pour basculer vers le redirecteur, ainsi que pour basculer vers le réplica principal global.
Sur SQL Server 2022 (16.x) et les versions ultérieures, vous pouvez configurer le paramètre REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT pour un groupe de disponibilité distribué, qui est conçu pour garantir la non perte de données en cas de défaillance d'un groupe de disponibilité distribué. Si ce paramètre est configuré, suivez les étapes de cette section pour basculer votre groupe de disponibilité distribué. Si vous ne souhaitez pas utiliser le paramètre REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, suivez les instructions pour basculer sur un groupe de disponibilité distribué dans SQL Server 2019 et les versions antérieures.
Pour éviter toute perte de données, veillez à :
- Arrêtez toutes les transactions sur les bases de données primaires globales (c’est-à-dire les bases de données du groupe de disponibilité principal)
- Définissez le groupe de disponibilité distribué sur la validation synchrone.
- Attendez que le groupe de disponibilité distribué soit synchronisé et présente le même last_hardened_lsn par base de données.
Une fois les données synchronisées, vous pouvez basculer le groupe de disponibilité distribué :
- Sur le réplica principal global, définissez le rôle du groupe de disponibilité distribué sur
SECONDARY, ce qui rend le groupe de disponibilité distribué indisponible. - Définissez le paramètre
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITdu groupe de disponibilité distribué sur 1 à l'aide de ALTER AVAILABILITY GROUP. - Testez la disponibilité du basculement.
- Basculez le groupe de disponibilité principal à l’aide de ALTER AVAILABILITY GROUP avec
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Définissez le paramètre du groupe de disponibilité distribué REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT sur 0.
Les exemples Transact-SQL suivants détaillent les étapes à effectuer pour basculer le groupe de disponibilité distribué nommé distributedag :
Pour éviter toute perte de donnée, arrêtez toutes les transactions sur les bases de données primaires globales (c’est-à-dire les bases de données du groupe de disponibilité principal). Puis, définissez le groupe de disponibilité distribué sur la validation synchrone en exécutant le code suivant sur à la fois le principal global et le redirecteur.
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedag] MODIFY AVAILABILITY GROUP ON 'ag1' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), 'ag2' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ); -- verifies the commit state of the distributed availability group select ag.name, ag.is_distributed, ar.replica_server_name, ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc, ars.operational_state_desc, ars.synchronization_health_desc from sys.availability_groups ag join sys.availability_replicas ar on ag.group_id=ar.group_id left join sys.dm_hadr_availability_replica_states ars on ars.replica_id=ar.replica_id where ag.is_distributed=1 GONotes
Dans un groupe de disponibilité distribué, l’état de synchronisation entre les deux groupes de disponibilité dépend du mode de disponibilité des deux réplicas. Pour le mode de validation synchrone, le groupe de disponibilité principal et le groupe de disponibilité secondaire doivent tous deux présenter le mode de disponibilité
SYNCHRONOUS_COMMIT. Pour cette raison, vous devez exécuter le script précédent à la fois sur le réplica principal global et sur le redirecteur.Attendez que l’état du groupe de disponibilité distribué devienne
SYNCHRONIZEDet que tous les réplicas présentent le même last_hardened_lsn (par base de données). Exécutez la requête suivante sur le principal global (qui est le réplica principal du groupe de disponibilité principal) et le redirecteur pour vérifier synchronization_state_desc et last_hardened_lsn :-- Run this query on the Global Primary and the forwarder -- Check the results to see if synchronization_state_desc is SYNCHRONIZED, and the last_hardened_lsn is the same per database on both the global primary and forwarder -- If not rerun the query on both side every 5 seconds until it is the case -- SELECT ag.name , drs.database_id , db_name(drs.database_id) as database_name , drs.group_id , drs.replica_id , drs.synchronization_state_desc , drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag on drs.group_id = ag.group_id;Continuez dès lors que le groupe de disponibilité synchronization_state_desc est
SYNCHRONIZEDet que le last_hardened_lsn est le même par base de données sur le principal global et le redirecteur. Si synchronization_state_desc n’est pasSYNCHRONIZEDou si le last_hardened_lsn n’est pas le même, exécutez la commande toutes les cinq secondes jusqu’à ce qu’ils changent. Continuez uniquement quand synchronization_state_desc =SYNCHRONIZEDet le last_hardened_lsn est le même par base de données.Sur le principal global, définissez le rôle du groupe de disponibilité distribué sur
SECONDARY.ALTER AVAILABILITY GROUP distributedag SET (ROLE = SECONDARY);À ce stade, le groupe de disponibilité distribué n’est pas disponible.
Pour SQL Server 2022 (16.x) et versions ultérieures, définissez REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.
ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Testez la disponibilité du basculement. Exécutez la requête suivante sur le principal global et le redirecteur :
-- Run this query on the Global Primary and the forwarder -- Check the results to see if the last_hardened_lsn is the same per database on both the global primary and forwarder -- The availability group is ready to fail over when the last_hardened_lsn is the same for both availability groups per database -- SELECT ag.name, drs.database_id, db_name(drs.database_id) as database_name, drs.group_id, drs.replica_id, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag ON drs.group_id = ag.group_id;Le groupe de disponibilité est prêt pour le basculement quand le last_hardened_lsn est le même pour les deux groupes de disponibilité par base de données. Si le last_hardened_lsn n’est pas le même au bout d’un certain temps, pour éviter toute perte de données, effectuez une restauration automatique sur le principal global en exécutant cette commande sur le principal global, puis recommencez à partir de la deuxième étape :
-- If the last_hardened_lsn is not the same after a period of time, to avoid data loss, -- we need to fail back to the global primary by running this command on the global primary -- and then start over from the second step: ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Basculez du groupe de disponibilité principal vers le groupe de disponibilité secondaire. Exécutez la commande suivante sur le redirecteur, le serveur SQL Server qui héberge le réplica principal du groupe de disponibilité secondaire.
-- Once the last_hardened_lsn is the same per database on both sides -- We can Fail over from the primary availability group to the secondary availability group. -- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Après cette étape, le groupe de disponibilité distribué est disponible.
Pour SQL Server 2022 (16.x) et les versions ultérieures, effacez le groupe de disponibilité distribué
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);
Après avoir effectué ces étapes, le groupe de disponibilité distribué bascule sans perte de données. Si les groupes de disponibilité sont à une distance géographique qui provoque des temps de latence, Microsoft vous recommande de définir le mode de disponibilité sur ASYNCHRONOUS_COMMIT.
Supprimer un groupe de disponibilité distribué
L’instruction Transact-SQL suivante supprime un groupe de disponibilité distribué nommé distributedag:
DROP AVAILABILITY GROUP [distributedag]
Créer un groupe de disponibilité distribué sur des instances de cluster de basculement
Vous pouvez créer un groupe de disponibilité distribué à l’aide d’un groupe de disponibilité sur une instance de cluster de basculement (FCI). Dans ce cas, vous n’avez pas besoin d’écouteur de groupe de disponibilité. Utilisez le nom de réseau virtuel pour le réplica principal de l’instance FCI. L’exemple suivant montre un groupe de disponibilité distribué appelé SQLFCIDAG. Un des groupes de disponibilité est SQLFCIAG. SQLFCIAG a deux réplicas FCI. Le VNN pour le réplica FCI principal est SQLFCIAG-1, et celui du réplica FCI secondaire est SQLFCIAG-2. Le groupe de disponibilité distribué inclut également SQLAG-DR pour la récupération d’urgence.
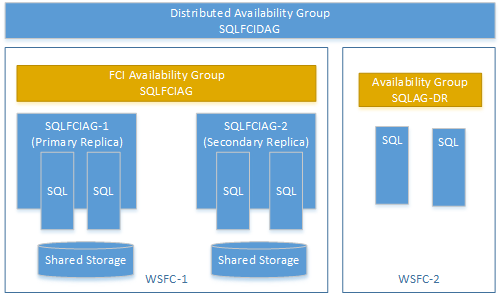
Le DDL suivant crée ce groupe de disponibilité distribué.
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
L’URL de l’écouteur est le VNN de l’instance FCI principale.
Basculer manuellement FCI dans le groupe de disponibilité distribué
Pour basculer manuellement le groupe de disponibilité FCI, mettez à jour le groupe de disponibilité distribué de façon à refléter la modification de l’URL de l’écouteur. Par exemple, exécutez la DDL suivante à la fois sur le principal global du groupe de disponibilité distribué et sur le redirecteur du groupe de disponibilité distribué de SQLFCIDAG :
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)
Étapes suivantes
CREATE AVAILABILITY GROUP (Transact-SQL)
ALTER AVAILABILITY GROUP (Transact-SQL)